Espresso Onboarding Experiences: InMail
September 29, 2015
Fast growth is a happy problem to have, but not an easy one to solve. LinkedIn has experienced rapid member growth over the years and many of our engineers have witnessed the corresponding explosive data growth in awe. Until recently, LinkedIn relied on a traditional RDBMS as a primary data store for most of our data. Hundreds of terabytes of data were organized into Oracle shards that were incrementally provisioned as member growth continued. Several problems surfaced including:
- Hot Shards — Typical Oracle shards were created in the order by which members joined the LinkedIn service. Members who joined early on tended to accumulate more activities over time. This resulted in imbalanced traffic across shards, where some shards saw more traffic than others (i.e. hot shards).
- Schema Evolution — Data schemas need to evolve all the time to incorporate more information as business requirements change. In Oracle databases (or for any other traditional DBMS for that matter), this typically means a DBA running manual maintenance with
ALTER TABLEqueries. This is an error prone and time consuming process as millions of rows are read-locked during the maintenance. - Provisioning — Creating additional shards were not automatic. Provisioning of a shard translates to manual DBA work, as well as configuration changes from the application team. Coordinating such efforts were often painful.
- Cost — Specialized hardware and annual software licensing costs were expensive.
Fast forward to 2015, most of the major Oracle systems have been migrated over to Espresso, a horizontally scalable NoSQL database developed internally at LinkedIn. We have written extensively about the Espresso design in an earlier post. Espresso currently powers all of LinkedIn’s member profile data, InMail, and a subset of our homepage and mobile applications.
How did we get to this point? The migration from the legacy Oracle implementation to Espresso is an interesting topic on its own. The effort was more than just transferring bytes from one database to another, but a set of carefully designed features and workflows. We hope to turn this into a series of blog posts pointing out the highlights of this journey. But let’s start with the largest first — InMail.
InMail
InMail is one of the core features that makes LinkedIn an engaging professional network service. It is a messaging service that connects 380M currently registered members, and is by far the largest dataset at LinkedIn. At a high level, each member is associated with one mailbox that contains messages received, sent, and archived. InMail is characterized by several access patterns which make it a unique use case.
- Mailbox Search — A member’s mailbox contains sent/received/archived messages. The InMail application needs to perform a full-text search over all previous messages.
- Maintain Counter — Each time a message is received, corresponding counters (e.g. number of messages unread) need to be updated. The update of the message and the counters need to be transactional.
- Paginated Results — 99% of the time, a member is interested in the N most recent messages. The application displays paginated messages and search results in reverse chronological order. The messages that are very old are rarely accessed. This usage pattern in particular can be utilized for optimizations.
- Write Spikes — Invitations sent out to a member’s connections can generate a large number of mailbox writes in a relatively short amount of time.
Optimizations
Espresso is a horizontally scalable document store with secondary index support. Even without introducing additional features, Espresso design provides necessary functionality for the InMail use cases. However, constantly updating hundreds of millions of mailboxes while maintaining a search index does not come free. Several optimizations were implemented as a result:
Time Partitioned Indexes
For InMail use case, Espresso internally maintains its secondary index using Lucene, whose segments are stored as MySQL rows. When the application sends a search query for a particular mailbox, Espresso needs to read all index segments stored in MySQL and assemble them together as a Lucene index. For mailboxes with a large number of messages, the cost of index assembly becomes increasingly expensive.
The problem is alleviated by carefully aligning the system with the user's data access pattern. Since most of the members spend time accessing the most recent N messages, it makes sense to organize the indexes into a series of time buckets. Each bucket has a fixed size, and once the number of index segments in a given bucket exceeds a value, a new bucket is created. This localizes index access/update to a relatively small bucket, and effectively speeds up the mailbox searches and paginated results.
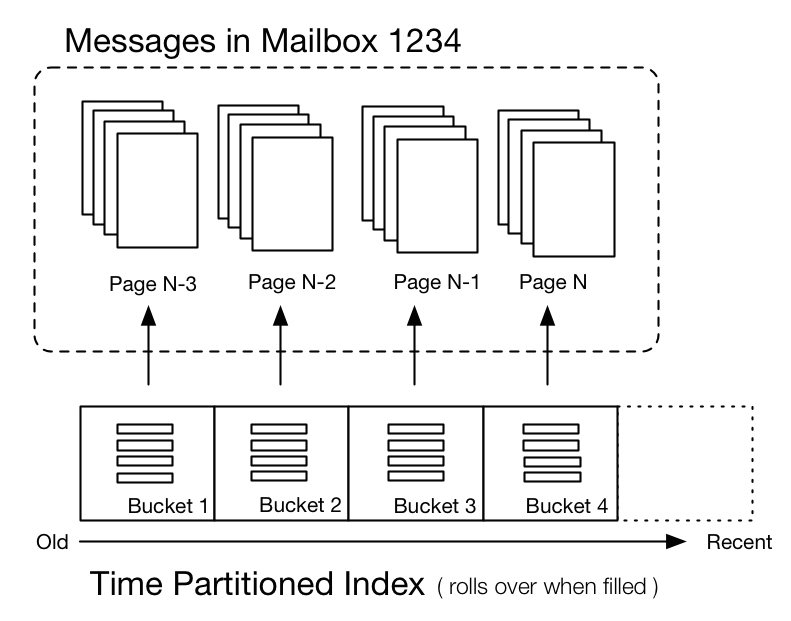
Group Commits
When the member invitations get sent out in bulk, the InMail application may generate a large number of requests for a mailbox (sent folder) in a relatively short period of time. This may result in hundreds of concurrent requests trying to update the index for the same mailbox. An index update is preceded by acquiring a write lock for the target mailbox, meaning other concurrent requests for the same mailbox are blocked. In a high throughput system, such lock contention typically leads to a thread pool exhaustion. Other requests are now starved.
After a series of design proposals, we have introduced a feature called Group Commit. When a storage node observes high number of concurrent index writes waiting for the same lock, they are grouped together and executed by a single thread. Group commit strategy significantly increases the throughput since the construction of index — the initial read of multiple index segment rows to assemble an index — is now reduced to once per group rather than per each index update request. Use of single thread also prevents excessive lock contention and starvation. The tradeoff here, of course, is the increased latency since individual requests are now dependent on all requests in the group finishing the execution. The increased latency can be compensated with client timeout adjustment. The benefits for group commit far exceeds the minor latency tradeoff.
Materialized Aggregate
InMail maintains several counters per mailbox. For example, when a new message is written to a mailbox, the number of unread messages is incremented by one. The unread message counter for a mailbox is decremented as one of the unread messages changes its status (isUnread == false).
It’s very tempting to think that a transactional write can satisfy this feature. As such, the application could supposedly couple each message insert with a counter increment, and make a transactional MULTI-PUT Espresso request. Even though the atomicity of the two writes would be guaranteed in a single cluster, this solution does not work for multiple data center cluster deployments. It is entirely possible that an update originated from a remote data center overwrite the local counter update. Depending on the order of events, this can actually produce a counter drift.
We have defined a declarative mechanism to register trigger-like predicates and aggregate functions (albeit limited) when defining a document schema. As series of updates are performed in each storage node, the aggregates are transactionally recomputed according to the conditions defined by the predicates. The aggregate results (i.e. counters) themselves are not replicated across data centers, as the storage nodes in each data center can simply recompute their own mailbox counters with respect to all local and remote updates. This feature enables Espresso to maintain precise counters across multiple data centers.
The following declaration maintains the number of unread messages through COUNT() aggregate. For each update, number of rows that meets the predicate condition (isUnread == true) is computed and written to unreadCount field.
The SUM() is another aggregate that is available in Espresso. For example, it can be used to sum over the total amount of bytes for all messages in a mailbox.
Personal Data Routing
From a technical standpoint, deployment of a petabyte scale cluster is not inherently different from deploying a smaller cluster. However, deployment of such size needs careful consideration from another dimension — CAPEX.
A typical Espresso cluster is deployed to three data centers, forming a data-everywhere, active/active topology. A write can originate in any data center and convergence will be reached through cross data-center replication. Espresso storage nodes within a data center also has a replica factor of 3, meaning each partition is typically 1 master and 2 slaves. With cost in the equation, the Espresso team needed to answer the hard question — ‘How much redundancy do we really need?’
We found out that the answer to the cost question really hinges upon the following observations.
- Two data centers are sufficient for disaster recovery (well, most localized disasters).
- The CAPEX of adding a data center copy on a petabyte level is very high. Conversely, the savings from keeping number of copies to 2 is difficult to ignore.
- Some datasets are more personal than others. A mailbox is only accessed by the owner of the mailbox. As long as the member traffic is consistently routed to the same data center as his/her mailbox, we can afford to reduce geographic distribution of this dataset.
For this reason, a strategic decision was made to limit each member's mailbox copy to two data centers, as opposed to data-everywhere.
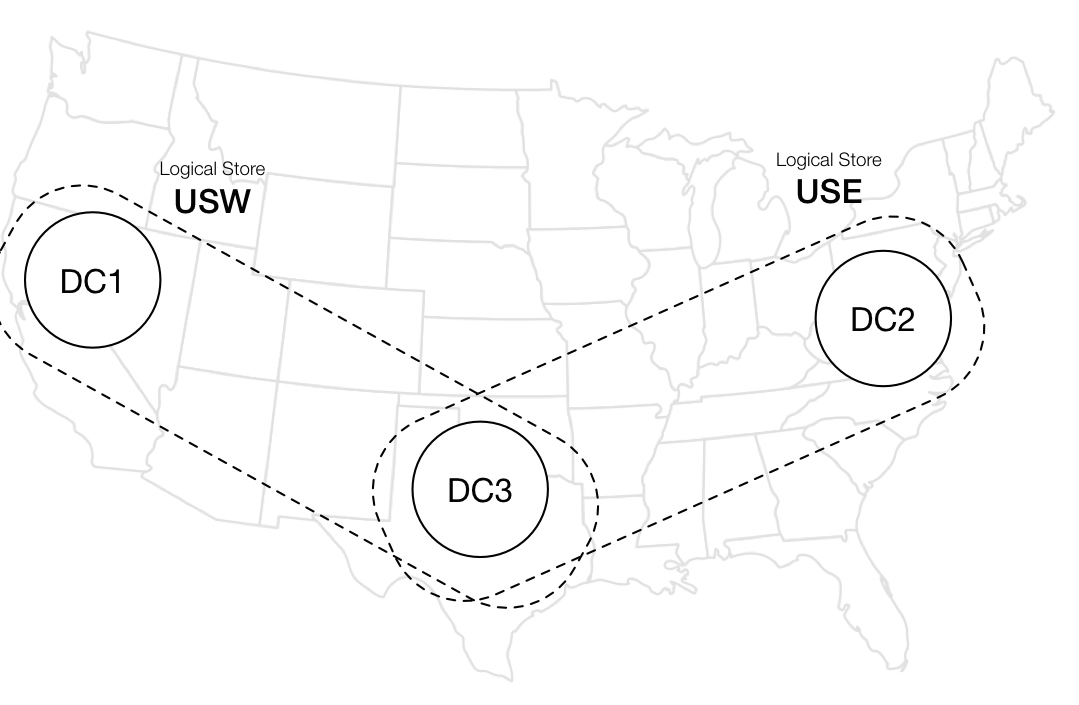
Without going into too much detail, this simply means that the data for a given mailbox will not be found in all data centers.
We have built a routing layer called Personal Data Routing (PDR) for this purpose. Regardless of which data center a request originates from, the service layer is able to lookup a special routing table and forward the request to a logical data store backed by at most two physical data centers. With PDR, we are able to control the degree of redundancy at the data center level. InMail mailboxes are currently divided into two logical stores – USE and USW – and have achieved significant footprint (therefore cost) reduction.
Migration
Basic Idea
When the InMail optimizations were tested and ready to go, it was time for the big move. The basic idea of moving data is actually not too different from moving boxes as you would if you were moving to a new house — we pack, ship, load, cleanup and reorganize.
- Pack Boxes — ETL data from Oracle to Hadoop, and transform the result into Espresso partitioned data
- Ship & Load — Copy and load the partitioned Espresso data to all storage node replicas without taking any down time.
- Cleanup & Reorganize — Remove import related files. Replay the rest of the events (what’s often called delta) from Oracle that have been updated since the ETL generation.
Coordination and Workflow
As the migration was about to start, there was a sense of urgency shared across teams as the operational complexity, licensing cost, and hardware footprint of maintaining Oracle instances were taking a toll each day. However, the timely migration was not simply a matter of ‘fast execution’, as it required coordinated efforts between multiple teams. It took careful planning from Oracle DBAs, InMail engineers, and Espresso engineers to come up with an optimal schedule. Eventually, the teams have agreed to proceed with the following schedule:
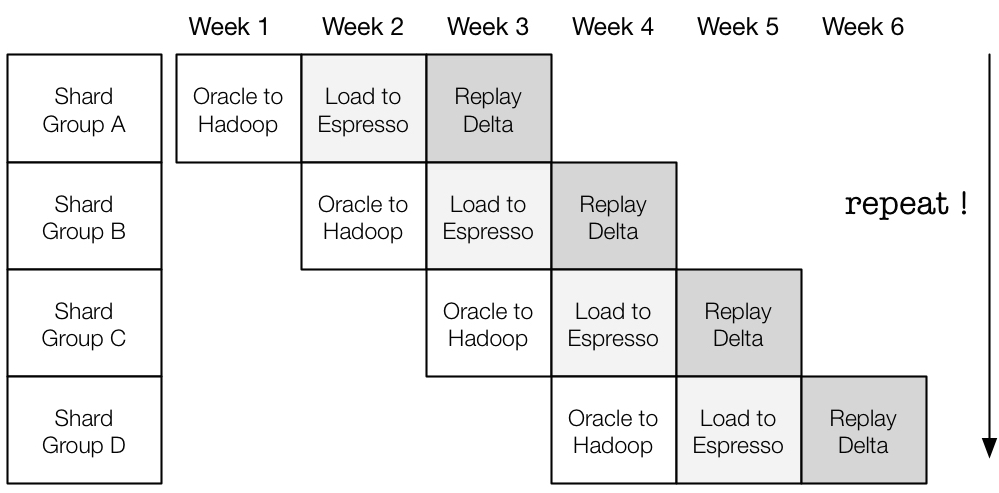
Although the pipeline looks relatively simple, there were subtle factors to consider in terms of sizing individual batches:
- The amount of time spent generating and loading data is directly proportional to the amount of delta catchup required afterwards (that is, more data piles up over time).
- The pipeline is bound by the largest batch in the workflow.
- The pipeline runs optimally if the batches are relatively equal in size.
We ended up choosing about five Oracle shards for a batch, which is equivalent to about 25 million member mailboxes. At the end of each batch, the stakeholders gathered together to checkpoint and then move to another one. When the pipelined workflow was in full throttle, each team was working fully in parallel.
ETL from Oracle to Hadoop
The process of taking ETL from the Oracle databases was owned by the DBA team. The DBAs took one shard from different Oracle instances so that the ETL can be generated in parallel. Since the shard sizes differ to some degree, there was some mixing-and-matching of the shards so that the total sum would be relatively constant between the batches. The Oracle dump was written to HDFS in a Hadoop cluster for additional transformation.
The InMail engineering team then ran a Pig script that transformed the Oracle dump into Espresso-ready data. Specifically:
- Monolithic Oracle dump was transformed into partitioned data (1024 for InMail), using the same partitioning hash function from Espresso.
- In addition to the baseline data, secondary index segments were also generated. This was done so that we can enable the index lookup immediately after the import.
- Each partitioned data was converted into tab-delimited data file, which was ready to be loaded into MySQL server with
LOAD DATA INFILEsyntax. Binary portion of data were represented using HEX.
Copying and Bulk Loading Data
At the time of the migration, the HDFS in use was not able to maintain a high read throughput. A few trial runs also suggested that an increase in concurrency further degrades the HDFS read performance. Espresso cluster was not co-located with the Hadoop cluster, which was another limitation. We looked for a solution where the reads from the HDFS can be kept to a minimum.
The target Espresso cluster had a replica factor of 3. Instead of all replicas performing the reads, we limited the direct interaction with the HDFS to a single replica per group. After that replica pulled the necessary partitions to its local file system, we let the other two replicas copy from it using compression and network pipes (e.g. tar | gzip | netcat). This resulted in a hierarchical distribution of input data. The copy between the replicas were dramatically faster than the HDFS read, since it was done within the same network. The slow HDFS performance was eventually overcome with this workaround.
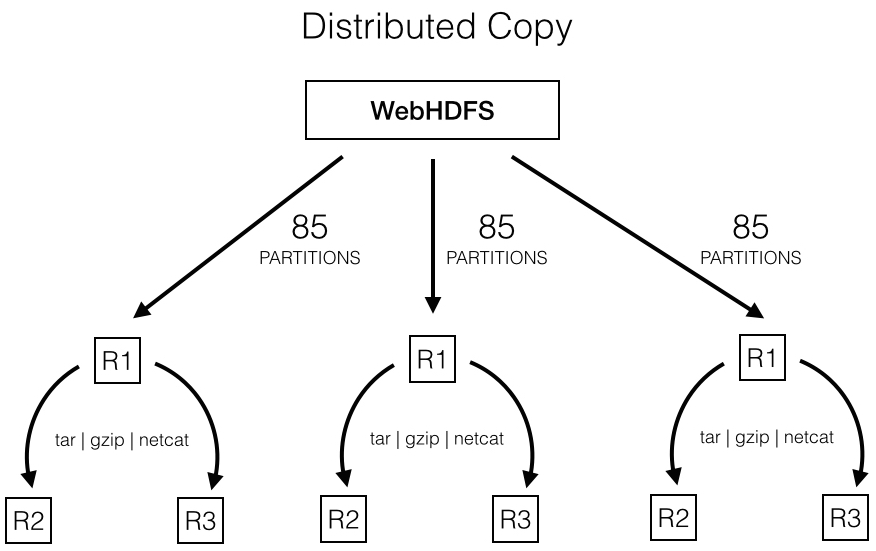
Once each storage node obtained the partitioned data it requires, the actual load was done by a simple call to MySQL’s ‘LOAD DATA INFILE’ query. The storage nodes were taking write traffic for the partitions that had completed the migration. We wanted to satisfy two requirements while the bulk load took place.
- No down time. No read/write impact to the partitions that have already completed the migration.
- At least two replicas in service. This guaranteed that mastership handoff can still take place.
Since the bulk load process was I/O intensive in nature and would interfere with the service quality, we decided to take each instance offline to perform the bulk load. With Helix — the distributed system coordination service that Espresso uses — we were able to programmatically disable one storage node after another for the bulk loading maintenance. If the node undergoing maintenance happened to be a master, one of the slave replicas was automatically promoted as a master without service interruption.
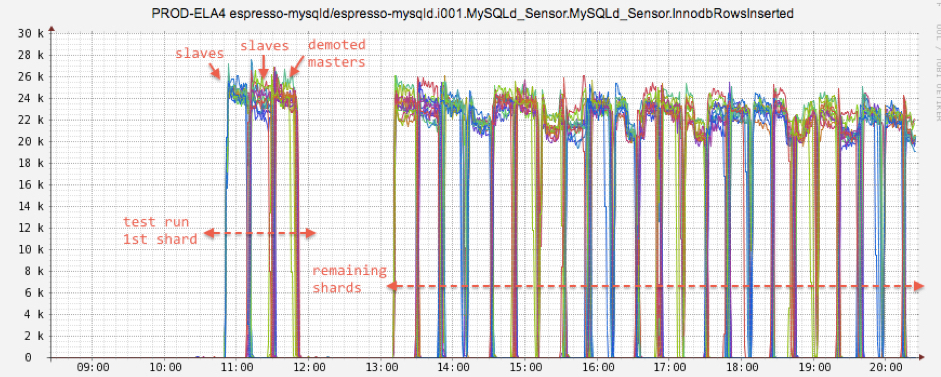
After some trial runs, we were fully confident that each replica could run bulk import with high throughput. There were 12 replica groups (slices) for the InMail cluster. We repeatedly took one node out of each slice for maintenance, effectively loading 12 nodes at a time.
Replaying the Delta Writes
After the bulk load, InMail engineers went back to the Oracle shards to collect the new writes (delta) that have been accumulating from the last ETL point. The amount of the delta writes was relatively low, so the catch up phase involved simply replaying the events to the Espresso router. This was done through a small dedicated cluster that was designed to take the Oracle delta writes and replay them as Espresso requests. Once the catch up was fully complete, the InMail team flipped the switch that made Espresso the source of truth for the newly migrated shards. For safety reasons, the dual-write to Oracle and Espresso were maintained throughout the migration process.
Conclusion
The migration was swift. We’ve migrated 200+ million mailboxes (at the time of migration) in less than three month period while maintaining full availability. At this point, the InMail Oracle instances are fully decommissioned, eliminating complexity, operability problems and costs.
Espresso team has learned what it takes to serve the largest dataset at LinkedIn, and was able to introduce creative optimizations as a result. The experience also showcased that Espresso is ready to take on big challenges. Multiple teams have collaborated as one unit, demonstrating how the culture of valuing teamwork can truly have a business impact.
The InMail migration was a team effort. Many thanks to the Oracle DBA team and InMail team (aka COMM team) for great execution. Numerous engineers in the Espresso team had sleepless nights in coming up with the optimizations and working on the migration. We also would like to thank Alex Vauthey and Greg Arnold for their leadership, and Mammad Zadeh and Ivo Dimitrov for their clear vision and guidance.