Burrow: Kafka Consumer Monitoring Reinvented
June 12, 2015
One of the responsibilities of the Data Infrastructure SRE team is to monitor the Apache Kafka infrastructure, the core pipeline for much of LinkedIn's data, in the most effective way to ensure 100% availability. We have recently developed a new method for monitoring Kafka consumers that we are pleased to release as an open source project - Burrow. Named after Franz Kafka's unfinished short story, Burrow digs through the maze of message offsets from both the brokers and consumers to present a concise, but complete, view of the state of each subscriber.
Why Are Kafka Consumers Hard to Monitor?
When I am speaking to others about monitoring the Apache Kafka infrastructure that we rely on at LinkedIn, I emphasize the importance of monitoring the consumers. What appears to be a simple problem on the surface, however, is difficult in practice without false positives and incomplete information. In general, the most important metric to watch is whether or not the consumer is keeping up with the messages that are being produced. Up until now, the fundamental approach to doing this is by monitoring the consumer lag (i.e. the number of messages the consumer has not yet processed), and alerting on that number. This basic method does have several problems:
- The
MaxLagsensor that the consumer provides is insufficient by itself. This sensor is only valid as long as the consumer is active, so if the application goes away entirely, the measurement is not valid. This can be addressed in some ways by monitoring other sensors, such as theMinFetchRate, however combining multiple metrics can be cumbersome and still only monitors the partition that is furthest behind. - Spot checking topics hides problems. If you decide to monitor only one or two topics for a wildcard consumer, you will miss problems that only appear on other topics. What if a single thread of the consumer dies? What if the topic you are monitoring is not covered by all consumer processes?
- Measuring lag for wildcard consumers can be overwhelming. Applications such as a Kafka Mirror Maker, or any client that consumes more than a couple of topics, would yield an overwhelming list of measurements. Lag is calculated per-partition, so if you have 100 topics with 10 partitions each, that is 1000 measurements to review. Aggregating the numbers leads to masking problems from slow topics, and makes it very difficult to know how bad a situation is.
- Setting thresholds for lag is a losing proposition. When a topic has a sudden spike of messages that crosses a monitoring threshold, alerts will go off. This does not necessarily mean that the consumer has a problem. Furthermore, the consumer is also only committing offsets periodically, which means that the lag measurement (when not using MaxLag) follows a sawtooth pattern. This requires a threshold far enough above the top of the pattern at peak traffic, which means it takes longer before you know there is a problem when not at peak.
- Lag alone does not tell you what has happened. If the lag goes up to a high number and levels off, does this indicate a failed consumer or a reporting error? What if the lag spikes up very high, is the consumer efficiently processing and going to catch up? These questions can't be answered just by looking at a single number.
Take the following lag graph of 4 consumers on different topics, for example:
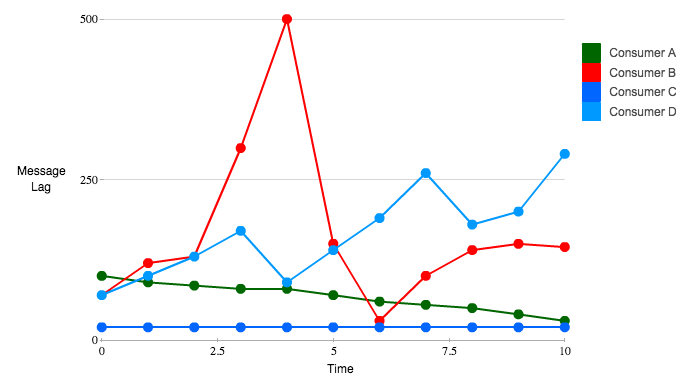 Figure 1: Sample Consumer Lag Graph
Figure 1: Sample Consumer Lag Graph
All four consumers are operating correctly. Consumer A is catching up on messages, and the lag is consistently dropping. Consumer B suffered a spike in the number of messages produced into the topic, but it quickly recovered. Consumer C has a steady amount of lag, but in this case the topic has a steadily high amount of traffic. The consumer can keep up without a problem right now. Consumer D looks like it has a problem, but looking at the entire interval, it catches up partially at two points. This means that there is a heavy amount of traffic in the topic currently, but the consumer is able to handle it. However, if we had a threshold value set at 250, both consumers B and D would generate alerts that are false positives.
Introducing Burrow
Burrow transforms how we think about consumer status. The most important way is by automatically monitoring all consumers, and doing so for every partition that they consume. It does this by consuming the special internal Kafka topic to which consumer offsets are written. Burrow then provides consumer information as a centralized service that is separate from any single consumer. This means that Burrow provides an objective view of the consumers, based on the offsets that the consumers are committing and the broker's state.
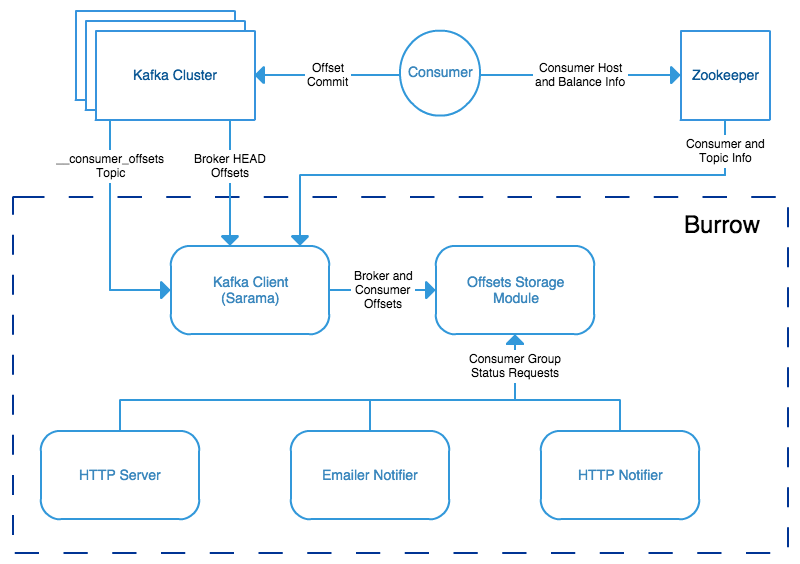 Figure 2: Burrow High Level Design
Figure 2: Burrow High Level Design
Consumer status is determined by evaluating the consumer's behavior over a sliding window. At LinkedIn, for example, we are using 10 offset commits, which covers a 10 minute period. Burrow evaluates several factors over the window, for each partition the consumer follows:
- Is the consumer committing offsets?
- Are consumer offset commits increasing?
- Is the lag increasing?
- Is the lag increasing consistently, or fluctuating?
The information is distilled down into a status for each partition, and then into a single status for the consumer. A consumer is either OK, in a warning state (which means the consumer is working but falling behind), or in an error state (which means the consumer has stopped or stalled). This status is available through a simple HTTP request to Burrow, or it can be periodically be checked and sent out via email or to a separate HTTP endpoint (such as a monitoring or notification system). All of this work is done without relying on thresholds. Burrow alerts us within 10 minutes of any consumer problem.
For example, if we have configured Burrow with a Kafka cluster named local which has a consumer group named kafkamirror_aggregate, a simple HTTP GET request to Burrow using the path /v2/kafka/local/consumer/kafkamirror_aggregate/status can show us that the consumer is working correctly:
It can also show us when the consumer is not working correctly, and specifically which topics and partitions are having problems:
Next Steps
Burrow is currently limited to monitoring consumers that are using Kafka-committed offsets. This method (new in Apache Kafka 0.8.2) replaces the previous method of committing offsets to Zookeeper. The team is investigating ways that we can monitor Zookeeper-committed offsets without needing to continually iterate over the Zookeeper tree. We are also adding additional requests accessible through Burrow's HTTP interface, such as more detailed consumer and topic information, to provide a simple API for automation to interact with Kafka.
Burrow Code and Documentation
Burrow has been released as open source under the Apache 2.0 license and is accessible at https://github.com/linkedin/Burrow. The documentation is available on the GitHub wiki at https://github.com/linkedin/Burrow/wiki.
Burrow is under active development by the Data Infrastructure Streaming SRE team at LinkedIn: Todd Palino, Clark Haskins, Grayson Chao, and Jon Bringhurst. We will be continuing to add features as we identify better ways to monitor the Apache Kafka ecosystem.