Using set cover algorithm to optimize query latency for a large scale distributed graph
August 23, 2013
Social networks often require the ability to perform low latency graph computations in the user request path. For example, at LinkedIn, we show the graph distance and common connections whenever we show a profile on the site. To do this, we have developed a distributed and partitioned graph system that scales to hundreds of millions of members and their connections and handles hundreds of thousands of queries per second. We published a paper in the HotCloud'13 Conference, June 2013 that describes one of the techniques we use to keep latencies low:
Using Set Cover to Optimize a Large-Scale Low Latency Distributed Graph
In this post, I'll describe the greedy set cover algorithm we developed and how it reduces latencies for more than half the queries in our real-time distributed graph infrastructure.
Overview of Query Routing
LinkedIn's distributed graph system consists of three major subcomponents:
- GraphDB: a partitioned and replicated graph database.
- Network Cache Service (NCS): a distributed cache that stores a member's network and serves queries requiring second degree knowledge.
- API layer: the access point for front-ends.

A key challenge in a distributed graph system is that, when the graph is partitioned across a cluster of machines, multiple remote calls must occur during graph traversal operations. At LinkedIn, more than half the graph queries are for calculating distance between a member and a list of member IDs up to three degrees. In general, anywhere you see a distance icon on the LinkedIn site, there's a graph distance query at the backend. So, scalability and latency for this call are major considerations.
![]()
NCS, the caching layer, calculates and stores a member's second-degree set. With this cache, graph distance queries originating from a member can be converted to set intersections, avoiding further remote calls. For example, if we have member X's second degree calculated, to decide whether member Y is three degree apart from member X, we can simply fetch Y's connections and intersect X's second degree cache with Y's first degree connections.
A member's second-degree set is built in real time on every visit. On average, this cache has a hit ratio of over 90% to serve graph traversal queries. When cache miss occurs, the network cache service builds the cache in real time by gathering members' second-degree connection information from the GraphDB cluster. So the long tail of the graph distance queries comes from second-degree network cache miss. We use a brute force algorithm to compute this cache. The member's second-degree connections are gathered from several GraphDB nodes that store them. Each GraphDB node performs carefully tuned parallel merges to construct the partial result before sending the data back. A single NCS node is responsible for merging all partial results into one final second-degree array.
The Scaling Problem
During an effort to scale second-degree-network computation, we discovered that a much larger number of GraphDB nodes were needed to return a member's second-degree connections during cache creation. For example, say that a member has two connections X and Y, with X stored on partition Px, and Y stored on partition Py. We found that even if there was a GraphDB node storing both Px and Py, the routing layer was more likely to route the query to two different GraphDB nodes for Px and Py separately, causing the merging of connections X and Y to complete on the NCS node, rather than on the GraphDB nodes.
Set Cover Algorithm
We decided to apply a greedy set cover algorithm to address this query optimization problem. Greedy set cover algorithms are used to find the smallest subset that covers the maximum number of uncovered points in a large set. In this case, we would apply the algorithm to the set of partitions that stored a member's first-degree connections. Partitions stored on each GraphDB node would be the elements in a family of sets. We wanted to find the smallest number of elements from this set family that covered the input set.
The classic implementation of the greedy set cover algorithm worked very well to reduce the number of GraphDB nodes requested during second-degree cache computation, but it introduced a noticeable latency during nodes discovery. This latency was caused by a large number of set intersections done in each of the greedy selection iterations.
Enhancements to the Algorithm
We were able to modify this greedy algorithm by taking advantage of an additional property of our system: GraphDB nodes belonging to the same replica provide one copy of the entire graph, and there is no partition overlap among the nodes. We concluded that nodes from the same replica were more likely to provide greater coverage.
We started with a randomly selected partition from the set to be covered, and performed greedy set intersections only across the replicas covering the randomly picked partition and the entire set. By doing this, we had two guarantees:
- During each iteration, the algorithm would select two nodes that belongs to the same replica, or a node that offers equivalent coverage, or a node that removes at least the randomly picked partition.
- If we always checked at least one GraphDB node from each replica, we had a good chance of locating a node that provided close to optimal coverage, without having to examine every single GraphDB node in the cluster. This is because nodes belonging to the same replica as the already selected nodes tend to offer greater partition coverage.
Evaluation
We were able to apply this set cover algorithm in our production environment without introducing additional routing latency.
Second-degree cache creation time dropped by 38% in the 99th percentile.
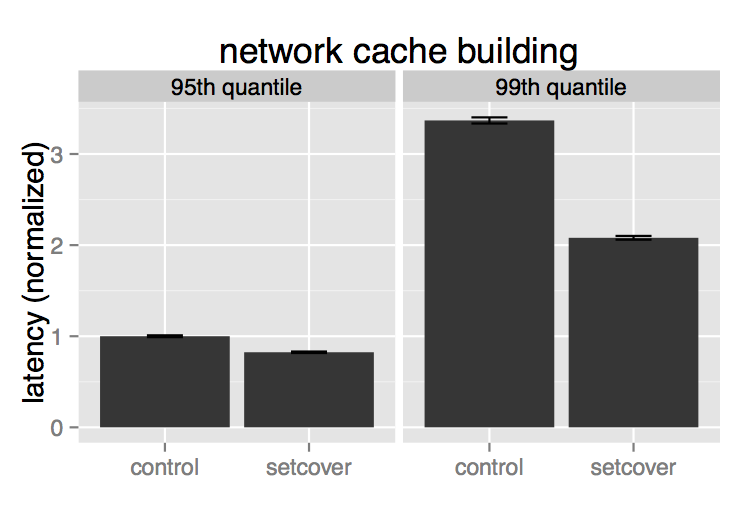
We also saw a 25% decrease in 99th-percentile latency for graph distance queries.

For more details, check out the full paper and HotCloud'13 talk. The Scala implementation of this set cover algorithm is available on github.