Introducing Espresso - LinkedIn's hot new distributed document store
January 21, 2015
Espresso is LinkedIn's online, distributed, fault-tolerant NoSQL database that currently powers approximately 30 LinkedIn applications including Member Profile, InMail (LinkedIn's member-to-member messaging system), portions of the Homepage and mobile applications, etc. Espresso has a large production footprint at LinkedIn with over a dozen clusters in use. It hosts some of the most heavily accessed and valuable datasets at LinkedIn serving millions of records per second at peak. It is the source of truth for hundreds of terabytes (not counting replicas) of data.
Motivation
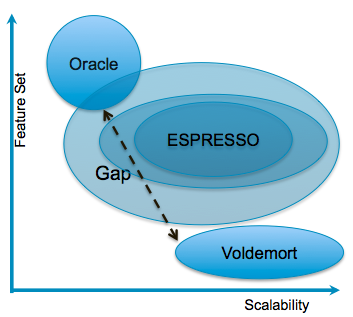
To meet the needs of online applications, LinkedIn traditionally used Relational Database Management Systems (RDBMSs) such as Oracle and key-value stores such as Voldemort - both serving different use cases. Much of LinkedIn requires a primary, strongly consistent, read/write data store that generates a timeline-consistent change capture stream to fulfill nearline and offline processing requirements. It has become apparent that many, if not most, of the primary data requirements of LinkedIn do not require the full functionality of monolithic RDBMSs, nor can they justify the associated costs.
Existing RDBMS solutions are painful for several reasons, including but not limited to:
Schema Evolution: Schema evolution in RDBMS's is accomplished by expensive alter-table statements and is extremely painful. Altering tables requires manual DBA intervention and blocks application teams from iterating quickly. Fast product iteration is essential for an internet company like LinkedIn.
Provisioning shards: Provisioning new shards is a lot of manual work and requires significant application specific configuration. All applications teams bear this burden.
Data Center Failover: LinkedIn's legacy RDBMSs operated in master/slave mode. Failover from one data center to another required coordination with DBA teams and generally required at least some downtime.
Cost: Legacy RDBMSs operate on expensive hardware and required expensive annual software licenses.
On the other hand, Voldemort is quite often used by applications that require key-value access but not a timeline consistent change-capture stream and other features provided by an RDBMS.
Requirements
In 2011, the Distributed Data Systems team identified the following important requirements based on our experiences with different systems:
- Elasticity: The ability to scale clusters horizontally by simply adding additional nodes
- Consistency:
- Support read-after write as well as eventually consistent reads
- Guaranteed secondary index consistency with base data
- Transactional updates within a single partition
- Distributed: The ability to distribute a single database across multiple nodes in a cluster. The number of partitions as well as the replication factor should be configurable per database
- Fault Tolerant: The system should continue to operate in the presence of individual machine failures with no operator intervention required.
- Secondary Indexing: Text and attribute search etc.
- Schema Evolution: Schema evolution should be supported with zero downtime and no coordination with DBA teams
- Change Capture Stream: Changes to the primary data store should be forwarded to downstream consumers via a change capture stream.
- Bulk Ingest: It should be possible to produce datasets offline (e.g. on HDFS via Hadoop) and import the data for online serving.
Data Model
Espresso provides a hierarchical data model. The hierarchy is database->table->collection->document. Conceptually, databases and tables are exactly the same as in any RDBMS. Let's examine the data model via examples. Database and table schemas are defined in JSON. Document schemas are defined in Avro.
Database
A database is a container for tables. All tables within a database are partitioned identically and share the same physical processing resources. Databases are defined by their schema.
A database schema contains important metadata about a database, including the database name, the version of the schema, the number of partitions (numBuckets) and the partitioning function to use when allocating documents to partitions. It is also used to define database traffic quotas e.g., read/write QPS, volume of data read/written etc.
Table
A table is a container of homogeneously typed documents. A single database can contain multiple tables. Every table schema defines a key-structure which can have multiple parts. The key-structure defines how documents are accessed. Every fully specified key is the primary key for a single document. The leading key in the table schema is also called the partitioning key. This key is used to determine which partition contains a given document. The entire key-space within a partition-key is hierarchical as illustrated in the following example.
This example table schema defines a 2-part key. MailboxID is the partitioning key and MessageID is the sub-key. Specifying both the keys is sufficient to uniquely identify any document within the "Messages" table. These table key parts are used to create an HTTP request to Espresso. The general form of an Espresso document URL is:
Collections
As mentioned before, the Espresso keyspace is hierarchical. Documents identified by a partially specified key are said to be a collection. For example, the URI /MailboxDB/Messages/100 identifies a collection of records within the same mailbox. Espresso guarantees transactional behavior for updates to multiple resources that share a common partition key if the updates are contained in a single HTTP request.
Document
A fully specified key uniquely identifies a single document. A document schema is an Avro schema. Internally Espresso stores documents as Avro serialized binary data blobs. The "indexType" attribute implies that a secondary index has to be built on that field.
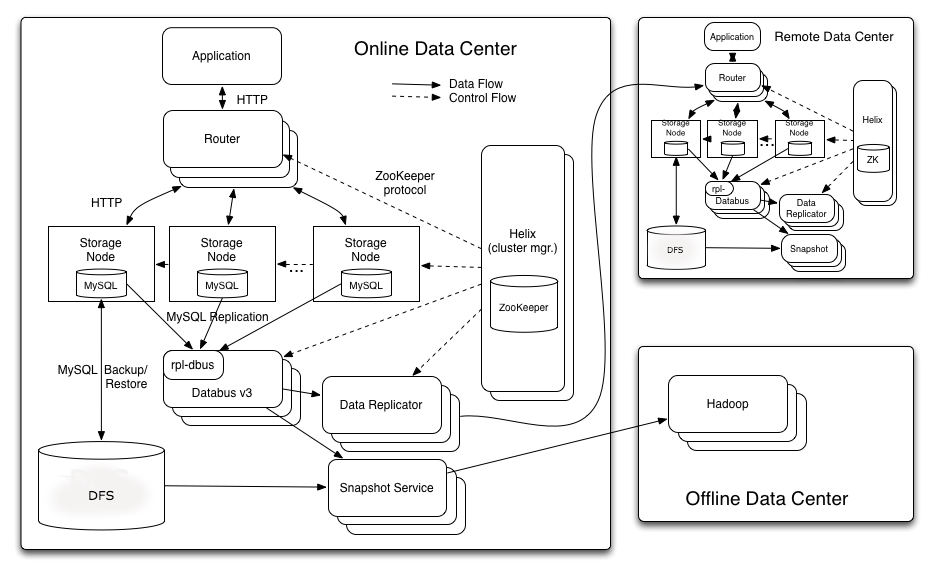
Architecture
The overall Espresso architecture can be summarized in this diagram. Let us look at each of these components.
Router
As the name suggests, the router is a stateless HTTP proxy. This is the entry point for all client requests into Espresso. It examines the URL to determine the database, hashes the partition key to determine the partition required to serve the request and forwards the request to the corresponding storage node. The router has a locally cached routing table that reflects the distribution of partitions among all the storage nodes within the cluster for all databases. This routing table is updated upon any state changes within the cluster via ZooKeeper. The router supports multi-gets across multiple partitions. It scatter-gathers the requests to multiple storage nodes in parallel and sends the merged response back to the client.
Espresso currently uses Hash based partitioning for all our existing databases except for the internal schema registry database which can be routed to any node.
Storage Node
The Storage Nodes are the fundamental blocks for scaling out processing and storage. Each Storage Node hosts a set of partitions. Based on the distribution of partitions, the routers send requests to storage nodes. Some of the storage node functions are:
- Query Processing
- Store and serve primary data as Avro serialized documents.
- Host metadata information about each document including checksum, last modified timestamp, schema version, internal flags etc.
- Storage Engine - The Storage nodes are designed to have a pluggable storage engine. All current production deployments use MySQL as the storage engine.
- The MySQL instances use the InnoDB storage engine.
- Along with Storage, MySQL binary logs are used to provide replication within a cluster and also provide a feed for the change capture stream (databus) to consume.
- Secondary Indexes
- Maintain secondary indexes as defined within the document schema. These indexes are updated synchronously with any update to the base data. This ensures that the indexes are always in sync and never return stale copies of the data for query-after-write use cases.
- The Indexes can be stored with different granularity options i.e., per-partition, per-collection etc..
- Handling State Transitions - Helix generates transitions whenever there is a reassignment of partitions. This can occur for a variety of reasons e.g, master failure, scheduled maintenance. This is discussed in more detail in the fault tolerance section.
- Local Transactional Support - The Storage nodes are responsible for enforcing transactionality. This is the reason we do not allow cross-collection transactions since they may reside in different partitions which in turn may reside on different storage nodes.
- Replication Commit Log - The Storage Nodes are also responsible for providing an ordered commit log of all transactions which can be consumed by databus and by slave copies of partitions within a cluster.
- Utility functions like consistency checking and data validation.
- Scheduled Backups - Take periodic backups of data being hosted locally.
Helix
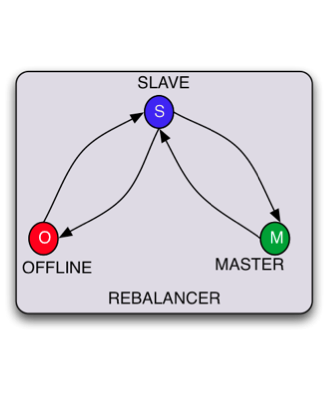
Cluster management in Espresso is done using Apache Helix . Given a state model definition along with some constraints, Helix computes an "IdealState" which is an ideal distribution of database partititons within a cluster. Helix compares the generated IdealState with the current state of the cluster, called the "ExternalView", and issues the state transitions required to move from the current ExternalView to the IdealState. Since every storage node is registered with Helix, the system is able to detect and fix failures rapidly.
The Espresso state model has the following states with these constraints for each partition :
- Every partition must have only 1 master. Every partition can have up to 'n' configurable slaves.
- Partitions are distributed evenly across all storage nodes.
- No replicas of the same partition may be present on the same node.
- Upon master failover, one of the slaves must be promoted to master.
For more information, please visit the Apache Helix website.
Databus
Espresso uses Databus as the change capture mechanism to transport source transactions in commit order. Databus is able to achieve high throughput and low replication latencies. It consumes transaction logs from Espresso to provide a change stream. For more information, please read the Databus blog post.
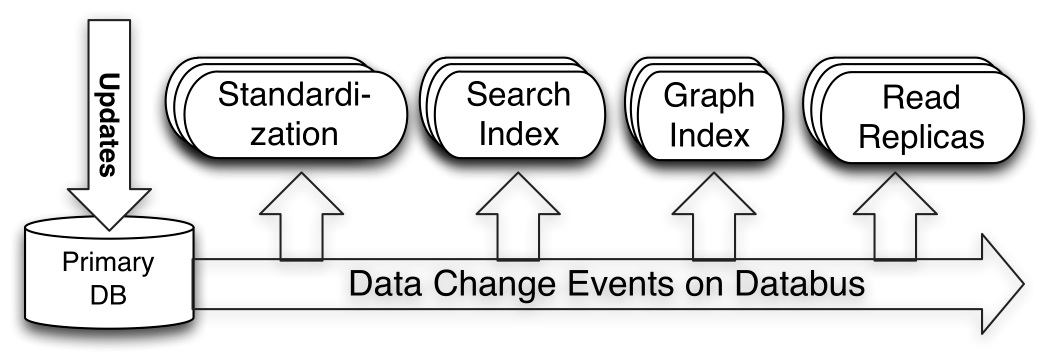
Databus is used for several purposes by Espresso:
- Deliver events to downstream consumers i.e., search indexes, caches etc..
- Espresso multi datacenter replication - each locally originated write is forwarded on to remote data centers. This is discussed in more detail in the data replicator section.
Data Replicator
Data replicator is a service that forwards commits between geo-replicated Espresso clusters. It is basically a Databus consumer that consumes events for each database partition within a cluster. This service performs per-partition batching of events in order to improve throughput across high latency links between datacenters.
The Data Replicator service contains a clustered set of stateless instances managed by Helix. The Databus consumers periodically checkpoint their replication progress in ZooKeeper. The checkpoints survive node failures, service restarts etc.
The service itself is fault tolerant. Each node is responsible for replicating a certain set of partitions assigned to it by Helix. Upon node failure, the partitions assigned to the failed node are redistributed evenly among the remaining nodes. When a node starts processing a new partition assignment, it starts replaying transactions from the most recent checkpoint the failed node stored in ZooKeeper. In Helix terms, the service has an Online-Offline Helix state model.
Snapshot Service
For a majority of Espresso users, automatic ETL to HDFS is a strong requirement. As a result, we need a mechanism to publish all the Espresso data to HDFS with minimal impact to the serving cluster. Any solution also has to integrate well with LinkedIn's existing data pipelines. The snapshot service has been written to address these requirements.
Espresso takes periodic backups of it's data which get written to shared storage accessible to all Espresso nodes within a data center. Metadata information about recent backups is also written to ZooKeeper. The snapshot service sets a watch on the znodes where the metadata is published. Upon notification of a new backup, the snapshot service restores the backup locally and produces separate Avro files corresponding to each table in a database. This data is then available for a "puller" service to load into HDFS. This also has the added benefit of verifying our backup images as soon as they are generated.
In addition to HDFS ETL, there are several other derived views of the data produced by the snapshot service. An example is the Databus Bootstrap file. Databus only retains a fixed size buffer of events in memory. Any consumer that is new or has been down for an extended period of time will not be able to consume from databus since it will have missed events. The Avro files produced by this service can be used to bootstrap a databus consumer i.e., to provide it with an accurate view of all the data since any time 'X'.
The snapshot service itself is a distributed system with the same Online-Oflline state model as the data replicator.
API
Espresso provides an HTTP based RESTful API which is simple and easy-to-use.
Write API
HTTP PUT is used to insert data into a table. The following will create a document with the content location "/MailboxDB/Messages/100/1".
If a document already exists at the specified URL, the document will overwritten in its entirety.
PUT can also be used to perform a transactional insert of multiple documents into a collection ("Mailbox" in our example). Each document is represented as a part in a multipart MIME message.
If any document fails to persist, or a conditional failure occurs (described later), the transaction is rolled back.
HTTP POST provides partial-updates to existing documents or updating a collection by inserting documents into the collection and generating an autoincrement trailing key as described below. As with PUT, POST is also transactional.
If the last key part in a table schema is numeric and is annotated with the "autoincrement" attribute, that key part can be omitted when using POST to insert a document into the corresponding collection. Espresso will generate the key part at the time of the POST, and return the URL of the inserted document in a Content-Location response header.
Document deletion is performed with an HTTP DELETE method applied to the document's URL.
Read API
HTTP GET is used for retrieval of documents. It can retrieve single documents, entire collections or even documents spanning multiple collections. If multiple documents are returned from a single HTTP GET operation, they are encoded as parts of a multi-part MIME message. In case of multi-gets spanning different collections, the actual documents may reside on different storage nodes.
Conditional Operations
Espresso also supports HTTP compliant conditional operations based on Last-Modified and ETag. This allows clients to implement read-modify-write operations and retain cached copies of documents.
Key Features and Implementation details
Sequence Number - Espresso's clock
Espresso uses an internal clock for ordering of events. Timeline ordering is extremely important for inter-cluster replication, databus etc. Each successful mutation (insert, update or delete) is assigned a 64 bit system change number (SCN). This number is monotonically increasing and is maintained separately per partition i.e., every partition maintains its own SCN. An SCN has 2 parts, a generation (higher 32 bits) and a sequence (lower 32 bits). Every committed transaction increments the sequence by 1. Every mastership transition increments the generation by 1 and resets the sequence. Events committed as part of the same transaction will share the same SCN. The SCN is currently generated by MySQL when the transaction is committed.
Consider this example. Let N1 and N2 be 2 nodes hosting partition 0 (P0) as MASTER and SLAVE respectively. To begin with, the SCN for P0 is (1, 1) i.e., generation 1 and sequence 1. If node N1 receives 3 writes, the SCN will be (1, 4). At this point, assume that N1 undergoes a failure and N2 assumes mastership. N2 sees that the current SCN is (1, 4) and changes the SCN to (2, 1). This process is repeated whenever mastership for a partition is reassigned from one node to another. SCNs must be managed per partition rather than per MySQL instance because partitions are not necessarily tied to a specific MySQL instance. During an expansion, partitions will move between nodes.
Schema Management
Espresso Schemas are stored in ZooKeeper. This component is shared among all services in Espresso. The schemata is modeled as an Espresso database. Here's how we fetch the db, table and document schemas for our example MailboxDB:
Schema Evolution
Espresso Document schemas can be evolved according to Avro schema evolution rules, along with some Espresso specific restrictions. Backward incompatible schema changes are permitted but discouraged.
Let us evolve the Messages document schema shown above. We want to add a "senderName" field to the schema. All new records will be serialized using the latest schema version unless specified otherwise per-request.
Since the new "senderName" field is optional, existing documents encoded with version 1 of the schema can be promoted to version 2.
Fault Tolerance
As discussed, cluster management in Espresso is done using Apache Helix. Since the Storage Nodes are the source of truth for data, fault tolerance is critical. Within Espresso, each node can have both slave and master partitions. The failover process is:
- When a Storage Node connects to Helix it creates an ephemeral node in ZooKeeper that is watched by Helix.
- When a node fails (closes the socket connection or fails to respond to heartbeats), ZooKeeper removes the ephemeral node.
- Upon detecting a node failure, Helix updates the external view to exclude the failed node.
- Once ideal state is generated, Helix generates state transitions according to the defined state model. In Espresso's case, one of the slaves for each affected partition receives SLAVE->MASTER transitions.
During this entire process, there is a small window of write unavailability. When a partition is not mastered, no writes can succeed. However, we should always have at least 1 slave copy. As a result, the router can detect this and route read requests to SLAVE partitions to ensure partial availability.
Example:
1) Assume we have 4 storage nodes, a 12 partition database configured to have 2 replicas (1 Master and 1 Slave). In steady state, each of the nodes is master for 3 partitions and slave for 3.
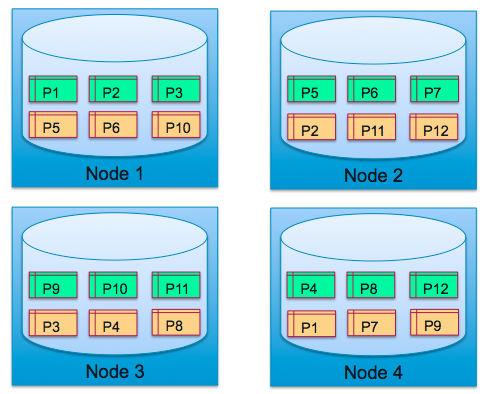
2) Now assume, Node 3 suffers a failure. Partitions 9, 10 and 11 do not have a master.
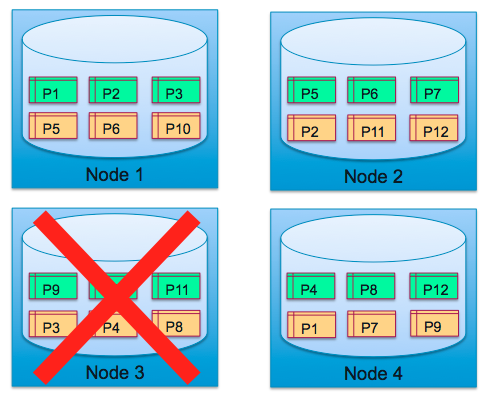
3) The replica for each of those failed partitions has completed a mastership transition.
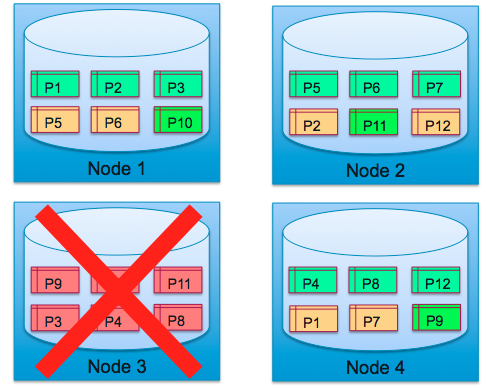
Backup Restore
Espresso Storage nodes are capable of taking periodic backups of all partitions they host. The storage nodes stream these compressed backup images to a distributed file system. Backups are produced on a per-partition basis since partitions can move across nodes during expansion. Each backup contains the SCN number of the partition at the time the backup was taken. These backups can be used to restore failed nodes, bootstrap new clusters, expand existing clusters etc.. After restoring a backup, the restored instance will "catchup" on all updates after the SCN the backup was taken at.
Miscellaneous
There are plenty of interesting features to discuss in greater detail in future blog posts e.g., cluster expansion, per-database quota management, bulk load from HDFS, automatically materialized aggregates, group commit, conflict resolution etc. Look for future blog posts on Espresso and its adoption within LinkedIn.
Acknowledgements
Espresso is under active development in the Distributed Data Systems team and there is a large backlog of challenging projects in the pipeline. We would like to thank all the development and operations engineers that have contributed to Espresso over the years. Espresso also leverages many open source technologies developed at LinkedIn i.e., R2D2, Databus, Helix. We would like to acknowledge those teams also.
Special thanks to Mammad Zadeh, Greg Arnold and Alex Vauthey from the management team for their support.