LinkedIn Feed: Faster with Less JVM Garbage
December 2, 2014
At LinkedIn, a mid-tier service called feed-mixer serves feeds for all of our members across many distribution channels including our flagship iOS, Android, and desktop homepages (figure 1).
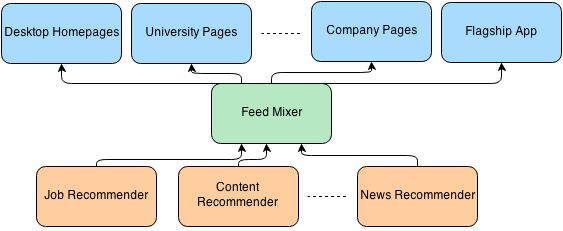 Figure 1: feed-mixer as a mid-tier service that serves feed across many clients
Figure 1: feed-mixer as a mid-tier service that serves feed across many clients
The feed-mixer service is critical infrastructure for LinkedIn, so it must always function like a well-oiled machine. Now that we've begun to offer SPR as a gold standard ranking library for many LinkedIn applications which lie outside the feed-mixer service boundary, we need to ensure consistent performance characteristics under higher-throughput conditions (ranking larger sets of items, for instance). In order to do so, we began by optimizing the memory allocations of SPR. Excessive memory allocations cause frequent garbage collections (GC), which pose significant problems to a highly-available backend system. This excellent post, written by a colleague who works on the data platform for feed, explains the impact of GC and how to tune it. In this post we offer some learnings from our efforts to reduce SPR's memory footprint (which, by the way, resulted in a 75% reduction in memory usage and a 25% decrease in overall service latency for feed-mixer... just sayin').
What We Learned
1. Be careful with Iterators
Iterating over a list in Java is trickier than it seems. “It is a list. I should be able to safely go through it. What is the trick here?” one might ask. It all depends on how you iterate through it. Compare the two versions of the code below for instance:
- Before: https://gist.github.com/N3da/9964538c0da1bb3e7a01.js
- After: https://gist.github.com/N3da/810f8fea6d5551a825f7.js
The first code creates an iterator object for the abstract list, while the second one simply uses the random access get(i) method, saving the iterator object overhead.
However, there is a trade-off to consider here. The first example which uses an iterator, is guaranteed to have O(1) time for getNext() and hasNext() methods, resulting in O(n) time for the iteration. However, with changing it to the old C-style for loop, we might end up paying O(n) look-up time for each _bars.get(i) call (in the case of a LinkedList), resulting in O(n^2) time to iterate through the list (in the case of ArrayList, the get(i) method will still be O(1)). Therefore, the underlying implementation, average length of the list, and memory should all be considered before making this change. However, since we used an ArrayList in most cases which has O(1) look up time and were optimizing the memory, we decided to go with the the second approach.
2. Estimate the size of a collection when initializing
From the documentation: "An instance of HashMap has two parameters that affect its performance: initial capacity and load factor. [...] When the number of entries in the hash table exceeds the product of the load factor and the current capacity, the hash table is rehashed [...] If many mappings are to be stored in a HashMap instance, creating it with a sufficiently large capacity will allow the mappings to be stored more efficiently than letting it perform automatic rehashing as needed to grow the table."In our code, we were sometimes going through an ArrayList and putting the items in the HashMap. Initializing the HashMap to the expected size avoided the resizing overhead. The initial capacity was set to the size of input array divided by the default load factor which is 0.7 similar to the examples below:
- Before: https://gist.github.com/N3da/3a0a6703fad495f328a9.js
- After: https://gist.github.com/N3da/3c71d5b911a21265f661.js
3. Defer expression evaluation
In Java, the method arguments are always fully evaluated (left-to-right) before calling the method. This can lead to some unnecessary operations. Consider for an instance the code block below which compares two objects of type Foo using ComparisonChain. The idea of using such comparison chain is to return the result as soon as one of the compareTo methods returns a non-zero value and avoid unnecessary execution. For example in this example the items are first compared based on their score, then based on their position, and finally based on the representation of the _bar field:
String objects to store the bar.toString() and other.getBar().toString() values, even though it is highly unlikely to be used. One way to avoid this is shown below with a custom implementation of a comparator for Bar objects: 4. Compile the regex patterns in advance
String manipulations are inherently expensive operations, but Java provides some utilities to make regular expressions as efficient as possible. Dynamic regular expressions are quite uncommon in practice. Each call toString.replaceAll() method in our example has a constant pattern that will be applied to the input value. Therefore, pre-compiling the pattern would save both CPU and memory each time this transformation is applied. - Before: https://gist.github.com/N3da/15fb8d18a4db8ac58029.js
- After: https://gist.github.com/N3da/4629043df7a4c2397ea8.js
5. Cache it if you can
Another way to avoid the expensive computations is to store the results in a cache. This clearly will be only useful if the same operation is done on the same set of data (like pre-processing some of the configurations, or in our case performing some string operations). There are multiple Least Recently Used (LRU) caches available but we used Guava cache (explained in detail here) similar to the code below:
6. String Interns are useful but dangerous
String interns can sometimes be used instead of caching string objects.
From the documentation:
"A pool of strings, initially empty, is maintained privately by the class String. When the intern method is invoked, if the pool already contains a string equal to this String object as determined by the equals(Object) method, then the string from the pool is returned. Otherwise, this String object is added to the pool and a reference to this String object is returned".
The idea is very similar to having a cache, with a limitation that you can't set the maximum number of entries. Therefore, if the strings being interned are not limited (e.g. they might contain unique member ids) it will quickly increase your heap memory usage. We learned this lesson the hard way where we used string interns for some keys and everything looked normal in our offline simulation since the input data was limited. But soon after it was deployed, the memory usage started going up (due to lots of unique strings being interned). Therefore, we chose to go with having LRU caches with fixed maximum entries instead.
Results
Overall we were able to decrease the memory usage of SPR workflow by 75%, resulting in the overall memory usage of feed-mixer to also drop by 50% (shown in the figure below). Allocating less objects and also having less frequent GC resulted in the overall feed latency to also drop by about 25%.
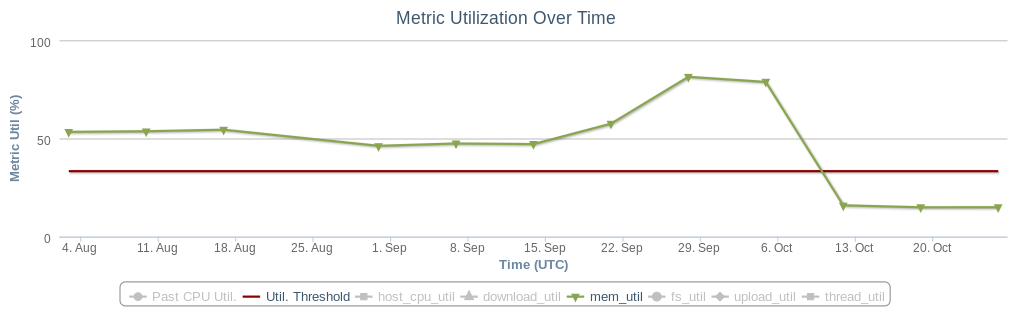 Figure 2: Memory utilization of feed-mixer dropping by 50%
Figure 2: Memory utilization of feed-mixer dropping by 50%