Open Sourcing ml-ease
September 25, 2014
Co-author: Bee-chung Chen,Bo Long, Liang Zhang
LinkedIn data science and engineering is happy to release the first version of ml-ease, an open-source large scale machine learning library. ml-ease supports model fitting/training on a single machine, a Hadoop cluster and a Spark cluster with emphasis on scalability, speed, and ease-of-use. ml-ease is a useful tool for developers working on big data machine learning applications, and we're looking forward to feedback from the open-source community. ml-ease currently supports ADMM logistic regression for binary response prediction with L1 and L2 regularization on Hadoop clusters.
ADMM stands for Alternating Direction Method of Multipliers (Boyd et al. 2011). The basic idea of ADMM is as follows: ADMM considers the large scale logistic regression model fitting as a convex optimization problem with constraints. While minimizing the user-defined loss function, it enforces an extra constraint that coefficients from all partitions have to equal. To solve this optimization problem, ADMM uses an iterative process. For each iteration it partitions the big data into many small partitions, and fits an independent logistic regression for each partition. Then, it aggregates the coefficients collected from all partitions, learns the consensus coefficients, and sends it back to all partitions to retrain. After 10-20 iterations, it ends up with a converged solution that is theoretically close to what you would have obtained if you trained it on a single machine.
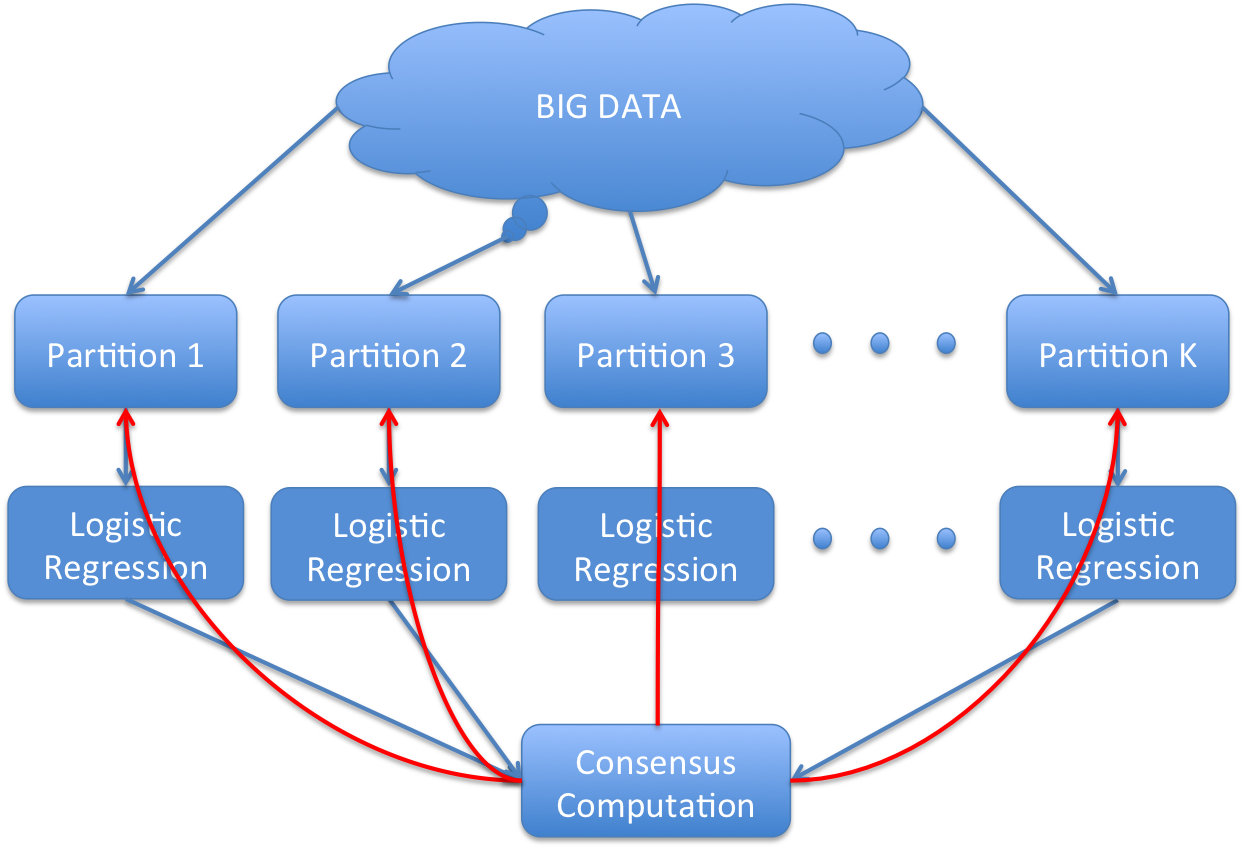
Figure 1. ADMM Logistic Regression Illustration
We are actively working on ml-ease and will release more machine learning algorithms in the near future, including support for:
- Linear regression with L1/L2 regularization.
- Poisson regression with L1/L2 regularization.
- Matrix factorization with different loss functions.