Unifying the LinkedIn Search Experience
May 21, 2013
Search is a core part of LinkedIn’s platform. It’s what allows our 200M+ members to find jobs, hire employees, develop leads, research companies, and much more. Search allows our members to find and be found.
Recently, we launched a significant redesign of the LinkedIn search experience through the Unified Search platform. Our main goal is to make all of our professional content more discoverable and useful for our members.
In this blog post, I'll introduce you to the technology behind three new features in Unified Search that help our users find content on LinkedIn:
- Query auto-complete
- Content type suggestions
- Unified Search result page
Query Auto-complete and Content Type Suggestions
Type-ahead is a big part of the LinkedIn search experience. We open sourced Cleo, the technology that supports personalized, network-aware type-ahead. Until recently, we were focused on what we call ‘instant results’, which bypass the search result page and take the user directly to the profile page of the person, company, etc.
The 'instant results' approach works well for known item searches, like finding a person or company by name, but isn’t as useful for more exploratory queries, such as finding people who are skilled at Java or finding jobs for the user. Helping the user formulate their query helps with exploratory searches. Similarly, helping the searcher pick the right content type during query formulation leads to more relevant results with less effort.
For autocomplete, it is important to note that the best completion is not necessarily the most frequent query for the prefix. LinkedIn search queries have a long and heavy tail, and the most frequent queries make up a very small fraction of the total query volume. Additionally, the most popular queries are often very generic - containing too little information to provide relevant results. When picking the completion to suggest, we consider the likelihood of a successful search, and combine that with popularity to determine the final result. This prevents ‘jobs’ showing up ahead of ‘java’ when a user types in ‘j’.

For suggesting content types to search for a query, the objective is similar - we attempt to classify the query into the right vertical, and factor in the expectation of a successful search. As an example, for the query ‘software engineer’, the user is more likely to be looking for jobs and be successful in finding it, than doing the same for people. The probability that the user is looking for companies or groups for this query is so small that we don’t show suggestions for those.
Unified Search Result Page
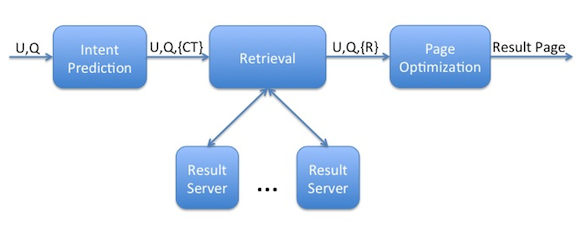
One of the biggest changes delivered through Unified Search is the elimination of the drop-down to select the search content type. Instead, our algorithms try to identify the content types a user is looking for, and construct a relevant page using results from multiple verticals. Pages are composed of results from a primary content type, and various types of secondary result components can be interspersed between the primary results. There are three key areas in this process:
- Intent prediction
- Retrieval
- Result page construction and optimization
Intent prediction
The intent prediction module is responsible for determining the likelihood of each content type being relevant to the query coming from the user. This module takes the user and query pair as input, and computes the probability distribution of each content type's chances of being relevant.
Correctly identifying the set of content types relevant to the query serves an additional purpose: it can be used to limit the number of verticals that the query is sent to. This is specifically useful for verticals that serve a small number of queries, which would otherwise need to be scaled to handle the full query volume. For example, a query that is clearly a person name is very unlikely to fetch relevant results from job search. In fact, features derived from an analysis of the query class are some of the most useful signals for intent prediction.
While building Unified Search, a key challenge was bootstrapping the intent models. Our solution uses data on pre-Unified Search behavior to build initial models. Specifically, users selecting a vertical from the drop-down, followed by searching and their interactions with the results gives us reasonable information about intent of those queries. We do need to compensate for findability bias, arising from content being hidden behind a drop-down.
Retrieval
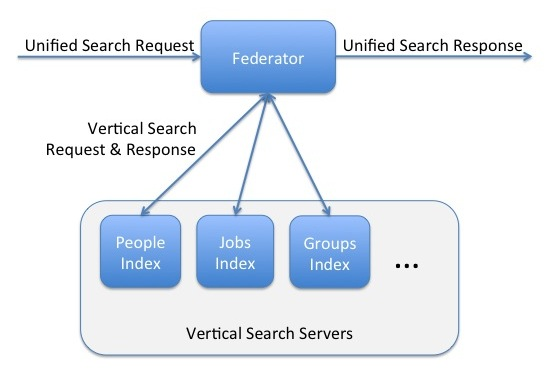
The responsibility of the retriever module is to compute the result sets for every candidate vertical. This module converts the unified search query into requests that can be understood by vertical search servers.
For example, one of the secondary components that can be part of the unified search result page is the high-confidence result slot. If there is high likelihood of the query being satisfied by a single result, a high-confidence component might be shown (LinkedIn as a company result in the example below), in addition to other primary and secondaries. This is also the integration point for new content types to be added into unified search. The retriever takes as input the triple of user, query and set of candidate verticals, and outputs the corresponding sets of results.
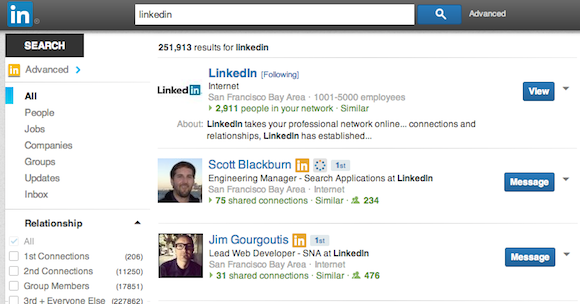
Page construction & optimization
At this phase, we just need to organize the sets of results fetched by the retriever into the optimal result page, taking into account the query and the user. The objective of the optimization is to position relevant content close to the top of the page. In Unified Search, relevance can be considered to be a two-part computation:
relevance = P(Content type | User, Query) x P(Document | User, Query, Content type)
The first term corresponds to the intent distribution over content types. The second term is similar to the traditional vertical-specific relevance score.
An alternative approach is to consider page optimization as a ranking problem, where results and result sets are represented as feature vectors and the algorithm tries to compute the optimal ranking of these feature vectors. In this case, the intent distribution becomes a feature, and additional features can be computed from vertical-specific ranking features of the results as well as past user interaction.
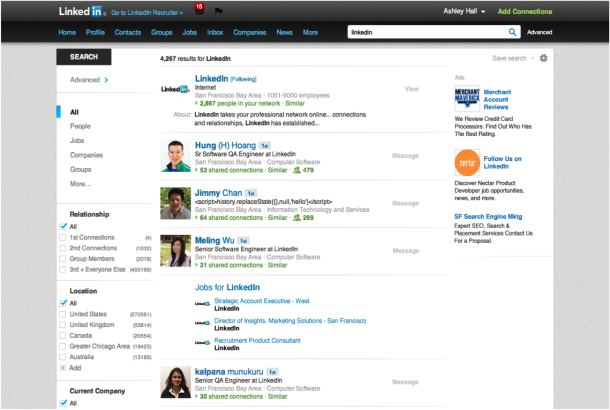
The following screenshot demonstrates Unified Search in action - in this case, for the query ‘data scientist’, we get a result page with a primary content type of jobs. A secondary cluster of people results adds diversity to the page and makes it more likely that the searcher will find the right content type for the query.
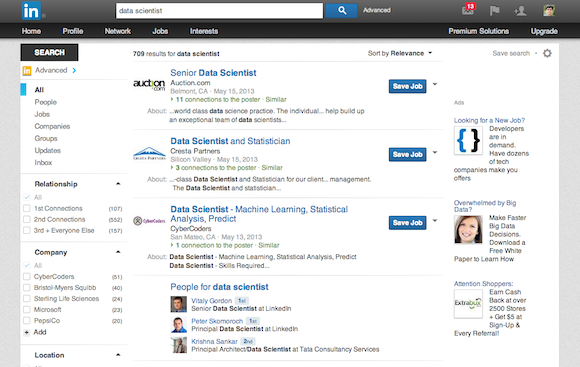
Finally, it's worth mentioning that occasionally, we can get the intent wrong. To help recover in such cases, the interface provides the ability for a user to switch to the right vertical. These actions, along with others, provide feedback on weaknesses and strengths of the models, and are used for evaluation as well as training.
Try it out!
We developed Unified Search to simplify the user experience, improve the discoverability of content, and help users formulate queries. In order to do so, we developed technology to predict search completions, infer user intent, and optimize result set construction. We have also used unified search to build a flexible platform which allows us to integrate new content types into the unified search experience.
We are very excited to roll out this new search functionality, and we hope you are just as excited to use it.