A crash course in LinkedIn's global site operations
September 18, 2013
I commute 3000 miles every day. Virtually, of course. LinkedIn's operations team uses technology to help bridge the thousands of miles between our offices all over the world, including Mountain View, New York City, São Paulo, Dublin, Bangalore, and Amsterdam.
 The view from my NYC office (click to enlarge)
The view from my NYC office (click to enlarge)
I recently moved from our headquarters in Mountain View to LinkedIn's new office in New York City, which is much smaller (but growing fast!). At first, I was worried: as a member of the SRE team, my job is to work closely with Software Engineers, other SREs, and management, and I was voluntarily moving across the country from most of them! As it turns out, I had nothing to worry about. In this post, I'd like to take you on a crash course of the technology we use to make it possible for LinkedIn SREs to work remotely or at home.
Chat
The first tool is a classic: IRC. We use IRC all the time: in fact, with all the tooling we have around it, IRC can sometimes be more effective than face-to-face conversations. We have bots that log the channels and archive the discussions on an internal server; we can quickly get someone caught up on a conversation by sending them a timestamped URL. We have a bot that monitors URLs for links to Change Management tickets and Code Review tickets and prompts us to review them. We even have bots that can tell you who's on-call for problems and summon them for you.
 A look at one of the SiteOps IRC channels
A look at one of the SiteOps IRC channels
IRC has been around forever, so if your device has a TCP stack, there's an IRC client for it. You can use it in the office, from home, or on the go, so staying connected is easy.
Video conferencing
IRC is great, but there are still times where you want to see the other people though, and for those occasions, we use BlueJeans. This service is incredibly helpful to us, because you can use it from anywhere across a variety of different platforms. It’s great to be able to use an iPad Mini as a dedicated videoconference device while you go about your work. (Of course, you can also use your computer.) We also have an internal videoconference system that lets us share presentations and remotely move the cameras on either end of the meeting.
We’ve even embraced using this technology for candidates we’re interviewing to join the SRE team in New York: the candidates interview in person with the team members who are here, and then use the videoconference system to interview with other members of the team in Mountain View. This keeps travel time to a minimum, while still giving us all the chance to see and meet the candidate.
Monitoring
Of course, there are plenty of times when you need to get a look at what's happening without talking to anyone at all. As a Site Reliability Engineer, I'm responsible for keeping the LinkedIn site up and knowing what's happening with all of the products and features that I support. One tool we rely on is called inFormed, which contains a running feed of everything that's happened on the site, including software deployments, feature releases, LiX ramps (LinkedIn Experimentation platform, which controls what features are visible to which members), comments people make in IRC, and more. Whenever a problem pops up, inFormed is a good way to answer the question of "what changed?"
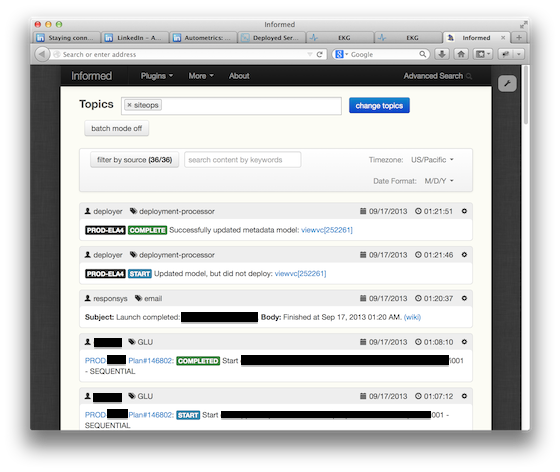 inFormed shows us the deployments and LiX changes happening now
inFormed shows us the deployments and LiX changes happening now
We also make heavy use of inGraphs, a graphing and analytics system that lets us look at dashboards for any part of the site and to compare performance metrics over time. We can dynamically add or delete alerts on these dashboards so that we get notified if some value goes above or below a configurable threshold. These alerts can be triggered based on raw thresholds, change in values since last week, the rate by which the metric is changing, and many other methods.
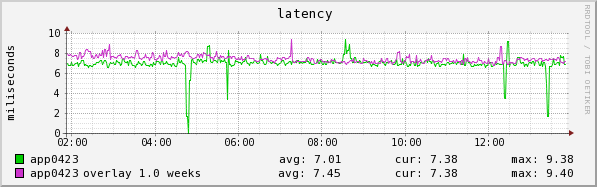 One of the thousands of graphs we can see or generate instantly through inGraphs
One of the thousands of graphs we can see or generate instantly through inGraphs
inGraph alerts can be sent via email, IRC messages, or traditional notification through the NOC (Network Operations Center). In this way, the site communicates with us and tells us what we need to pay attention to, rather than having to constantly check dashboards for important metrics. inGraphs was originally developed by an intern (who now works with us full-time!) and is now the single most important tool we have as SREs. It takes just 5 lines of YAML to configure the live-updating sample graph you see above.
Deployment
In addition to these tools that help us keep eyes on the site, we also have tools that make it easier for us to support our Software Engineers. CRT (Change Request Tracker) lets engineers see the status of all checked-in code, monitor builds, and deploy new code through our continuous deployment system.
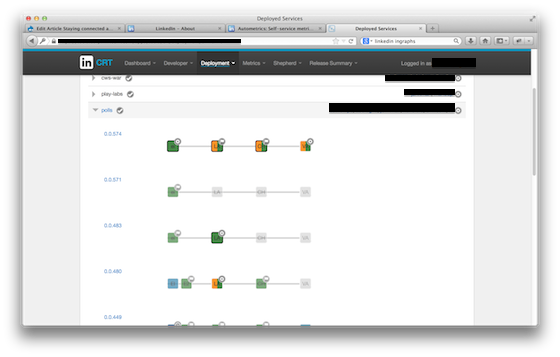 CRT dashboard showing the status of a service across production environments
CRT dashboard showing the status of a service across production environments
When we deploy a new version of a service, we first "canary" the new code on one host to see how it compares to the all the other hosts ("the controls"). We use a tool called EKG to perform this comparison automatically. EKG compares exception counts, network usage, CPU usage, GC performance, service call fanout, and a variety of other metrics between the canary and the control groups, helping to quickly identify any potential issues in the new code.
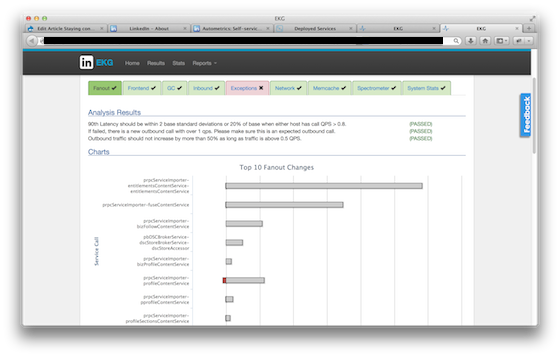 EKG shows a comparison between two versions of a service
EKG shows a comparison between two versions of a service
We've just scratched the surface
This is only a brief survey of the tools available: I haven't even mentioned the manifest app (which helps manage thousands of servers across multiple data centers), JIRA for issue tracking, the hardware request tool, the port registry system, and lots more. Moreover, new tools get written all the time, thanks to Hackday, one day a month where every LinkedIn employee can take the day to work on something cool that helps make themselves or LinkedIn better.
It’s incredible to think of just how easy it is to reach out to the team around the world, thanks to a culture that always considers the remote team members, and technology that makes it effortless to participate and contribute no matter where you are. I’m thrilled to be a pioneer in bringing LinkedIn Engineering to the East Coast, and feel energized and inspired by the city. Our use of technology helps me feel like I’m still part of the team, even across the distance. Come join us and help us build an even more awesome, connected group!