Avatara: OLAP for Web-scale Analytics Products
September 19, 2012
LinkedIn has many analytical insight products such as "Who's Viewed My Profile?" and "Who's Viewed This Job?". At their core, these are multidimensional queries. For example, "Who's Viewed My Profile?" takes someone's profile views and breaks them down by industry, geography, company, school, etc to show the richness of people who viewed their profiles:
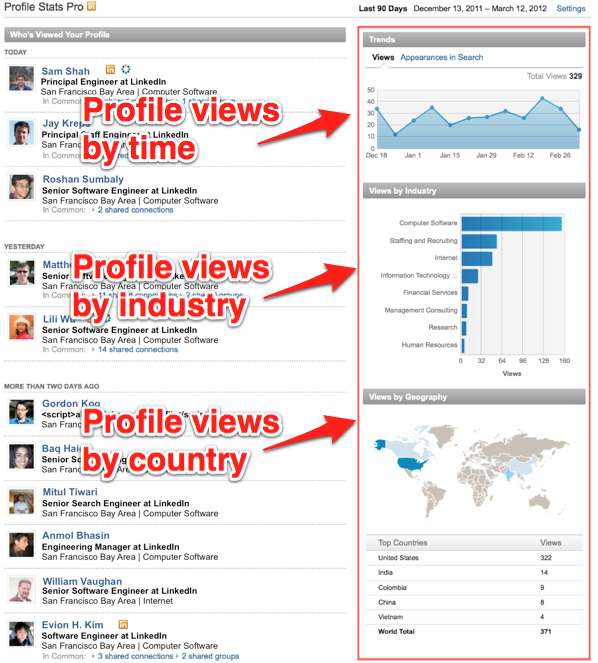
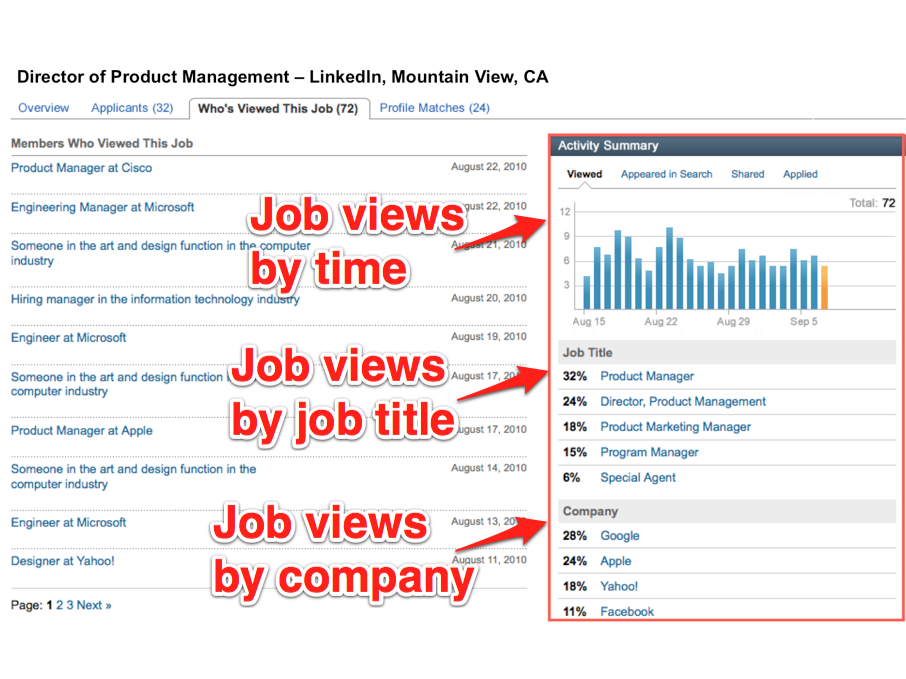
Online analytical processing (OLAP) has been the traditional approach to solve these multi-dimensional analytical problems. However, for our use cases, we had to build a solution that can answer these queries in milliseconds across 175+ million members. We called this solution Avatara:
Avatara: OLAP for Web-scale Analytical Products
Avatara is LinkedIn's scalable, low latency, and highly-available OLAP system for "sharded" multi-dimensional queries in the time constraints of a request/response loop. It has been successfully powering "Who's Viewed My Profile?" and other analytical products for the past two and a half years. We recently presented a paper on Avatara at the 38th conference on Very Large Databases (VLDB).
Overview
At LinkedIn, we need an OLAP solution that can serve our 175+ million members around the world. It must be able to answer queries in tens of milliseconds, as our members are waiting for the page to load on their browsers. An interesting insight for LinkedIn's use cases is that queries span relatively few – usually tens to at most a hundred – dimensions, so this data can be sharded across a primary dimension. For "Who's Viewed My Profile?", we can shard the cube by the member herself, as the product does not allow analyzing profile views of anyone other than the member currently logged in. We call this the many, small cubes problem.
Here's a brief overview of how it works. As shown in the figure below, Avatara consists of two components:
- An offline engine that computes cubes in batch
- An online engine that serves queries in real time
The offline engine computes cubes with high throughput by leveraging Hadoop for batch processing. It then writes cubes to Voldemort, LinkedIn's open-source key-value store. The online engine queries the Voldemort store when a member loads a page. Every piece in this architecture runs on commodity hardware and can be easily scaled horizontally.
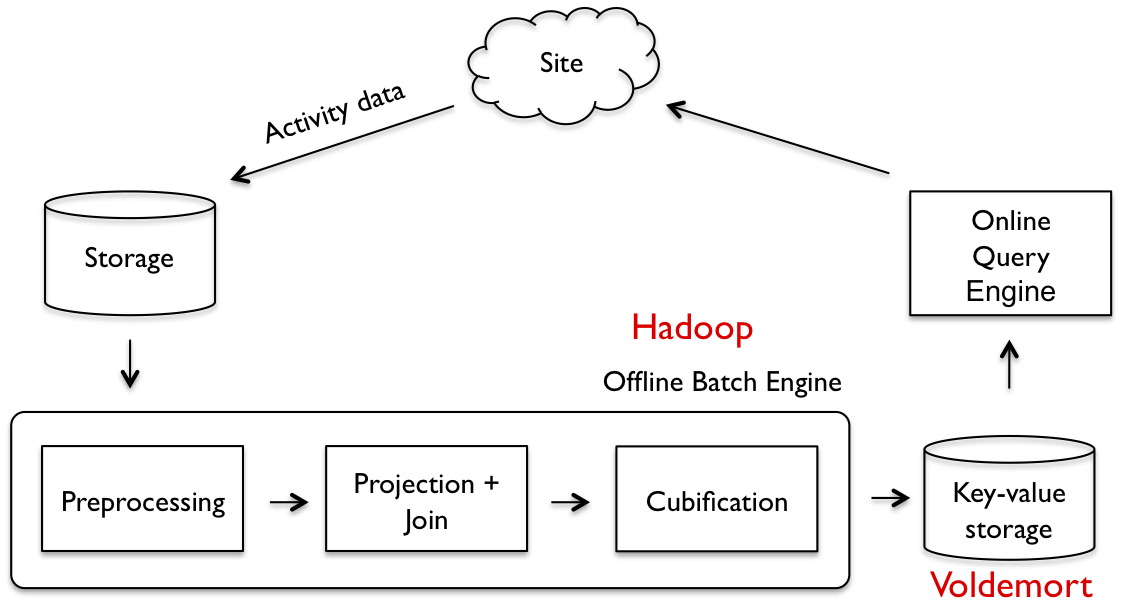
Offline Engine
The offline batch engine processes data through a pipeline that has three phases:
- Preprocessing
- Projections and joins
- Cubification
Each phase runs one or more Hadoop jobs and produces output that is the input for the subsequent phase. We utilize Hadoop for its built-in high throughput, fault tolerance and horizontal scalability. The pipeline preprocess raw data as needed, projects out dimensions of interest, performs user-defined joins, and at the end transforms the data to cubes. The result of the batch engine is a set of sharded small cubes, represented by key-value pairs, where each key is a shard (for example, by member_id for "Who's Viewed My Profile?"), and the value is the cube for the shard.
Online Engine
All cubes are bulk loaded into Voldemort. The online query engine retrieves and processes data from Voldemort, returning results back to the client. It provides SQL-like operators, such as select, where, group by, plus some math operations. The wide-spread adoption of SQL makes it easy for application developers to interact with Avatara. With Avatara, 80% of queries can be satisfied within 10 ms, and 95% of queries can be answered within 25 ms for "Who's Viewed My Profile?" on a high traffic day.
Learn more
If you're interested in more detail about how the system works, please see the full paper: Avatara: OLAP for Web-scale Analytical Products.