Open Sourcing Cubert: A High Performance Computation Engine for Complex Big Data Analytics
November 11, 2014
What do you do when your Hadoop ETL script is mercilessly killed because it is hogging too many resources on the cluster, or if it starts missing completion deadlines by hours?
We encountered this exact same problem more than a year ago while building the computation pipeline for XLNT, LinkedIn’s A/B testing platform. After wasting several months on optimization and tuning possibilities with Pig and Hive and still not meeting completion deadlines, we realized the problem needed an entirely new set of algorithms. Written completely in Java and built using several novel primitives, the new system proved effective in handling joins and aggregations on hefty datasets which allowed us to successfully launch XLNT.
However, we soon became victims of our own success. We were faced with extended requirements as well as new use cases from other domains of data analytics. Adding to the challenge was maintaining the Java code and in some cases, rewriting large portions to accommodate various applications.
This experience fit the pattern we have seen for our complex analytics computations. First, you tweak the script and tune the parameters. And when that fails, there is no other option but to roll up your sleeves and write some low-level Map Reduce code. From there the struggle continues, as the code has to be maintained and extended.
Our solution is an extensible and customizable framework, Cubert, that delivers all the efficiency advantages of a hand-crafted Java program yet provides the simplicity of a script-like user interface to solve a variety of statistical, analytical and graph problems, without exposing analysts and data scientists to low level details.
We recently decided to open source Cubert to help out fellow data analysts in the community who are struggling with similar problems.
The Cubert name owes its origin to our fascination with the Rubik’s Cube. Just as the blocks are moved about - in smart ways - to solve the complex Rubiks cube puzzle, we found the analogy in moving data blocks, again in smart ways, to solve complex analytics problems. The name is also fitting, as the CUBE operator is one of the most distinguished and prominent technological innovations in Cubert.
About Cubert

Cubert was built with the primary focus on better algorithms that can maximize map-side aggregations, minimize intermediate data, partition work in balanced chunks based on cost-functions, and ensure that the operators scan data that is resident in memory. Cubert has introduced a new paradigm of computation that:
- organizes data in a format that is ideally suited for scalable execution of subsequent query processing operators
- provides a suite of specialized operators (such as MeshJoin, Cube, Pivot) using algorithms that exploit the organization to provide significantly improved CPU and resource utilization
Cubert was shown to outperform other engines by a factor of 5-60X even when the data set sizes extend into 10s of TB and cannot fit into main memory.
The Cubert operators and algorithms were developed to specifically address real-life big data analytics needs:
- Complex Joins and aggregations frequently arise in the context of analytics on various user level metrics which are gathered on a daily basis from a user facing website. Cubert provides the unique MeshJoin algorithm that can process data sets running into terabytes over large time windows.
- Reporting workflows are distinct from ad-hoc queries by virtue of the fact that the computation pattern is regular and repetitive, allowing for efficiency gains from partial result caching and incremental processing, a feature exploited by the Cubert runtime for significantly improved efficiency and resource footprint.
- Cubert provides the new power-horse CUBE operator that can efficiently (CPU and memory) compute additive, non-additive (e.g. Count Distinct) and exact percentile rank (e.g. Median) statistics; can roll up inner dimensions on-the-fly and compute multiple measures within a single job.
- Cubert provides novel algorithms for graph traversal and aggregations for large-scale graph analytics.
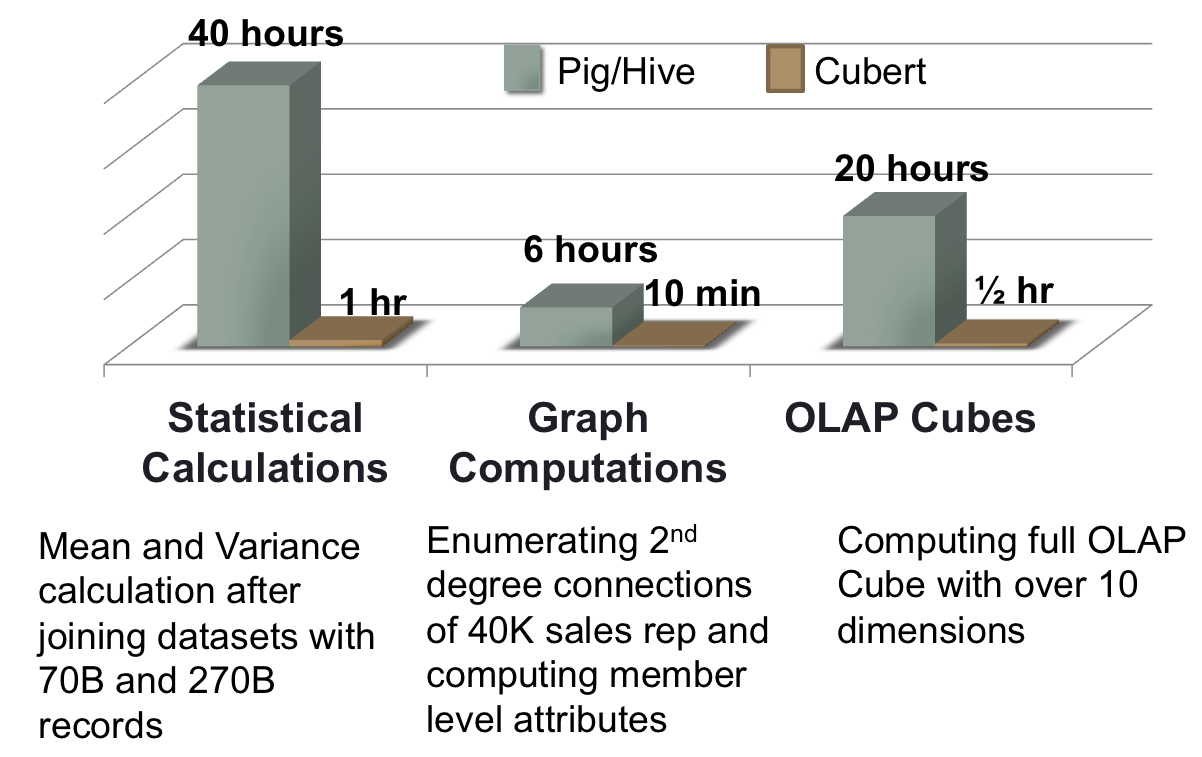 Cubert @LinkedIn
Cubert @LinkedInCubert Design
The adjacent figure illustrates the three primary layers involved in big data computation. Extant engines such as Apache Pig, Hive and Shark (orange blocks) provide a logical declarative language that is translated into a physical plan. This plan is executed on the distributed engine (Map-Reduce, Tez or Spark), where the physical operators are executed against the data partitions. Finally, the data partitions are managed via the file system abstractions provided by HDFS. 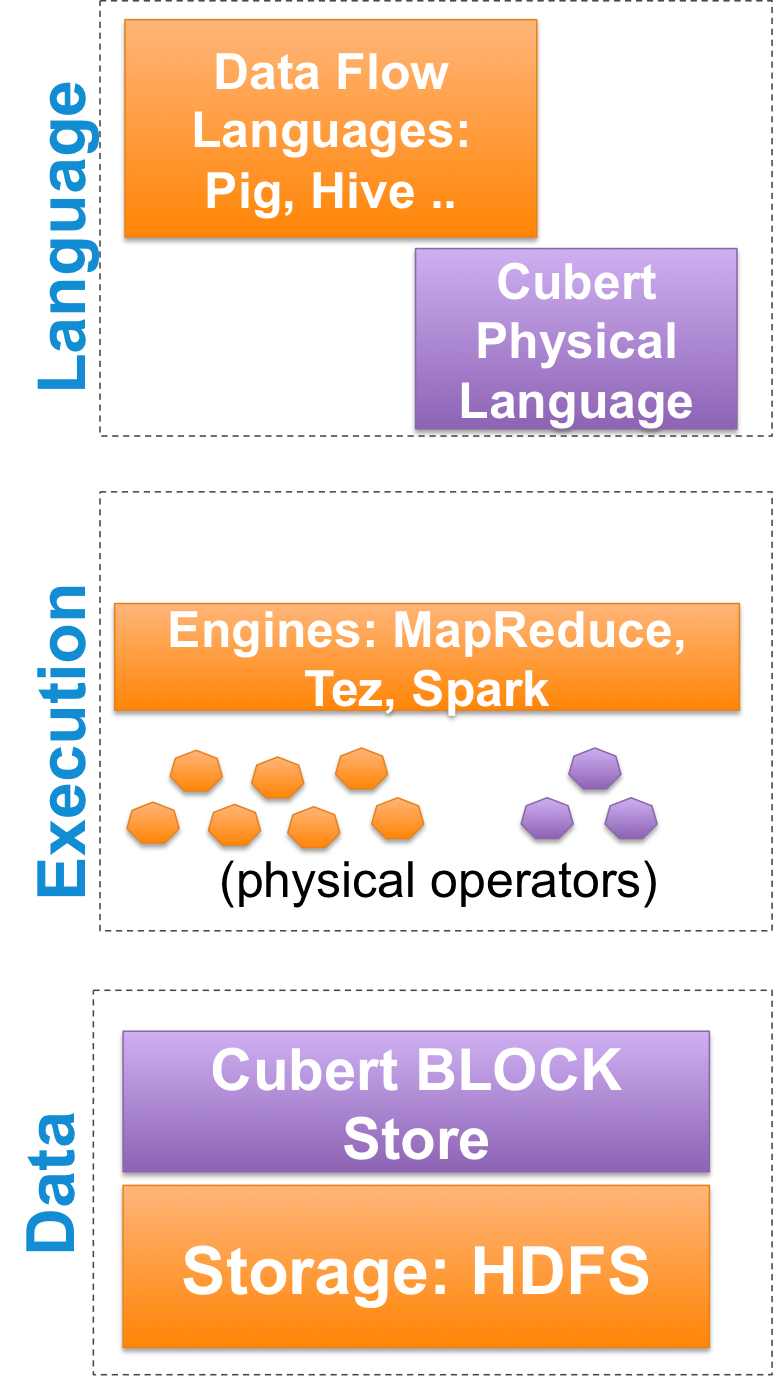
Cubert has extended this structure with new abstractions in language, operators and storage (purple blocks).
To the users, Cubert provides a scripting language and runtime to execute plans specified as a flow of operators. This is a physical language, that is, users can write MR programs as scripts (without writing java!). The next section discusses the Cubert script.
Within the execution layer, Cubert provides a suite of new operators (not available in other platforms) in addition to supporting the standard operators (such as SELECT, FILTER, LIMIT and so on). Few of the new operators are listed below:
- Data movement operators: SHUFFLE (standard Hadoop shuffle), BLOCKGEN (create partitioned data units), COMBINE (combine two or more blocks), PIVOT (create sub-blocks out of a block, based on specified partitioning scheme).
- Aggregation operators: CUBE
- Analytical windows operators: TOPN, RANK (full compatibility with SQL window operators is planned for future release)
- Dictionary operators to encode and decode strings as integers.
For the new operators and algorithms to work correctly, the data must be available in a specific format called blocks. Blocks are partitions of data based on some cost function, are internally sorted and can be retrieved by their identifiers. Cubert provides a storage abstraction on top of HDFS to manage these blocks.
A flavor of Cubert Script
The following script illustrates the structure of a typical job in a Cubert script, using counting words in a document as the example
The job starts with a Map phase that loads the input data and applies operators (GENERATE in this case). The data is then shuffled, with optional invocation of the combiners. The shuffled data is processed by the operators in the reducers (GROUP BY in the example) and subsequently stored in HDFS. In addition to the standard SHUFFLE, Cubert also provides other data movement operators such as BLOCKGEN and CUBE.
Note that the above script is actually not the idiomatic way to count words. The proper approach would be to use the CUBE operator (see example below), which is not only a more compact script but also would run faster. Secondly, even though the script is written as a Map Reduce job, it can actually run on non-MR engines. We are currently working on supporting Tez and Spark as the underlying execution engine, as well as extending the script to represent non-MR logic.
Let us now look at a more real life example. Consider a fact table of website user click events table:
We would like to load one week of data and build a OLAP cube over country and locale as dimensions for unique users over the week, unique users for today, as well as total number of clicks. The following script illustrates how the computation can be accomplished in two jobs only:
The first job organizes the input data into blocks which are generated using a cost function (number of rows in blocks = 1M). The second job adds a new column for those records that occurred today. Finally, the CUBE command creates the three cubes in a single job!
The Data Analytics Pipeline
The figure below illustrates a portion of the data analytics pipeline at LinkedIn. The various data sources publish data using Kafka, a high-throughput distributed messaging system. The Kafka “streams” are ingested into the Hadoop grid, where Cubert processes the data for a variety of statistical, analytical and graph computation problems. The computed results are pushed out of hadoop grid into Pinot - LinkedIn’s distributed real-time analytics infrastructure.

Next Play
Currently, Cubert can natively import Pig UDFs; we plan on supporting the UDFs as well as Storage layers from both Pig and Hive.We are working on supporting Apache Tez and Spark as the underlying execution engine for Cubert.
Our plans to extend the language include supporting logical layer primitives, supporting analytical window functions and automatically translating the scripts to support incremental computations.
Cubert source code and documentation
The source code is open sourced under Apache v2 License and is available at https://github.com/linkedin/Cubert
The documentation, user guide and javadoc are available at http://linkedin.github.io/Cubert
The abstractions for data organization and calculations were present in the following paper:
“Execution Primitives for Scalable Joins and Aggregations in Map Reduce”, Srinivas Vemuri, Maneesh Varshney, Krishna Puttaswamy, Rui Liu. 40th International Conference on Very Large Data Bases (VLDB), Hangzhou, China, Sept 2014. (PDF)