Did you mean "Galene"?
June 5, 2014
Introducing LinkedIn’s new search architecture
Authors: Sriram Sankar, Asif Makhani
Search is one of the most intensely studied problems in software engineering. It brings together information retrieval, machine learning, distributed systems, and other fundamental areas of computer science. And search is core to LinkedIn. Our 300M+ members use our search product to find people, jobs, companies, groups and other professional content. Our goal is to provide deeply personalized search results based on each member’s identity and relationships.
LinkedIn built our early search engines on Lucene. As we grew, we evolved the search stack by adding layers on top of Lucene. Our approach to scaling the system was reactive, often narrowly focused, and led to stacking new components to our architecture, each to solve a particular problem without thinking holistically about the overall system needs. This incremental evolution eventually hit a wall requiring us to spend a lot of time keeping systems running, and performing scalability hacks to stretch the limits of the system.
Around a year ago, we decided to completely redesign our platform given our growth needs and our direction towards realizing the world’s first economic graph. The result was Galene, our new search architecture, which has since been implemented and successfully powering multiple search products at LinkedIn. Galene has helped us improve our development culture and forced us to incorporate new development processes. For example, the ability to build new indices every week with changes in the offline algorithms requires us to adopt a more agile testing and release process. Galene has also helped us clearly separate infrastructure tasks from relevance tasks. For example, relevance engineers no longer have to worry about writing multi-threaded code, perform RPCs, or worry about scaling the system.
In this post, we’ll talk about the motivations to build Galene and take a deeper look into the major design decisions of the new architecture. If you’re a search engineer, we hope you’ll find some of our ideas useful in your own work. Even if you don’t work on search, we hope you’ll share our appreciation of the unique problems in this space.
The Pre-Galene Architecture
Lucene:
Our pre-Galene search stack was centered around Lucene – an open source library that supports building a search index, searching the index for matching entities, and determining the importance of these entities through relevance scores. Building an index is performed by calling an API that adds entities to the index. The search index has two primary components:
· The inverted index – a mapping from search terms to the list of entities that contain them; and
· The forward index – a mapping from entities to metadata about them.
The lists in the inverted index are called posting lists. Searching the index takes place by building a query containing search terms and then walking through the posting lists of these search terms to find entities that satisfy the query constraints. Relevance scores are determined from details of posting list matches and from information in the forward index.
Sensei:
Lucene indices can get quite large and often cannot be served from a single computer. So the index is broken up into pieces (shards), each containing a subset of the entities. Each shard is served from a separate computer. With multiple shards, we require support to distribute the query to all the shards, and to manage the computers that serve the shards.
We built (and open sourced) Sensei to support sharding and cluster management. There have been parallel efforts in the open source search community (eg. Solr and Elasticsearch) that build on top of Lucene to address these distributed systems challenges.
Live Updates:
Our professional graph evolves in real time, and our search results have to remain current with these changes. Lucene supports changes to entities by deleting the existing version of the entity, and then adding the new version. However, when only a single inverted index term changes in an entity, we need to obtain all the other inverted index terms that map to this entity in order to create the new version of the entity. Unfortunately, we cannot obtain this information from Lucene. We therefore built a system called the Search Content Store to maintain all inverted index terms keyed by the entity. Live updates are sent to the Search Content Store, which first updates itself, and then performs the corresponding removal and addition operations on the Lucene index.
Lucene had (until recently) another limitation with live updates – the changes to the index have to be committed before they are visible to readers of the index. The commit process is an expensive operation and can only be performed occasionally. To address this, we built (and open sourced) Zoie – which maintains an in-memory copy of the uncommitted portions of the index. This can be used for reading until the corresponding data has been committed in the Lucene index.
Other Components:
The pre-Galene architecture included a few additional components – Bobo, Cleo, Krati, and Norbert to name a few – to address other miscellaneous limitations of Lucene. These components have also been open sourced.
Hitting a Wall
As we mentioned earlier, our reactive approach to scaling the system eventually hit a wall. We reached the limits of the pre-Galene search stack – requiring us to spend a lot of time keeping systems running, and performing scalability hacks to stretch the limits of the system. Some of these pain points – which translated to the initial Galene requirements – are listed below:
· Rebuilding a complete index is extremely difficult: Given the incremental approach to building indices, rebuilding the entire index becomes a major undertaking. As a consequence, we minimized index improvements – thereby impacting relevance. And in those situations where rebuilding the complete index becomes absolutely necessary – for example, when indices get corrupted – we end up with very significant investments of people’s time and effort. We address this in Galene by moving index building to offline map-reduce jobs.
· Live updates are at an entity granularity: Any updates to an entity requires inserting a new version of the entire entity and deleting the old version. This becomes an immense overhead given that entities can contain hundreds of inverted index terms. And in addition we have to maintain a second copy of the inverted index in the Search Content Store. In Galene, we have introduced term partitioned segments (described in detail later) that allow updating only the changed portions of the index, obviating the need for a Search Content Store.
· Scoring is inflexible: Scoring in the pre-Galene stack is inflexible, making it very difficult to insert either hand-written or machine-learned scorers into this stack. Scoring in Galene is performed as a separate step from retrieval and implemented as plugins.
· Lucene does not support all search requirements: Lucene does not provide support for many requirements such as offline relevance, query rewriting, reranking, blending, and experimentation. Galene uses Lucene for indexing functionality, but goes beyond to address the other search needs.
· Too many small open sourced components: Given the large number of small components that were open sourced, the ownership of the overall pre-Galene system has become fragmented and spread across multiple organizations. It has been difficult to keep these systems working together at LinkedIn. We will not break Galene up into smaller pieces to open source separately. Instead Galene will be a single unified framework with a single identity.
Galene
In the new Galene architecture, we retain Lucene as the indexing layer. We use Lucene primitives to assist in building indices, and to build queries and retrieve matching entities from the index. Otherwise, all other functionality is outside Lucene. Sensei, Search Content Store, Zoie, Bobo, Cleo, Krati, and Norbert have all been discarded.
Life of a Galene Query
The following diagram shows the Galene search stack (as you can see, a typical search engine stack):
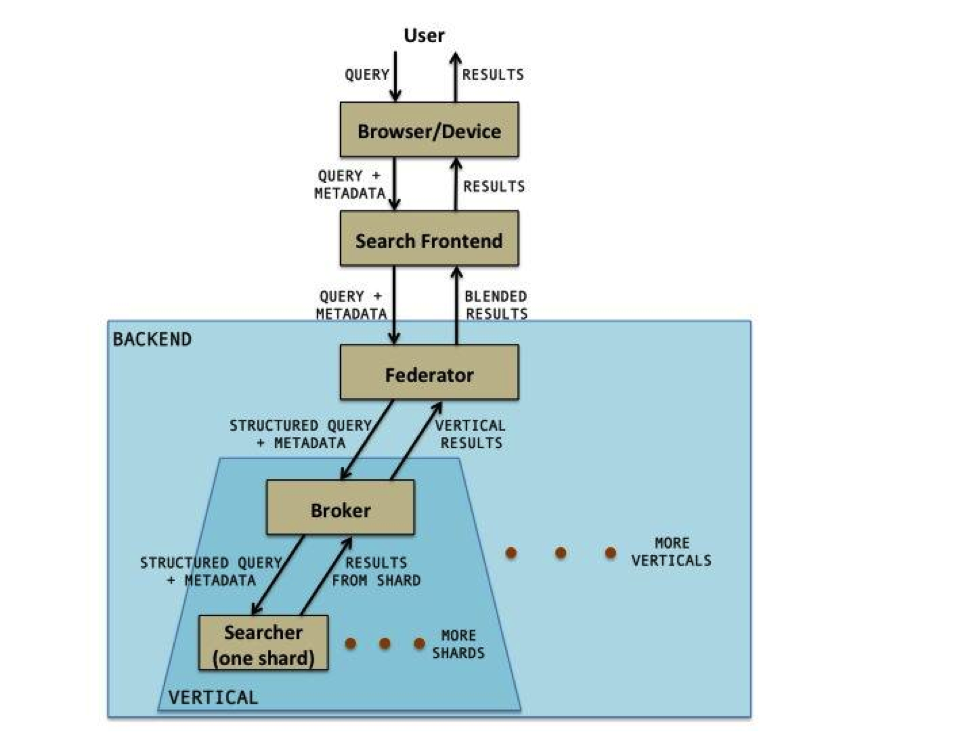
The Galene query starts at the browser/device where some processing takes place. It then moves on to the web frontend where further processing may take place. It then goes to the backend where the bulk of the Galene search functionality resides. The results returning from the backend go back to the user through the frontend to the browser/device. In this blog, we focus on the life of the query in the Galene backend – we will not discuss browser/device functionality or the frontend.
The Federator and Broker:
The Federator and the Broker are very similar services in that they both accept a query along with metadata, and fan it out to multiple services, then wait for responses from these services, combine these responses, and return them back to the caller.
On the way down, the Federator invokes a query rewriter to rewrite the query it receives into a structured retrieval query. The query rewriter also enhances the query with additional metadata. The Federator then passes its output to one or more search verticals. A search vertical serves a specific kind of entity – for example, members, companies, or jobs.
The receiving service in each vertical is the Broker. The Broker may perform additional vertical specific query rewriting before passing its output to the Searchers. The Broker waits for the Searchers to return results and then merges them together. This merging process may be as simple as a mergesort based on a score, or could be a reranker that performs more sophisticated merging.
The merged results are sent to the Federator, which in turn combines (or blends) the results from multiple verticals. The blending process can involve some complex relevance algorithms. The Federator then returns the blended results to the frontend.
The Federator and the Broker are both instantiations of the same system, which offers the ability to plugin rewriters and mergers. What makes the Federator and Broker different from each other is the actual plugins that are used.
Query rewriters are built as plugins to a rewriter API exported by the Federator and/or Broker. The job of the query rewriter is to take the raw query and user metadata, and convert it into a structured retrieval query. In addition, the metadata is enriched as necessary to help with the relevance measurement processes in subsequent stages. A typical rewriter schematic is shown below:
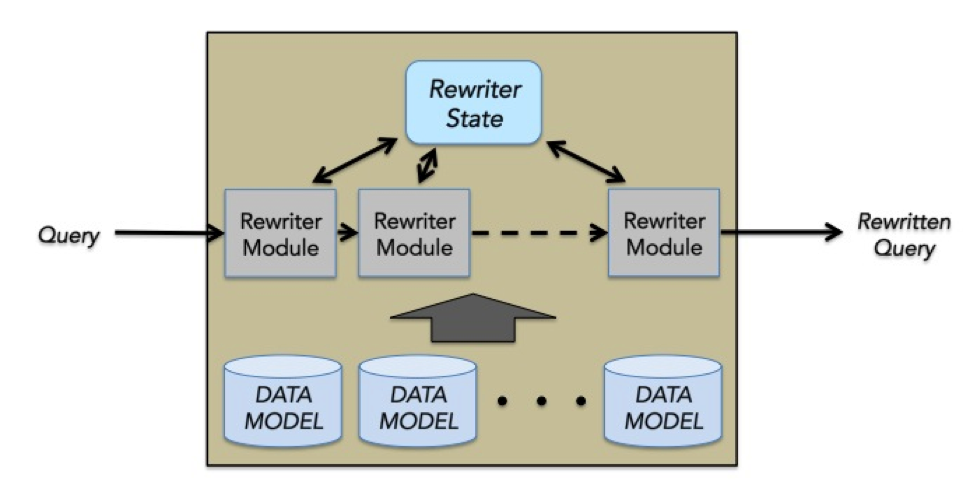
A rewriter is made up of multiple rewriter modules each of which performs a specific function. Specific functions can be synonym expansion, spelling correction, or graph proximity personalization. Each of these rewriter modules operates in sequence and update an internal state. After all of the rewriter modules are done, the final rewritten query is produced from this state.
The rewriter modules may need to use data models – for example, synonym maps, common ngrams, query completion data. These data models are built offline along with the search index and copied into the Federator/Broker.
The Searcher:
The Searcher operates on a single shard of the index. It receives the rewritten query and metadata from the Broker, and retrieves matching entities from the index. The entities are scored and the top scoring entities are returned to the Broker.
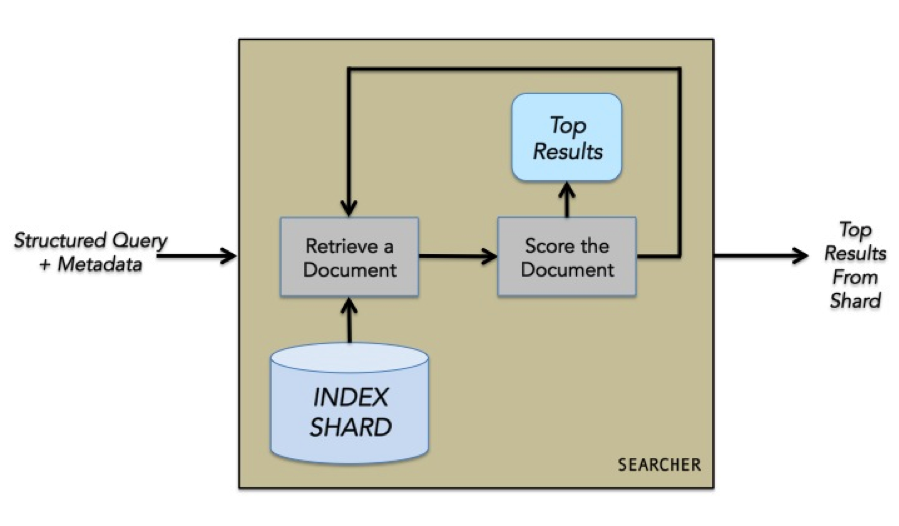
Scorers are built as plugins to a scorer API exported by the Searcher. The scorer uses the input query, the input metadata, details on how the query matched the entity, and the forward index to determine the importance of the entity as a result for the query. Simple scorers can be hand tuned, but more sophisticated scorers are built semi-automatically using a machine learning pipeline.
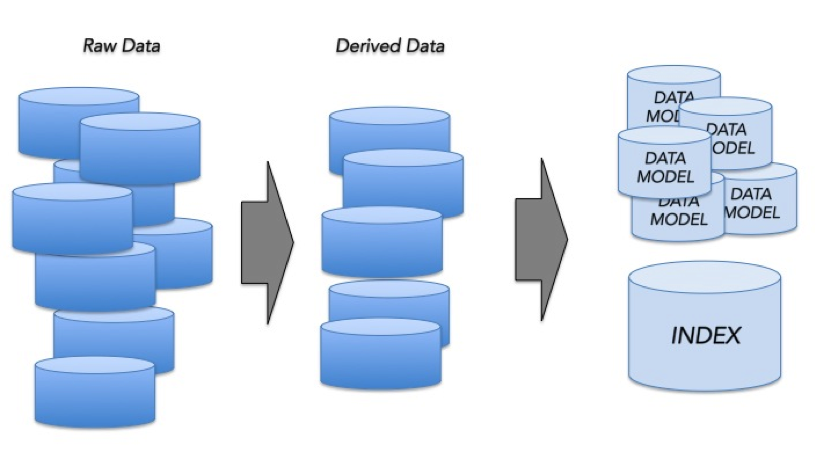
Indexing on Hadoop:
Indexing on Hadoop takes the form of multiple map-reduce operations that progressively refine the data into the data models and search index that ultimately serve live queries. HDFS contains raw data containing all the information we need to build the index. We first run map reduce jobs with relevance algorithms embedded that enrich the raw data – resulting in the derived data. Some examples of relevance algorithms that may be applied here are spell correction, standardization of concepts (for example, unifying “software engineer” and “computer programmer”), and graph analysis.
Galene provides custom map-reduce templates that perform the final step of building the actual index and data models. These templates are instantiated for specific jobs through schema definitions.
Early Termination:
Galene provides the ability to assign a static rank to each entity. This is a measure of the importance of that entity independent of any search query, and is determined offline during the index building process. Using the static rank, we order the entities in the index by importance, placing the most important entities for a term first. The retrieval process can then be terminated as soon as we obtain an adequate number of entities that match the query, and not have to consider every entity that matches the query. This strategy is called early termination.
Early termination works if the static rank of an entity is somewhat correlated to its final score for any query. The main benefit of early termination is performance – scoring is usually an expensive operation and the fewer the entities scored the better. Looked at in another way, early termination allows us to use more sophisticated scorers.
To maximize the benefit of early termination, the query rewriting process should bias the query towards retrieving the most relevant entities.
Live Updates:
Live updates in the pre-Galene architecture had a few significant problems:
· We have to make updates at the granularity of an entity, which impacts performance
· We have to maintain a second copy of the index in the Search Content Store
· Adding and removing entities from the index upsets the static rank order and the ability to perform early termination
· The index is always being modified resulting in a brittle system making it difficult to easily recover from index corruptions, etc.
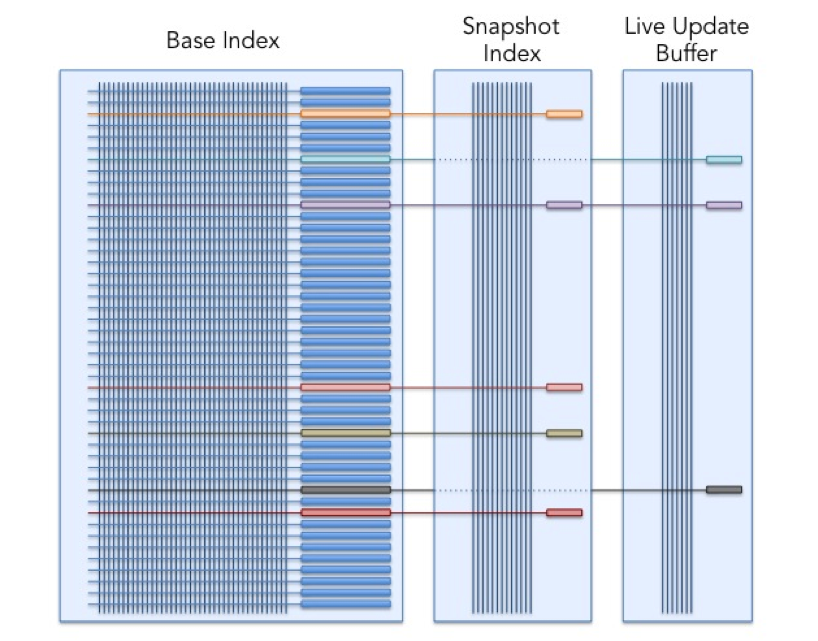
In Galene, live updates are performed at the granularity of single fields. We have built a new kind of index segment – the term partitioned segment. The inverted index and forward index of each entity may be split up across these segments. The same posting list can be present in multiple segments and a traversal of a single posting list becomes the traversal of a disjunction of the posting lists in each of the segments. For this to work properly, the entities in each segment have to be ordered in the same manner - given that we order entities by static rank in all segments, we satisfy the ordering constraint. The forward index becomes the union of the forward indices in each of the segments.
In Galene, we maintain three such segments:
· The base index – this is the one built offline on Hadoop. This is rebuilt periodically (say every week). Once built, it is never modified, only discarded after the next base index is built.
· The live update buffer – which is maintained in memory. All live updates are applied to this segment. This segment is designed to accept incremental updates and augment itself to retain the entities in the correct static rank order.
· The snapshot index – given that the live update buffer is only in memory, we periodically (every few hours) flush it to the snapshot index on disk to make it persistent. If the snapshot index already exists, a new one is built that combines the contents of the previous snapshot index and the live update buffer. After each flush, the live update buffer is reset.
This multi-segment strategy is illustrated below. The horizontal lines are entities and the vertical lines are posting lists. The box at the right extreme of each entity represents its forward index.
Index Lifecycle Management:
Our indexing strategy is complex – a base index is built every week, snapshots are generated every few hours, and these indices have to be present on all replicas of the searchers.
Generating snapshots is a costly operation. We cannot afford to do this on the searcher machines. Instead we have another set of machines called indexers. Indexers are identical to searchers in capability – except that they do not serve search traffic (they only accept live updates). Every few hours, indexers merge their live update buffer with their snapshot index. The snapshot indices then get shipped to all the corresponding searchers.
To support this we need an efficient and convenient mechanism to move the indices from where they are generated to where they are used – i.e., the base index needs to be moved from HDFS to the searchers and indexers, and the snapshot index from the indexers to the searchers.
We have built a bit torrent based framework to address this. This framework defines a concept called the replica group. Machines can join replica groups and automatically get all data associated with that replica group. These replica group members can also add data to their replica groups, which then get replicated to all the other members.
This framework is also used to move data models from HDFS to the Federators and Brokers. Additional lifecycle management, such as versioning of indices and rolling back capabilities, are also built into this system.
Galene in Action: Instant Member Search
One of the applications currently powered by Galene in production is Instant. Instant is the typeahead search experience that enables you to navigate and explore LinkedIn instantly. The most common use-case is Instant Member Search which provides the ability to search all of our 300M+ members by name.

We were able to provide significant improvements to the pre-Galene implementation that we replaced:
· Searching all of LinkedIn: Previously, Instant Member Search was limited to first and second-degree connections due to various constraints in the older architecture. With Galene, members can perform typeahead searches that include all of our 300M+ members.
· Better relevance: Galene’s Instant Member Search has a more sophisticated relevance algorithm that includes offline static rank computation, personalization through factors such as connection degree, and approximate name matching. Previously, it was not possible to incorporate such relevance functionality.
· Faster and more efficient: The new Instant Search is more than twice as fast as the previous implementation, utilizing about a third of the hardware – while still providing the gains described above.
Going Forward
The bulk of the work towards building Galene is complete, and we are realizing benefits today through powering multiple verticals in production. Our focus going forward is to continue migrating search verticals into Galene, while at the same time improving the quality of each individual search experience.
Galene has helped us improve our development culture and forced us to incorporate new development processes. For example, the ability to build new indices every week with changes in the offline algorithms requires us to adopt a more agile testing and release process. Galene has also helped us clearly separate infrastructure tasks from relevance tasks. For example, relevance engineers no longer have to worry about writing multi-threaded code, perform RPCs, or worry about scaling the system.
As we migrate more complex search products, we continue to evolve the Galene infrastructure to make it even more versatile. Some of the areas we are currently working on are highlighted below.
Improved Relevance Support:
Work is underway to enhance the scorer plugins to support machine-learned models (gathering training data, training, and deployment of models) in a systematic manner. The rewriter plugin framework is also being improved to become a more complete query planning framework. This framework will allow some iterative processing (for example, the ability to reissue a misspelt query after a second round of more expensive spell corrections when the first round did not return adequate results), and some composition capabilities (for example, the ability to build queries that depend on the results of other queries).
Search as a Service:
The search platform is being used to power multiple applications and products at LinkedIn – ranging from member-facing products such as People Search, Job Search and LinkedIn Recruiter to internal applications such as customer-service and advertising support. There is a growing list of applications at LinkedIn that require search functionality.
In order to scale across these search use cases, we are enhancing our cluster management system (inherited from Sensei) to automatically scale with data and traffic, provide the necessary system monitoring, provision hardware automatically, as well as provide seamless software upgrades across all applications.
Once this capability is ready, it should be possible for a simple search based application to be up and running in hours primarily through the specification of configuration schemas. All complexities associated with scheduling index builds, hardware allocation and scaling for capacity will be abstracted away.
Exploring the Economic Graph:
Sophisticated search functionality needs sophisticated interconnected data – provided by LinkedIn’s professional graph. Going forward, we have ambitious plans to further enrich this data by incorporating all the economic data there is in the world – to obtain the world’s first economic graph.
The Galene search architecture has been designed with this long-term vision in mind. Index terms do not have to be terms actually present in the entities. They can be attributes – such as graph edges. In fact, our Instant Member Search vertical already indexes a few different kinds of edges to help in providing social signals for relevance.
The query “group:82282 AND company:1337 AND term:information AND term:retrieval” exemplifies the kinds of capabilities that we are working on to support future search products. 82282 is the id for the Lucene Users group and 1337 is the id of LinkedIn (the company). The query retrieves members of the Lucene Users group that work at LinkedIn and have mentioned “information retrieval” in their profile. Other economic graph queries could be:
· Engineers with Hadoop experience in Brazil
· Data science jobs in New York in companies where my connections have worked at
· Connections of Asif or Sriram who work at Google
In Conclusion . . .
The past year has been immensely fruitful as we are moving to a more agile development process with the potential of frequent relevance improvements. There are other systems within LinkedIn that are based on the Lucene/Sensei stack and facing similar scaling issues – including the recommendations engine, newsfeed, and ads ranking. As we migrate search verticals to Galene, we will also work on migrating these other systems to Galene.
We would like to acknowledge the immense contributions of the search team. While we served as the architect (Sriram) and manager (Asif) of the Galene migration effort, we could not have done it without a stellar team that worked extremely well together and came up with many innovations. The team and the product efforts have complemented each other – resulting in not only a great product, but also a great cohesive team that we are proud to be a part of.
Thank you team, for this wonderful journey!
