Skynet Project – monitor, scale and auto-heal a system in the Cloud
April 26, 2014
Skynet is a set of tools designed to monitor, scale and maintain a system in the Cloud. Put more simply, it’s a system that is aware about what’s happening on every single machine so it can also know about how the cluster is doing as a whole.
Background:
Our document conversion infrastructure is running in EC2. Pay-as-you-go is great for us, as we can scale depending on the number of documents our users are uploading to SlideShare.
We are firm believers in automation, so we decided to make the scaling process automated. The initial attempt was written in Bash, which was good enough while we were small. However, our cluster has grown by an order of magnitude. That’s why Casey Brown and I decided to build Skynet.
What and Why:
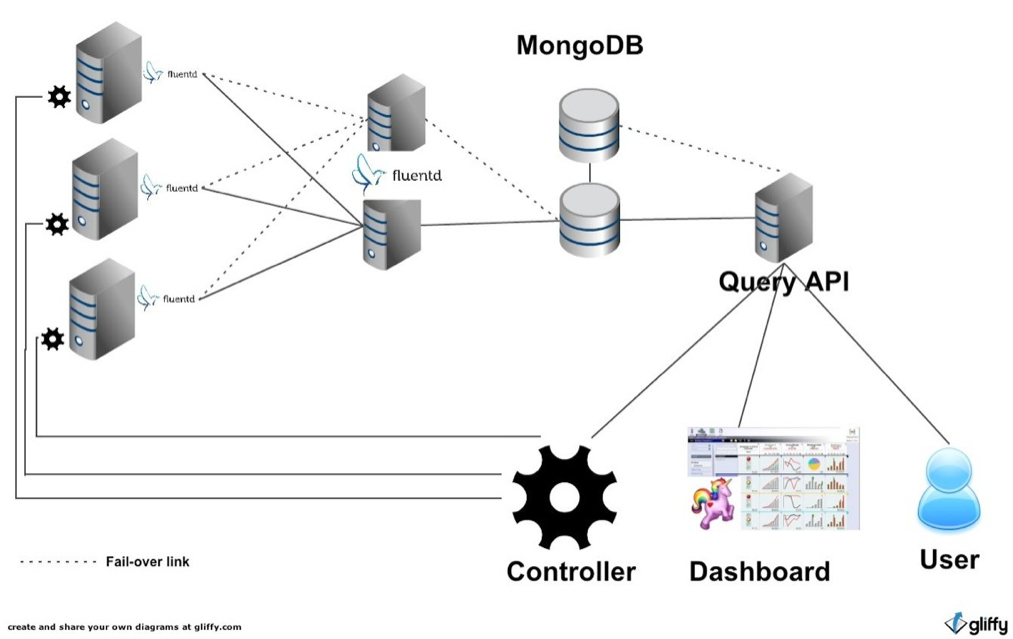
Skynet consists of:
- collectors (ruby code)
- message bus (Fluentd)
- data store (mongodb)
- api (ruby code)
- controller (ruby code)
- actions / scenarios (yaml)
The data collection part happens via two kinds of data collectors that we wrote: a library to gather application logs, and a daemon present on each machine to collect system metrics. These data are sent via Fluentd to multiple datastore in a reliable, fast and flexible fashion. We built these data collection tools ourselves because we wanted to be free to record what we wanted in the programming language we like (Ruby).
We are using MongoDB which we liked when starting the project because we were unclear about how the data would look. MongoDB gave us the flexibility that we needed. In front of that we have a REST API that allows anyone to consume data in an easy way without learning MongoDB-specific queries. It also gives us the possibility to change the datastore technology without disturbing data consumers (graph dashboard, analytics reports, Skynet controller…).
The scaling part happens with the controller, based on simple information like: number of documents waiting to be converted, load on machines and number of active connections on the web servers. You can easily decide if you need more capacity.
Auto-Healing
Let’s discuss the neat part: auto healing. We realized that for the majority of the on-call pages we get, we needed to perform a set of repetitive actions, which took us away from our precious foosball time. To solve that issue we provided the Skynet Controller a set of actions that it can perform, with which we can create scenarios (both actions and scenarios are organized in YAML files). Let’s pick an example where Skynet detects that a machine is not processing documents:
- It first gets the status of the application process; it finds out that it’s not running
- It attempts to restart process. The restart fails.
- It checks if the PID file is present, and it is. It deletes the PID file
- It try another restart. It works!
The scenario that I just described is a very classic one that any Ops person already performs hundreds of times in his career. Scenarios are actually possibility trees. Depending on the output of an action, it will pick the next action to perform. Additionally, scenarios can mix in other scenarios.
The decision engine, which is the Controller, gives us the ability to take smarter decisions than if every server would take decision locally. Let’s say that a condition shows up for every server at the same time: the Controller can decide to apply a scenario on a small part of the cluster, analyse the output and carry on or stop depending on how it went.
Finally we want to make Skynet able to learn. In the event that it can not solve a situation by applying a known scenario, it will attempt to execute a series of authorized actions and record whether they worked or not. Next time the Controller faces a similar issue, it will try the scenario that previously succeeded, and eventually scenarios that don’t work will be discarded.