How We’re Improving and Advancing Kafka at LinkedIn
September 2, 2015
Kafka continues to be one of the key pillars in LinkedIn’s data infrastructure. One of our engineers has described it as LinkedIn’s "circulatory system" for data, enabling us to have a loosely connected set of services which all operate together. We’ve written at length about the Kafka ecosystem at LinkedIn: how we’re running it at scale, how it fits in with LinkedIn’s open sourcing strategy, and how it fits in with our overall technology stack. Today, we’re going to talk about how we’re improving it so it continues to grow along with the rest of the company and keep delivering the data that’s LinkedIn’s lifeblood.
We started using Kafka in production at large scale in July 2011 and at that point processed about 1 billion messages per day. This ticked up to 20 billion messages per day in 2012. In July 2013 we were processing about 200 billion messages per day through Kafka. A few months ago, we hit a new level of scale with Kafka. We now use it to process more than 1 trillion published messages per day with peaks of 4.5 million messages published per second – that equals about 1.34 PB of information per week. Each message gets consumed by about four applications on average.
In total, that's a 1,200x growth in four years. I would like to note that these numbers don’t directly correlate to increases in site traffic. Also these numbers do go up and down as applications at LinkedIn become more smarter in how much data they have to pump through Kafka.
It’s also worth noting that Kafka is not just scaling up at LinkedIn. Currently around 100 other companies, including Yahoo!, Twitter, Netflix, Uber and Goldman Sachs use Kafka to power everything from analytics to stream processing and dozens of other uses.
As we continue to scale Kafka at LinkedIn it is more important than ever to focus on improving reliability, costs, security, availability and other basics. In this piece I will discuss some of the key features/areas that our team of ~7 developers and ~4 Site Reliability Engineers (SREs) have been focussed on over the last year and how we think it will help sustain the scale of Kafka usage at LinkedIn and hopefully benefit Kafka users worldwide.
Some very legitimate scenarios can also have a pretty bad impact. For example, there are occasions where applications have to reprocess an entire database. In this situation all the records in the database get pushed into Kafka as fast as possible. Kafka being as performant as it is, it makes it super-easy to saturate the network and flood the disks.
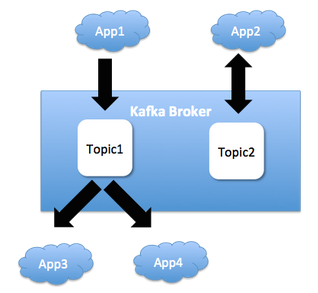
The following picture depicts how different applications share the same Kafka Broker.
 To fix this we worked on a feature to slow down producers and consumers if they exceed a threshold of bytes/sec. In any such system the default thresholds would work for the vast majority of applications. However, there are always some top users which need more bandwidth. This is especially a problem for a company like LinkedIn when there are already a ton of existing applications. So it was important that we allow whitelisting certain users so that they can continue consuming a higher amount of bandwidth. In addition, it is critical that such changes in configuration should be done without having to do a rolling bounce of the Kafka Brokers.
To fix this we worked on a feature to slow down producers and consumers if they exceed a threshold of bytes/sec. In any such system the default thresholds would work for the vast majority of applications. However, there are always some top users which need more bandwidth. This is especially a problem for a company like LinkedIn when there are already a ton of existing applications. So it was important that we allow whitelisting certain users so that they can continue consuming a higher amount of bandwidth. In addition, it is critical that such changes in configuration should be done without having to do a rolling bounce of the Kafka Brokers.
We are happy that this work has gone very well and should be there for everyone to use in the next release of Kafka.
Currently Kafka has two different types of consumers. A low level consumer which is used when a consumer wants full control on which partitions of a topic to consume from and a high level consumer where the kafka client automatically figures out how to distribute topic partitions amongst consumer instances. The issue is that if someone has to use the low level consumer then it is almost like falling off a cliff. In essence the user has to take care of extremely basic error handling, retries and cannot benefit from some of the other features that are available in the high level consumer like offset checkpointing. In the new consumer the low level and high level consumer have been reconciled.
In addition to monitoring production systems, it will also be used for validating a new Kafka build that we might pick from the open source trunk to deploy to our production clusters. This will also help us ensure that new versions of the kafka broker don’t break existing older clients.
We believe that everyone running Kafka at scale would benefit from this.
In addition to the above scenario, Kafka will also be used for asynchronously uploading data into Venice which is a new store for serving derived data at LinkedIn.
At LinkedIn we use Apache Samza for all our real time stream processing needs. Kafka is a key source of events for most of our stream processing applications. Samza’s solid performance characteristics allow our stream processing applications to keep up with the staggering growth of ingested events. In addition to using Kafka as a source of events, Samza also uses Kafka as a durable store to backup application state. In essence, Samza stores the stream processor’s state in an embedded local disk based store. To allow the stream processor to recover its state in the event of a local disk failure, Samza automatically backs up the data into a log-compacted topic in Kafka. In the last year, we fixed critical bugs and made key improvements in Kafka’s log compaction feature to make Samza based applications more robust.
This effort allows us to continually evaluate if the overall Kafka usage for various applications is appropriate. We hope to decrease overall usage and hence costs as a result of this.
We hope to open source several of these aspects of LinkedIn’s Kafka ecosystem over the next year as we believe that many of these problems are generic enough that other companies can leverage from these.
We started using Kafka in production at large scale in July 2011 and at that point processed about 1 billion messages per day. This ticked up to 20 billion messages per day in 2012. In July 2013 we were processing about 200 billion messages per day through Kafka. A few months ago, we hit a new level of scale with Kafka. We now use it to process more than 1 trillion published messages per day with peaks of 4.5 million messages published per second – that equals about 1.34 PB of information per week. Each message gets consumed by about four applications on average.
In total, that's a 1,200x growth in four years. I would like to note that these numbers don’t directly correlate to increases in site traffic. Also these numbers do go up and down as applications at LinkedIn become more smarter in how much data they have to pump through Kafka.
It’s also worth noting that Kafka is not just scaling up at LinkedIn. Currently around 100 other companies, including Yahoo!, Twitter, Netflix, Uber and Goldman Sachs use Kafka to power everything from analytics to stream processing and dozens of other uses.
As we continue to scale Kafka at LinkedIn it is more important than ever to focus on improving reliability, costs, security, availability and other basics. In this piece I will discuss some of the key features/areas that our team of ~7 developers and ~4 Site Reliability Engineers (SREs) have been focussed on over the last year and how we think it will help sustain the scale of Kafka usage at LinkedIn and hopefully benefit Kafka users worldwide.
Key Focus areas
Quotas
Different applications at LinkedIn share the Kafka clusters. So if one application starts abusing Kafka, it can have an adverse impact on the performance and SLAs for other applications that share the cluster.Some very legitimate scenarios can also have a pretty bad impact. For example, there are occasions where applications have to reprocess an entire database. In this situation all the records in the database get pushed into Kafka as fast as possible. Kafka being as performant as it is, it makes it super-easy to saturate the network and flood the disks.
The following picture depicts how different applications share the same Kafka Broker.
We are happy that this work has gone very well and should be there for everyone to use in the next release of Kafka.
New consumer development
The existing Kafka consumer client depends on ZooKeeper. There are some known issues with this dependency ranging from the lack of security in how Zookeeper is used to the possibility of a split brain condition among the consumer instances. We have been collaborating with Confluent and others in the open source community to build a new consumer to address these issues. This new consumer would only depend on the Kafka broker and will not have any ZooKeeper dependency. Kafka broker will however continue to have a dependency on ZooKeeper. As you can imagine, this is a complex feature and hence it will take a fairly long time for us to fully leverage this in production.Currently Kafka has two different types of consumers. A low level consumer which is used when a consumer wants full control on which partitions of a topic to consume from and a high level consumer where the kafka client automatically figures out how to distribute topic partitions amongst consumer instances. The issue is that if someone has to use the low level consumer then it is almost like falling off a cliff. In essence the user has to take care of extremely basic error handling, retries and cannot benefit from some of the other features that are available in the high level consumer like offset checkpointing. In the new consumer the low level and high level consumer have been reconciled.
Reliability and Availability Improvements
At LinkedIn’s scale, any major bugs and issues in a new build of Kafka get exposed fairly easily and can potentially have a big impact on reliability. So a critical part of work we do is in finding and fixing bugs and sometimes major design issues that are exposed in our testing and production usage. Here are some of the bigger reliability improvements we developed that will be available in the next major release of Kafka.- Lossless data transfer with Mirror Maker: Mirror Maker is a component in Kafka which helps move data between Kafka clusters and Kafka topics. This is used extensively at LinkedIn to create various data flows within and across our datacenters. The initial design for this had a flaw due to which it was possible to lose messages during transfer especially during a cluster upgrade or machine reboots. To guarantee that all messages would be transferred we changed the design to ensure that an event is considered to be fully consumed only after the event is successfully delivered to the destination topic/s.
- Replica Lag Tuning: Every message that is published to a Kafka broker is replicated for improving durability. A replica is considered to be unhealthy if it is not "caught up" with the master. The definition for “caught up” was based on a configured number of bytes of lag. The issue here was that if a big message or a huge spike of messages was published into Kafka, the lag would spike and now the the system would consider the replicas to be unhealthy. To fix this we have changed replica lag calculation to be based on time.
- Operationalizing the new producer: More than a year and half ago we implemented a new producer for Kafka. Among many other cool capabilities, the new producer allowed messages to be pipelined to improve performance. Turns out that making a core thing like the new producer production ready for LinkedIn scale is not easy. Exceptional situations like machine death and network failures are no longer very exceptional when there are so many machines involved. Needless to say we have discovered several issues and have been steadily fixing them. We expect to roll it out completely at LinkedIn pretty soon.
- Delete Topic: For a product as mature as Kafka, it might feel a bit surprising to learn that up until a few months ago, deleting a topic could cause a bunch of unintended consequences and cluster instability. We have done extensive testing now and fixed a bunch of nasty issues over the last few months. By the next major release of Kafka, it should be safe to delete a topic.
Security
This has been one of the most anticipated feature in Kafka. There are many companies (e.g. Hortonworks, Cloudera, LinkedIn, Confluent) who have been collaborating together to help address this major gap. As a result of this work, encryption, authentication and authorization will be added to Kafka. We hope to operationalize encryption at LinkedIn in 2015 and the other security features in 2016.Kafka Monitoring Framework
We have recently started working on this effort to have a standardized way to monitor our Kafka clusters. The idea here is to run a set of test applications which are producing and consuming data into kafka topics and validating the basic guarantees (order, guaranteed delivery, data integrity etc.) in addition to the end to end latencies for publishing and consuming data. This effort is independent of the monitoring that we already have where we monitor metrics emitted by the Kafka brokers.In addition to monitoring production systems, it will also be used for validating a new Kafka build that we might pick from the open source trunk to deploy to our production clusters. This will also help us ensure that new versions of the kafka broker don’t break existing older clients.
We believe that everyone running Kafka at scale would benefit from this.
Failure Testing
It is imperative that when we pick up a new version of Kafka from open source that we run it through a gauntlet of failure-tests to ensure the quality of the build is not only good for the positive scenarios but also in the event of failures. We have been working on a failure inducer framework called Simoorg (similar to the famous "Chaos Monkey") which would introduce low level failures in a machine (e.g. dropped network packets, low memory, failed disk writes, killing machines, processes etc.). We have integrated Kafka into this failure inducer framework and have already started validating Kafka releases using this framework.Application Lag Monitoring
The best way to ensure that your Kafka based application is healthy is to monitor whether the application is keeping up with consuming the incoming messages and is not falling behind. Our SREs built a new tool called Burrow which monitors the consumer lag and keeps track of the health of the consuming application.Keeping the Kafka cluster balanced
There are a few dimensions to this.- Rack Awareness: It is critical that the primary and the replicas of a Kafka partition are not placed on machines on the same datacenter rack. Doing so could cause the partition to be completely unavailable in the event of a failure of a top of rack switch.
- Ensuring that partitions of a topic are fairly distributed across brokers : This is especially critical going forward as we are going to start enforcing quotas for producing and consuming data into Kafka. In essence if partitions of a topic are evenly distributed across brokers then an application would get more bandwidth than if the partitions of a topic end up at the same broker node.
- Ensuring that a few nodes in a cluster are not running out of disk and network capacity: In some situations it is possible that a large number of partitions for a few hot topics show up on a small subset of broker nodes. As a result those nodes run a higher risk of running out of disk or network capacity.
Using Kafka as a core building block in other Data systems
At LinkedIn, we use Espresso as our NoSQL database. We are currently in the middle of an effort to start using Kafka as the replication backbone for Espresso. This is a major initiative and will put Kafka on the critical path for site latency sensitive data paths which also require much higher message delivery guarantees. This presentation from one of our developers provides a detailed overview of what it takes to guarantee message delivery with Kafka. To support these scenarios, we are currently doing a lot of performance tuning to ensure that message transfer latencies can be kept low without compromising on the message delivery guarantees.In addition to the above scenario, Kafka will also be used for asynchronously uploading data into Venice which is a new store for serving derived data at LinkedIn.
At LinkedIn we use Apache Samza for all our real time stream processing needs. Kafka is a key source of events for most of our stream processing applications. Samza’s solid performance characteristics allow our stream processing applications to keep up with the staggering growth of ingested events. In addition to using Kafka as a source of events, Samza also uses Kafka as a durable store to backup application state. In essence, Samza stores the stream processor’s state in an embedded local disk based store. To allow the stream processor to recover its state in the event of a local disk failure, Samza automatically backs up the data into a log-compacted topic in Kafka. In the last year, we fixed critical bugs and made key improvements in Kafka’s log compaction feature to make Samza based applications more robust.
Kafka Ecosystem at LinkedIn
In addition to the Apache Kafka broker, client and mirror maker components, we have a few other key internal services to support some common messaging functionality at LinkedIn.Supporting non Java clients
At LinkedIn we also have a REST interface to Kafka which is popular among non-Java applications. We redesigned our Kafka REST service in the last year as the original design didn’t guarantee message delivery. Most of our mobile tracking events are sent using this service into Kafka.What is the schema for this message?
In any mature implementation of service oriented architecture, it is critical that the different services which are asynchronously communicating over the messaging bus (Kafka) agree on the corresponding message schemas. At LinkedIn, we have a mature “Schema registry service” . In essence when an application sends messages into Kafka the LinkedIn Kafka client registers the schema corresponding to the message (if it is not already registered). This schema is used automatically on the consumer side to deserialize the message.Check Please!
Given how pervasive Kafka is at LinkedIn, it is important to make sure applications understand that the infrastructure is not free. Basically it is critical for applications to know their own “usage” of Kafka. With this it makes it easier to attribute the cost of the Kafka infrastructure to different applications at LinkedIn. This allows application teams to be aware and accountable for how expensive it is for LinkedIn to run their application. To achieve this we have instrumented the LinkedIn clients to automatically generate MB sent and received back into a Kafka Audit Topic. This topic is read by a Kafka Audit Service which records usage information for later analysis.This effort allows us to continually evaluate if the overall Kafka usage for various applications is appropriate. We hope to decrease overall usage and hence costs as a result of this.
Did I get all the events between 1.00 and 2.00 PM?
Our offline reporting jobs process events from topics that they care about and generate hourly and daily reports. Given the geo-distributed nature of our infrastructure, the events take time to travel from the source Kafka topics/clusters/datacenters to their final destination in HDFS. Hence our Hadoop jobs need a mechanism to know that they got all the events they care about for the window of time corresponding to their daily and hourly reports. In essence the LinkedIn Kafka clients generate counts for the number of messages that they publish and consume. The Audit service mentioned above records this information and makes it available for hadoop (and other applications) to query using a REST interface. We have been working on a major revamp of this infrastructure over the last year.Supporting Large Message
At LinkedIn we limit our messages in Kafka to 1 MB in size. There are occasionally scenarios where this limit is not good enough. If the publisher and the consumer of such large events are the same applications then we typically just tell the application team to chunk the message into fragments and deal with it. In other situations, we have been just telling everyone to not get into this situation where a event becomes greater than 1 MB. Unfortunately there are a handful of applications which aren’t able to adhere to this rule. Also since Kafka is used as a pub-sub data pipeline, the consuming and producing application teams are completely agnostic of each other. So both sides have to use some common API for splitting and reassembling the fragments. Long story short, our team has now implemented a feature in the LinkedIn client SDK to automatically split and reassemble fragments corresponding to a single large message.We hope to open source several of these aspects of LinkedIn’s Kafka ecosystem over the next year as we believe that many of these problems are generic enough that other companies can leverage from these.