Moving faster with data streams: The rise of Samza at LinkedIn
July 14, 2014
Less than a year ago, we announced the first open source release of Apache Incubator Samza, a framework for processing big data streams. Today we are releasing Samza 0.7.0, a big milestone that reflects Samza's growing maturity.
This is a good opportunity to look back at how far we've come in the last year. Samza is no longer a research project, but is now deployed in production at LinkedIn with a growing set of applications. In this post we'll explore how we're using Samza at LinkedIn, and maybe you'll walk away with some ideas on how it can solve your problems, too.

The principles behind Samza
Samza is putting into practice our thinking on how large-scale, data-intensive applications should be built. In particular, it's about moving faster, at various levels:
- Hadoop is great for analyzing data, but because of its batch-oriented nature, it works best for data that is several hours, days or weeks old. If you need to respond to events faster — within minutes or seconds — you need a stream processing system such as Samza.
- Samza helps collaboration between teams: each team can have their own Samza job, and the jobs work together in a dataflow graph. This allows each team to ship code faster, without waiting for other teams to release.
- Samza encourages safe experimentation: our data scientists are constantly working to improve relevance ranking models, classifiers and other things which make LinkedIn more useful. With Samza, they can run the existing model and a new model side-by-side, and watch the metrics to see whether the new model performs better. Being able to do such A/B tests safely and quickly means faster feedback cycles and a better experience for our members.
You'll see these themes — responding to events faster, shipping code faster, experimentation with faster feedback cycles — recurring in many Samza jobs.
Case study: Site speed monitoring
A major focus for LinkedIn at the moment is making the site faster to load. In order to know where we need to improve, we use Real User Monitoring to measure the page load performance within the browser. This generates a stream of events containing information such as:
- Timestamp
- Which page the member loaded
- How long the page took to load
- Member's IP address location (city, country)
- Which content delivery network (CDN) was used
Until recently, we only analyzed this data in a Hadoop job once a day. However, if there is a problem with a particular network provider or CDN, and we only find out a day later, that's not good enough. We want to be able to detect within minutes if there is an unusual increase in page load times in a particular location, so that we can get our network operations team on the case and get the issue resolved quickly.
The site speed team is now using Samza to consume the stream of real user monitoring events, to group them by location, CDN and other dimensions, and to report median and 90th percentile response times. These feed into LinkedIn's monitoring and alerting system, which raises the alarm if there is an unusual increase in page load times.
And if a team has done a good job making a page significantly faster, we find out the good news faster too.
Case study: Data standardization
LinkedIn is full of information that our members have entered: profiles for people, companies and universities, status updates, skills, job postings and more. There is a lot of variation in that data, and sometimes it's helpful to apply a little standardization behind the scenes.
For example, if a recruiter is searching for a “software engineer”, we may also want to show them people who describe themselves as “computer programmer”, “developer”, “code artist” or “ninja rockstar coder” — since they all mean roughly the same thing (to a first approximation). However, the recruiter probably doesn't want to see the kind of developer who develops real estate, nor the kind of rockstar who plays guitar. From this example you can already see that dealing with synonyms in job titles is not straightforward.
At LinkedIn we have data standardization processes (classifiers) for job titles, company names, geographic locations, skills, topics, and more. Each of these is a complex beast which needs to be continually tweaked by the team that owns it. Moreover, each standardization process needs to run in two different ways:
- Whenever someone enters new data on LinkedIn, e.g. adds a new job to their profile, the standardization process needs to quickly resolve any synonyms and then update the search indexes accordingly, so that the member can be found in searches.
- Whenever the standardization algorithm or model is updated, we need to re-process all the existing data on the site, so that any classification changes are applied correctly.
Historically at LinkedIn, the stream process (1) was a custom framework using Kafka and Databus, and the batch process (2) was implemented as MapReduce jobs in Hadoop. You may have heard this kind of setup described as a Lambda Architecture. It works, but it has several problems:
- The standardization code needed to be developed, tested and run on two different APIs: Hadoop's batch processing API, and the stream processor's real-time API. Our attempts at abstracting over the APIs were not very successful.
- The custom stream processor didn't isolate different teams' code from each other. If one team broke the build or introduced a performance regression, all the other standardizers would also grind to a halt.
- There was no support for A/B testing different versions of a standardizer — a new version had to be rolled out to the entire site at once. This kind of “big bang” deployment is scary and slows everybody down.
LinkedIn's data standardization pipeline is now moving to Samza, which solves all of those problems. Using Hadoop is no longer necessary, because Samza has good support for both real-time processing and reprocessing old data. Each standardizer gets its own Samza job, so different teams can move faster without affecting each other.
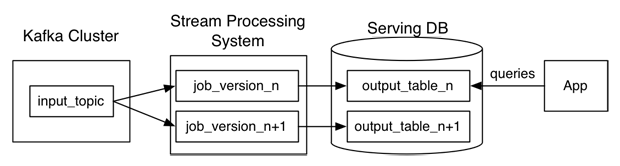
Also, Samza makes it much easier to run old and new versions of a job side-by-side. Each job version writes its output to a different location, as illustrated in the figure below (Jay Kreps has coined this the Kappa Architecture).
This setup makes it possible to run A/B tests and other experiments safely: when a new version is released, its output can initially be made visible to a small percentage of users. If it improves metrics, the remaining users can be switched to the new version; if it makes things worse, the experiment can be aborted without any consequences.
We are happy that Samza can help not just moving data around faster, but also help ship code faster and help people be more productive.
What's next for Samza
As these examples show, Samza 0.7.0 is ready to be used for some serious data processing. So what does the future hold?
As we are now supporting Samza jobs in production, our focus for the upcoming 0.8.0 release is making Samza truly great from a performance and operations point of view. We work in an environment where millions of messages per second are the norm, and where outages have a real business impact. Samza is being battle-tested as we speak, and that the experience we gain will only make it better.
Now is a great time to get involved with Samza. Although the project originated at LinkedIn, it is true open source: all of our development happens in public, and we are building a diverse community of contributors from many different organizations. You can start by running through the hello-samza tutorial and joining our mailing list.