How LinkedIn used PoPs and RUM to make dynamic content download 25% faster
June 25, 2014
LinkedIn serves its dynamic content (e.g. HTML and JSON) from its data centers, while utilizing CDNs for serving the static assets such as CSS, JS, images etc. Like many other web companies, we have been using PoPs (Point of Presence) to improve the download time of the dynamic content.
PoPs are small scale data centers with mostly network equipment and proxy servers; that act as end-points for user's TCP connection requests. PoP would establish and hold that connection while fetching the user-requested content from the data center.
In this post, we will talk about the Real User Monitoring (RUM) based data-driven approach LinkedIn took to decide optimal mapping of user requests to PoPs.
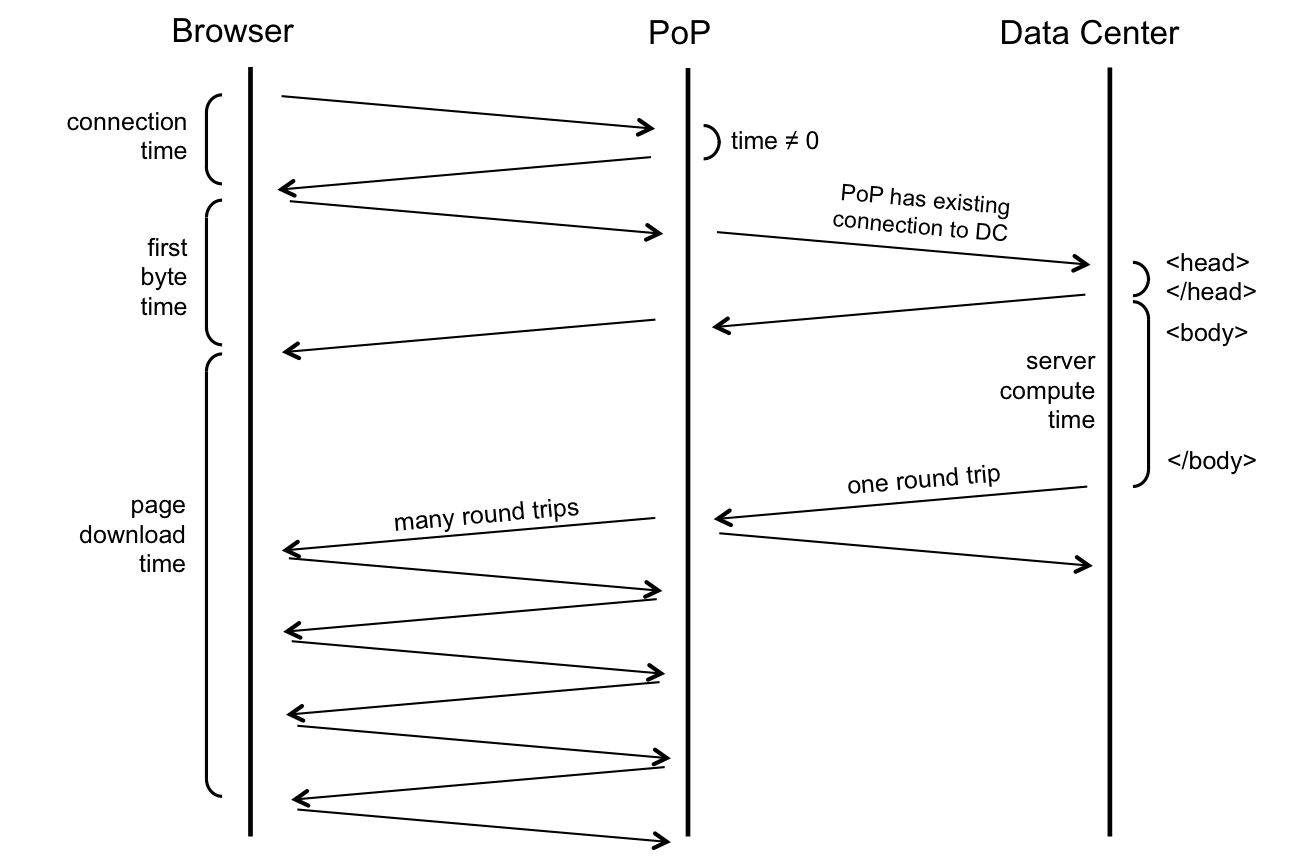
Here are the sequence of steps for downloading the desktop homepage
Now that we know how PoPs help performance, lets talk about the underlying mechanism to map a user to a PoP.
For example, if I run a
Given this ability and our expanding PoP footprint, the obvious next question was how do we make sure that our users are connecting to the optimal PoP?
Geographic distance: The simplest approach is to assume that the geographically closest PoP is the optimal PoP. Unfortunately, it is well known in the networking community that geographical proximity does not guarantee network proximity.
Network connectivity: Our Network Engineering team could have just assigned geographies to PoPs based on their understanding and knowledge of global internet connectivity. Unfortunately, the Internet is an ever changing beast (and we help change it by peering) and we would have never kept up with it by using a manual approach like this.
Synthetic measurements: We could also run synthetic tests using monitoring companies such as Keynote, Gomez, Catchpoint, and so on. These companies have a set of monitoring agents distributed across the world that can test your website. Well known problems with this approach include:
RUM is now the industry standard way to monitor the overall site performance. But, it is also a great data source for network performance analysis since RUM data has the user IP address along with various network performance metrics such as connect time, first byte time, page download time, and so on.
To identify the optimal PoP per geography, we enhanced our RUM framework to find latency from users to all the PoPs. This is done by downloading a tiny object from each PoP after the page is loaded and measuring the duration to download the object.
The following code snippet shows how this is done in JavaScript. This basic code workflow is added in our RUM framework for each of the PoPs to get the necessary data.
Even though the object being downloaded is tiny and the download itself is non-intrusive, we still limit this measurement to only 1% of our page views, which is enough to get meaningful and useful data. Through a daily Hadoop job, we aggregate this data and recommend optimal PoP per geography.
Once we knew the optimal PoP per geography, we configured our DNS providers to change PoP per geography and started seeing some amazing performance gains. We will talk about them in the Results section later in the post.
For the last two questions, once RUM is instrumented to add PoP information, we could run A/B tests between the candidate PoPs to identify the optimal one. Similarly, for the first two questions, we can use RUM to identify if the new PoP assignment took effect in a geography and whether it even helped.
Globally, we have enabled the PoP ID measurement for 10% of our members. This gives us enough samples to monitor PoP assignment constantly. We also enable PoP ID to a larger set of users in a given geography if we are running some experiment with PoP assignment.

South Asia
When we built our APAC PoP, it was not clear whether traffic from South Asia should be served from the APAC PoP or the Europe PoP. Common knowledge in the network community suggests that India has better connectivity to Europe. Through the PoP Beacon measurements though, we were able to determine that APAC is the more optimal PoP for most of our users in India, although Europe was not far behind. For Pakistan though, we got the opposite results: Europe came out slightly better than APAC. So through weighted DNS round robin, we directed half of the traffic from India to APAC and Europe PoPs respectively. We did the same for Pakistan. Using performance data from RUM segregated by PoP ID, we were able to conclusively determine that for most of our members in India, the APAC PoP is a better pick; while for Pakistan, the Europe PoP is a better pick.
When we correctly assigned users in India and Pakistan to use their respective optimal PoP (instead of the previous default, US West Coast PoP), we observed 28% and 25% reduction in median page download time, respectively!
PoPs are small scale data centers with mostly network equipment and proxy servers; that act as end-points for user's TCP connection requests. PoP would establish and hold that connection while fetching the user-requested content from the data center.
In this post, we will talk about the Real User Monitoring (RUM) based data-driven approach LinkedIn took to decide optimal mapping of user requests to PoPs.
How PoPs help
Let's take an example of the LinkedIn desktop homepage and go over how PoPs help to improve the measured page performance. Here are the sequence of steps for downloading the desktop homepage
- DNS: User’s browser initiates a DNS resolution of www.linkedin.com and gets the IP address of the PoP.
- Connection: User’s browser then connects to the PoP (TCP + SSL handshake). This time duration is called connect time.
- HTTP request to PoP: The browser then sends a HTTP GET request for the page to the PoP (usually with TCP's SYN-ACK packet).
- HTTP request to DC: PoP makes the same request to the data center (DC). But because PoP and data centers are owned by LinkedIn and are constantly communicating with each other, an existing TCP connection between them is used to request the page.
- Early flush: Data center does an "early flush" of content that is available, without waiting for the entire page to be assembled (usually the <HEAD> of the HTML) to the PoP, which the PoP then sends to the browser.
- HTTP response from DC: Servers at the data center build the rest of the page and send it to the PoP as it is assembled. Since the page is sent on an existing TCP connection, this TCP connection will likely have large TCP congestion windows. Thus the whole page could be potentially sent in one round trip time (RTT).
- HTTP response from PoP: As PoP receives the page, it relays the page packet by packet to the browser. Since the PoP to browser connection is usually not a long-lived connection, the congestion windows at this point are much smaller. TCP’s slow start algorithm kicks in and multiple RTTs are needed to finish serving the page to the browser.
Now that we know how PoPs help performance, lets talk about the underlying mechanism to map a user to a PoP.
PoP selection using DNS
LinkedIn uses DNS for PoP selection. We use third-party DNS providers as the authoritative name servers for www.linkedin.com. These providers let us configure their name servers to give different DNS answers based on user’s geographic location.For example, if I run a
dig command from LinkedIn's Mountain View office to resolve www.linkedin.com, I get the IP address of our West Coast PoP. But, if I try the same dig command using an open DNS resolver in Spain, I get back the IP address of our Europe PoP. https://gist.github.com/RiteshMaheshwari/5922c96c1194475e1b14.js
Given this ability and our expanding PoP footprint, the obvious next question was how do we make sure that our users are connecting to the optimal PoP?
Finding optimal PoP per geography
Here are a few techniques we evaluated which did not work:Geographic distance: The simplest approach is to assume that the geographically closest PoP is the optimal PoP. Unfortunately, it is well known in the networking community that geographical proximity does not guarantee network proximity.
Network connectivity: Our Network Engineering team could have just assigned geographies to PoPs based on their understanding and knowledge of global internet connectivity. Unfortunately, the Internet is an ever changing beast (and we help change it by peering) and we would have never kept up with it by using a manual approach like this.
Synthetic measurements: We could also run synthetic tests using monitoring companies such as Keynote, Gomez, Catchpoint, and so on. These companies have a set of monitoring agents distributed across the world that can test your website. Well known problems with this approach include:
- Agent geographic and network distribution may not represent our user base.
- Agents usually have very good connectivity to the internet backbone, which may not be representative of our user base.
What is RUM?
RUM, or Real User Monitoring, is a passive monitoring technique which consists of JavaScript code (LinkedIn RUM uses the boomerang library) that runs on the browser when our page is loaded and collects performance data. It does so mostly by reading the Navigation Timing API object exposed by the browsers. RUM sends the performance data to our beacon servers after page load. The beacon servers then send the event to our Hadoop cluster using Kafka.RUM is now the industry standard way to monitor the overall site performance. But, it is also a great data source for network performance analysis since RUM data has the user IP address along with various network performance metrics such as connect time, first byte time, page download time, and so on.
PoP Beacons in RUM
RUM measurements are done after page load and have no impact on the user experience. Thus, we can enlist our users to help improve their site experience by doing tiny, non-intrusive measurements (from their perspective) when they visit our site.To identify the optimal PoP per geography, we enhanced our RUM framework to find latency from users to all the PoPs. This is done by downloading a tiny object from each PoP after the page is loaded and measuring the duration to download the object.
The following code snippet shows how this is done in JavaScript. This basic code workflow is added in our RUM framework for each of the PoPs to get the necessary data.
https://gist.github.com/RiteshMaheshwari/a61797d732cbae4ed1f3.js
Even though the object being downloaded is tiny and the download itself is non-intrusive, we still limit this measurement to only 1% of our page views, which is enough to get meaningful and useful data. Through a daily Hadoop job, we aggregate this data and recommend optimal PoP per geography.
Once we knew the optimal PoP per geography, we configured our DNS providers to change PoP per geography and started seeing some amazing performance gains. We will talk about them in the Results section later in the post.
Which PoP served my page view?
Using PoP beacon data we were able to identify optimal PoP per geography in most cases. But a few open questions remained:- Did traffic really shift? After a geography is configured in DNS to use the identified optimal PoP, how do we ensure that traffic in that geography is actually going to that PoP?
- Did performance improve? For any identified optimal PoP assignment, how do we ensure it is actually the optimal PoP assignment?
- How do I pick between two PoPs? If two (or more) PoPs have very similar results from the PoP Beacons data, how do you pick among them? Note that PoPs have to fetch the page from data centers, so in the presence of multiple data centers, PoP to data center latency is also a factor.
- How do I pick between a PoP and a DC? A PoP has to fetch the content from a data center. If PoP Beacons data shows a PoP as the closest, but a data center as a close second, which one would really be optimal? Note that users can directly connect to the data centers as well because data centers also act as PoPs.
For the last two questions, once RUM is instrumented to add PoP information, we could run A/B tests between the candidate PoPs to identify the optimal one. Similarly, for the first two questions, we can use RUM to identify if the new PoP assignment took effect in a geography and whether it even helped.
Problem: Network Intelligence is at DNS
But how do we identify which PoP served a page view? As explained earlier, PoP is selected at the DNS resolution time based on user’s geographical location. Because RUM is a JavaScript running in the browser, it cannot do a direct DNS resolution to identify which PoP served this page view. But:- JavaScripts can read response headers of AJAX calls it initiated.
- PoP can identify itself by adding a response header to HTTP responses.
Solution: PoP ID in RUM
We implemented the following solution to identify the PoP that served a page view:- After a page is loaded (load event fired), an AJAX request is fired to download a tiny object on www.linkedin.com.
- The request goes to the same PoP that served the original page view. This is because of the way we have configured our DNS servers.
- PoP adds a response header that uniquely identifies it.
- RUM reads that header and uses it to identify which PoP served this page view.
- RUM appends PoP information to the rest of the performance data and sends it to our servers.
- Through offline processing, we aggregate performance metrics and traffic per PoP per geography to:
- Monitor amount of traffic in a geography going to a PoP.
- Compare performance metrics (for example, median page download time) across PoPs in a given geography.
https://gist.github.com/RiteshMaheshwari/1207875fe10716570ef9.js
At LinkedIn, we have used this method for RUM monitoring of our CDN providers' performance as well since this is a generic methodology for identifying any DNS resolution in JavaScript. Globally, we have enabled the PoP ID measurement for 10% of our members. This gives us enough samples to monitor PoP assignment constantly. We also enable PoP ID to a larger set of users in a given geography if we are running some experiment with PoP assignment.
Results
With PoP Beacons and PoP ID RUM data, we are now able to use a data driven approach to assigning users to our PoPs. The following chart shows gains in page download time for LinkedIn homepage for selected countries from this work. Case Studies
Let's go over few case studies where correct PoP assignment helped improve LinkedIn performance.South Asia
When we built our APAC PoP, it was not clear whether traffic from South Asia should be served from the APAC PoP or the Europe PoP. Common knowledge in the network community suggests that India has better connectivity to Europe. Through the PoP Beacon measurements though, we were able to determine that APAC is the more optimal PoP for most of our users in India, although Europe was not far behind. For Pakistan though, we got the opposite results: Europe came out slightly better than APAC. So through weighted DNS round robin, we directed half of the traffic from India to APAC and Europe PoPs respectively. We did the same for Pakistan. Using performance data from RUM segregated by PoP ID, we were able to conclusively determine that for most of our members in India, the APAC PoP is a better pick; while for Pakistan, the Europe PoP is a better pick. When we correctly assigned users in India and Pakistan to use their respective optimal PoP (instead of the previous default, US West Coast PoP), we observed 28% and 25% reduction in median page download time, respectively!
Middle East
Many countries in the Middle East appear geographically close to both Europe and APAC. Again, using the PoP Beacons data, we found that Europe is a better PoP for them. Upon assignment, we observed a 10-14% reduction in median page download time!China
China was expected to benefit from our APAC PoP, but the PoP Beacons surprisingly data showed that our US West Coast PoP had lower latencies to most of China users than the APAC PoP. Using third party monitoring tools, we were able to run traceroute from agents in China to our APAC PoP. The traceroutes showed some routing inefficiencies that made the packets take a longer route than necessary. Our Network Engineering team then worked with Chinese providers to resolve this. Unfortunately the gains are hard to quantify for China because we were not able to do a sane A/B test ( simplified chinese language launch and few other initiatives overlapped with our change). The expectation is that the gain is close to what is observed in other Asian countries.Pacific RIM
As a counter example, the PoP Beacons data showed our APAC PoP to be closest to Australia, Japan, South Korea and some other Pacific RIM countries. But the US West Coast PoP (which is also a data center) was close behind. So we changed the DNS configuration to conduct an A/B test and direct traffic with equal probability to our APAC PoP or the US West Coast PoP. Using the PoP ID data then, we found out that for these countries the page downloads are faster if they directly connect to our US West Coast PoP instead of going through the APAC PoP! This is likely due to the fact that even though these countries are closer to the APAC PoP, the APAC PoP still has to fetch the page from the data center (which adds approximately one round trip penalty), while for the US West Coast PoP, the data center is in the same location, so there is no penalty.Caveats
Having gone through the results from this project, lets talk about some of the shortcomings and caveats that make this work even more interesting. PoP selection is based on the user’s DNS resolver IP address. This has two major problems:- Resolver Usage: Users may use resolvers that are not geographically close to themselves. Such users might get assigned to a PoP suboptimal for them, but optimal for the resolver they use. For example, if a user in New York uses a DNS resolver based in California, they will get assigned to our US West Coast PoP instead of the more optimal US East Coast PoP.
- Bad Geo-IP Database: Our DNS providers use a Geo-IP database that helps them determine in which geography a resolver is located based on the IP address of the resolver. If this database is incorrect or incomplete, incorrect PoP assignment is possible.
- About 10% of traffic globally gets assigned to a suboptimal PoP.
- About 30% of US traffic gets assigned to a suboptimal PoP.
Conclusion
Given how important PoPs are for performance, we are working to do three things recently:- Build more PoPs!
- Use RUM data to answer the question: Where should we build the next PoP? RUM has the traffic data as well as information about which regions need PoPs due to bad performance.
- Investigate use of TCP Anycast or other techniques so that the impact of bad resolver usage or bad Geo-IP databases is limited. This has challenges for serving HTTP content, but is worth investigating due to reduced complexity in managing DNS and potential for improved performance.
- PoPs should be an important part of your web performance discussions, and
- RUM data can be used not just for performance monitoring, but also to make decisions to help drive performance optimizations!