Cleo: the open source technology behind LinkedIn's typeahead search
March 1, 2012
LinkedIn has open sourced Cleo under the Apache Software License 2.0. Cleo is a flexible software library for enabling rapid development of partial, out-of-order, real-time typeahead and autocomplete services. It is powering the typeahead search services at LinkedIn.
Check out the Cleo source code and Cleo primer on Github!
LinkedIn Typeahead
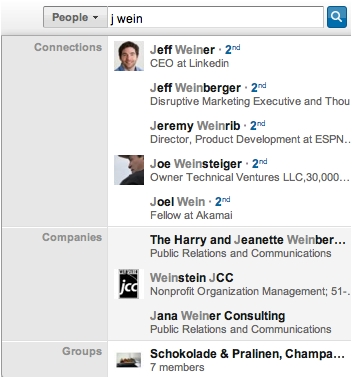
The typeahead services powered by Cleo include members (1st and 2nd degree network connections), companies, groups, questions, skills and various site features. These services are in two broad categories:
- Generic Typeahead: the same typeahead query from different members produces the same search results that can be ordered according to a global ranking scheme (e.g., popularity). A member's social network has no impact on search results. The typeahead services from this category are network-agnostic.
- Network Typeahead: the same query from different members produces different search results that are filtered according to a member's social network (1st and 2nd degree network connections). The current typeahead for LinkedIn members' network connections leverages the LinkedIn PYMK (People You May Know) scores to rank search results for better relevance. The typeahead services from this category are network-aware.
Cleo updates in real time: as soon as new members, companies, or groups join LinkedIn, they become immediately searchable through LinkedIn typeahead services. This provides a natural extension to the user search experience and makes it easy for members to engage in social activities such as discovering and connecting with professionals, following companies, and joining groups.
High-Level Design
The typeahead services built on Cleo can be network-aware or network-agnostic. Both use cases share the design shown in the figure below. From a high-level perspective, Cleo can do out-of-order prefix matching over a very large number of elements by means of in-memory scanning. It accomplishes this through mechanisms such as Inverted Index/Adjacency List, Bloom Filter and Forward Index:
- Inverted Index (or Adjacency List): stores the mappings from string prefixes (or members) to documents.
- Bloom Filter: provides a fast means to filter documents that cannot prefix-match against the query terms.
- Forward Index: used to reject false positives from filtering.
- External scores: can be provided for better relevance.
Query Walkthrough
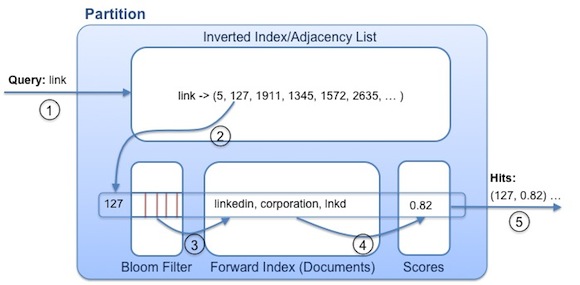
Here's an outline of the steps for handling the query "linked" submitted to the Company Typeahead:
- Each Cleo partition uses a prefix of the query - in this case, "link", since the prefix has a max length of 4 - to retrieve the inverted list of document IDs that contain that prefix.
- For each document ID in the inverted list, if the bloom filter of the document ID contains all the 1 bits in the 8 byte bloom filter of the original query ("linked"), then the document may potentially be a hit. Otherwise, it can be discarded.
- Upon a potential hit, the forward index is consulted to ensure that any term from the query shows up as a prefix in at least one indexed term of the corresponding document.
- Each partition returns all of its "true hits" with their external scores.
- The hits from each partition are merged and sent to client applications.
Adjacency Lists
For the Network Typeahead (1st/2nd degree connections), the Adjacency List (instead of the Inverted Index) is used to store mappings from members to members. The network typeahead query is enhanced with the searcher's 1st degree network connections. Within each partition, the searcher's 1st and 2nd degree connections that prefix-match the query terms can be found and returned in a few milliseconds. The hits from each partition are then merged and sent to client applications. With more than 150 million members, LinkedIn's Network Typeahead serves search requests in ~20 milliseconds on average.
If the Adjacency List is used to store mappings from members to other types of entities, such as news and questions, the same design can be applied to search for the entities associated with a member's 1st degree connections. In other words, what we have here is a network-aware typeahead for different types of entities.
An Example: Typeahead for Nasdaq
Cleo makes it easy to develop a RESTful typeahead and autocomplete service. Let's walk through an example using the cleo-primer package to build typeahead for public companies listed on Nasdaq:
- Download: cleo-primer on Github.
Launch the cleo-primer web application from the main folder:
You can customize the web application by choosing different values for cleo.instance.name, cleo.instance.type, and cleo.instance.conf. Depending on the size of your data sets, you may need to specify a different JVM heap size.
- The cleo.instance.name is assigned Company because we are building a typeahead service for companies listed at Nasdaq.
- The cleo.instance.type specifies a Java class cleo.primer.GenericTypeaheadInstance that instantiates an instance of Generic Typeahead. This is the only instance type supported by cleo-primer at the present time. We will add more in the coming future.
- The cleo.instance.conf specifies a file directory where several generic typeahead configuration files are located. For more information on configuring Generic Typeahead and Network Typeahead, please refer to Cleo Quickstart.
Index Nasdaq public companies using the prepared XML file:
If you have different types of elements such as schools and publications, you need to prepare your XML file according to cleo.primer.rest.model.ElementDTO.
- Test: visit http://localhost:8080/cleo-primer to try out cleo-primer.
RESTful API
The cleo-primer provides a restful API for client applications to use:
GET - Search
GET - Retrieve an element
GET - Retrieve all elements
GET - Retrieve a range of elements
DELETE - Remove an element
PUT - Update an element
POST - Add a new element
POST - Add a list of new elements
Try It Out!
Cleo is available at https://github.com/linkedin/cleo. Give it a try and let us know what you think. We are accepting contributions, so if you're interested in helping out, please fork the code and send us your pull requests!