Introducing Nurse: Auto-Remediation at LinkedIn
July 23, 2015
In ensuring site availability as you scale, you automate or you die.
Making sure LinkedIn works properly for 364 million members around the world takes a large and robust team of engineers. Since I joined LinkedIn three and a half years ago, we’ve added 200 million members and grown from a few hundred engineers to multiple thousands in offices around the globe. Ensuring our site is always available and working properly requires constant monitoring; as we add more features for members, we add more complexity to the site. In the recent past, we had a dedicated team of operations engineers whose sole job was to understand each site component and ensure our resolution of issues as rapidly as possible. These engineers were the frontline responders and troubleshooters that perform first-level issue detection, correlation, and resolution. Human eyes and hands maintained our site stability goals at all times.

Our constant growth created a problem for these operations engineers and our leaders had to make a decision: constantly increase the number of people monitoring the site or build automation to help them to do their jobs. The choice was clear. We began an initiative to automate our responses to alerts, allowing our operations engineers to focus less on the quantity of alerts and more on the quality of alerts.
In this post, we’ll share more on our approach, design strategy, and what automation has meant for the evolution of our Site Reliability Engineering (SRE) team and Network Operations Center (NOC) team.
Our Approach
First we had to define how we identify problems and handle issues. LinkedIn has a very robust system to collect hundreds of thousands of sensors, which my colleague Stephen Bisordi discusses in detail in a recent blog post. These sensors are attached to alerts that determine an error state with the particularly important alerts forwarded to our operations engineers for additional research, resolution, and action.
However, as time went by the number of alerts began to outpace our operations engineer’s time to triage. To address this, we have several alert goals in mind. In the short term, we want to automate the simpler alerts before our engineers are engaged to investigate. By reducing the number of alerts we monitor we should be able to better focus our engineers onto higher value activities like improving monitoring and noticing patterns. Our longer term goal is to create critical alerts that demonstrate symptoms the LinkedIn member is experiencing. The resolution of the causes of these symptoms would be automated. Only when automation has failed should a human be tasked to investigate.
Take the case of unavailable login servers, a symptom-based alert would be “unable to login.” The cause for “unable to login” could be varied. An operations engineer would take this symptom and perform additional troubleshooting to determine the exact cause, with each cause having a different set of resolution steps. A list of causes with different resolution steps could be:
- Process down
- Insufficient disk space
- Insufficient threads
Each cause would be a different alert and each alert would lead to different resolution steps. We had a well-utilized monitoring system that detected causes; we needed a way to describe remediation steps and execute against them.
Rather than creating a singular monolithic entity responsible for monitoring, workflow, and action, we tweaked the monitoring system to request workflows instead of the operations engineers’ attention. These workflows encapsulate the action necessary for resolution. These actions describe the path to resolution.

Fig. 1: The Separation of Powers
Let’s take the example of an application being offline. The monitoring system detects that a host is not in its intended state, i.e. able to serve traffic, because the service is offline, and uses a series of resolution steps to move the host to potentially a better state. Figure 2 details a possible workflow: Gather data on why the event occurred, restart the process, and place the results of the whole workflow into a ticket. This workflow is a powerful pattern. Depending on how busy our site is, we could see dozens of alerts with similar workflows throughout the day. Only one of these steps leads to the alert being cleared: the restart.

Fig. 2: An Example Workflow
The number one priority of our operations engineers is to keep the site up. It necessitates gathering data and recording action to fix long-term problem and track recurring issues. However, an engineer getting inundated with a constant flow of low-level remediation tasks might not have the time to notice the deeper patterns. With automated assistance and proper auditing, we can notice the true operational issues of our products.
Meet Nurse
Nurse is our auto-remediation platform that we started implementing in April 2014. Not only do nurses help you get better, they do the bulk of the work in a hospital including the majority of the operational tasks.
The design of Nurse is simple. Nurse acts as a broker between many systems as illustrated in Fig 3. Our monitoring system posts requests for remediation workflows to our remediation broker. We’ve implemented integrations with our code deployment system, ticketing system, remote execution system, and virtually any other system we can write integration into. We allow our site reliability engineers and operations engineers to combine any number of workflow actions into the systems we provide integrations for. These actions are the steps our engineers would perform to resolve the alert.
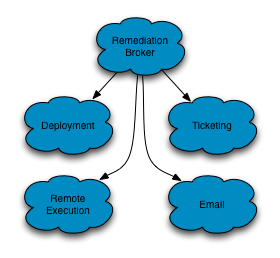
Fig. 3: Broker Centric
During our beta testing of Nurse, we saw its usefulness first-hand. A significant power disruption occurred and took many servers offline. One team had converted most of their monitoring to Nurse and was able to restore their entire stack within minutes of power restoration. The other impacted teams had to identify the servers through monitoring and issue the restoration commands manually.
Nurse gives us the flexibility to automate our lower level operational tasks and add in auditable and consistent tracking of remediation tasks. Our operations engineers and site reliability engineers can focus on better incident tracking and shorter duration of cause-based alerts.
What’s Next
We have a number of long-term goals with Nurse:
- Reduce monitoring fatigue
- Reduce recovery times on outages
- Allow operations engineers to focus on symptom-based alerts
Additionally, Nurse aids in the concept of assisted troubleshooting. If your symptom-based alert fires, you need to verify potential causes. Nurse could escalate a symptom-based alert, for instance users unable to login, with the potential causes already researched: thread-utilization, capacity issues, and downstream health. The person receiving the escalation from Nurse gets an automated glimpse into the overall service health, adding a great deal of context to begin troubleshooting an unhealthy service.
Nurse is also key to transforming the careers of our operational engineers. The auto-remediation system saves time and gives our team the opportunity to build new skills and explore new roles. For some, they can transition into site reliability engineers; for others, they’ll create new opportunities around in-depth site health and troubleshooting.
This automation is essential to maintain LinkedIn’s growth, as Nurse allows our operations teams to scale to new engineering possibilities. Nurse executes more than 150 hours of remediation workflows every week, saving our operations engineers crucial time for both career development and dedicating more time for clearing tech debt and improving processes. If you’re interested in joining our team, check out our open positions.
Acknowledgements
LinkedIn SRE as whole has been very enthusiastic throughout our journey. Nurse would not have been possible without the hard work and dedication from the whole development team, especially Matt Knecht and Ahmed Sharif.
Additional Resources
Facebook has an interesting take on its own automation, Facebook’s FBAR. StackStorm is a great open source project hoping to solve a lot of the objectives Nurse is attempting to solve. We only learned of StackStorm ourselves in November after we had a functioning prototype. Evan Powell and Dmitri Zimine the founders of StackStorm have been very helpful in LinkedIn’s journey. For SREs in the Bay Area, resources exist to continue the conversation, including an AutoRemediation meetup.