Gobblin' Big Data With Ease
November 25, 2014
The holiday season for gobbling is upon us; and at LinkedIn, we’ve been getting better at gobbling large amounts of different kinds of datasets to feed our data hungry analysts. We thought we’d share with you our most recent efforts at simplifying big data ingestion for Hadoop-based warehouses.

Got Data?
Every day, the LinkedIn platform generates a ton of data which we call our internal datasets. This includes information from members profiles, connections, posts and other activities on the platform (sharing, liking, commenting, viewing and clicking etc) and is in accordance with the LinkedIn's Privacy Policy. This data is persisted in databases and event logging systems. Over the years, our DBAs and data infrastructure engineers have made many innovations in simplifying the extraction of data from our source of truth databases (Oracle, MySQL, Espresso) as periodic incremental dump files as well as continuous change capture streams (Databus). At the same time, we’ve instrumented our application code paths to track all the important events and stream them through our central activity pipeline (Kafka). The combined volume of data that we generate through these pipelines is in hundreds of terabytes a day. Our internal datasets are voluminous and fast moving which requires us to ensure that our ingestion can scale effortlessly and make data available with low latency and on schedule.
In addition to our internal data, we also ingest data from many different external data sources. Some of these data sources are platforms themselves like Salesforce, Google, Facebook and Twitter. Other data sources include external services that we use for marketing purposes. Our external datasets tend to be an order of magnitude smaller in volume than our internal datasets, however we have far less control over their schema evolution, data format, quality and availability, which poses its own set of challenges.
Bringing all these external and internal datasets together into one central data repository for analytics (HDFS) allows for the generation of some really interesting and powerful insights that drive marketing, sales and member-facing data products.
Ingestion complexity can cause Indigestion
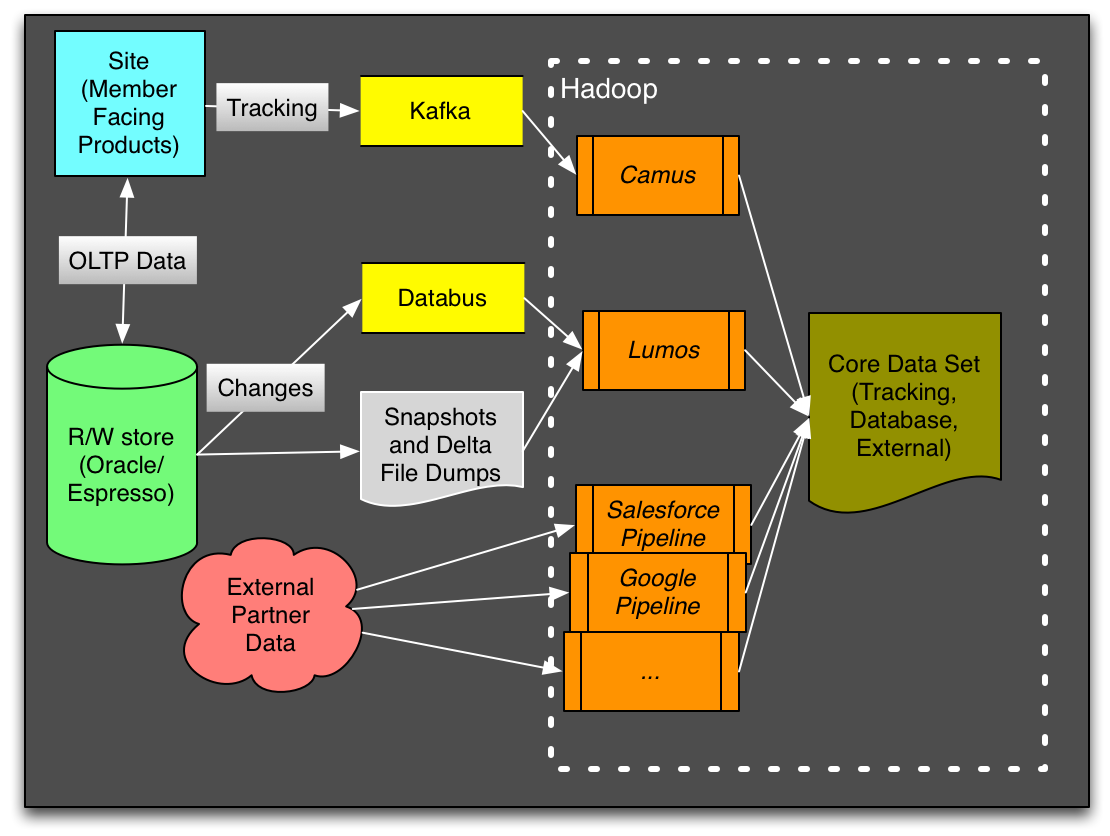
Over the years, LinkedIn’s data management team built efficient solutions for bringing all this data into our Hadoop and Teradata based warehouse. The figure above shows the complexity of the data pipelines. Some of the solutions like our Kafka-etl (Camus), Oracle-etl (Lumos) and Databus-etl pipelines were more generic and could carry different kinds of datasets, others like our Salesforce pipeline were very specific. At one point, we were running more than 15 types of data ingestion pipelines and we were struggling to keep them all functioning at the same level of data quality, features and operability.
Late last year (2013), we took stock of the situation and tried to categorize the diversity of our integrations a little better. We observed four kinds of differences:
- The types of data sources: RDBMS, distributed NoSQL, event streams, log files, etc.;
- The types of data transport protocols: file copies over HTTP or SFTP, JDBC, REST, Kafka, Databus, vendor-specific APIs, etc.;
- The semantics of the data bundles: increments, appends, full dumps, change stream, etc.;
- The types of the data flows: batch, streaming.
We also realized there were some common patterns and requirements:
- Centralized data lake: standardized data formats, directory layouts;
- Standardized catalog of lightweight transformations: security filters, schema evolution, type conversion, etc;
- Data quality measurements and enforcement: schema validation, data audits, etc;
- Scalable ingest: auto-scaling, fault-tolerance, etc.
- Ease of operations: centralized monitoring, enforcement of SLA-s etc;
- Ease of use: self-serve on-boarding of new datasets to minimize time and involvement of engineers.
![]()
We’ve brought these demands together to form the basis for our uber-ingestion framework Gobblin. As the figure below shows, Gobblin is targeted at “gobbling in” all of LinkedIn’s internal and external datasets through a single framework.
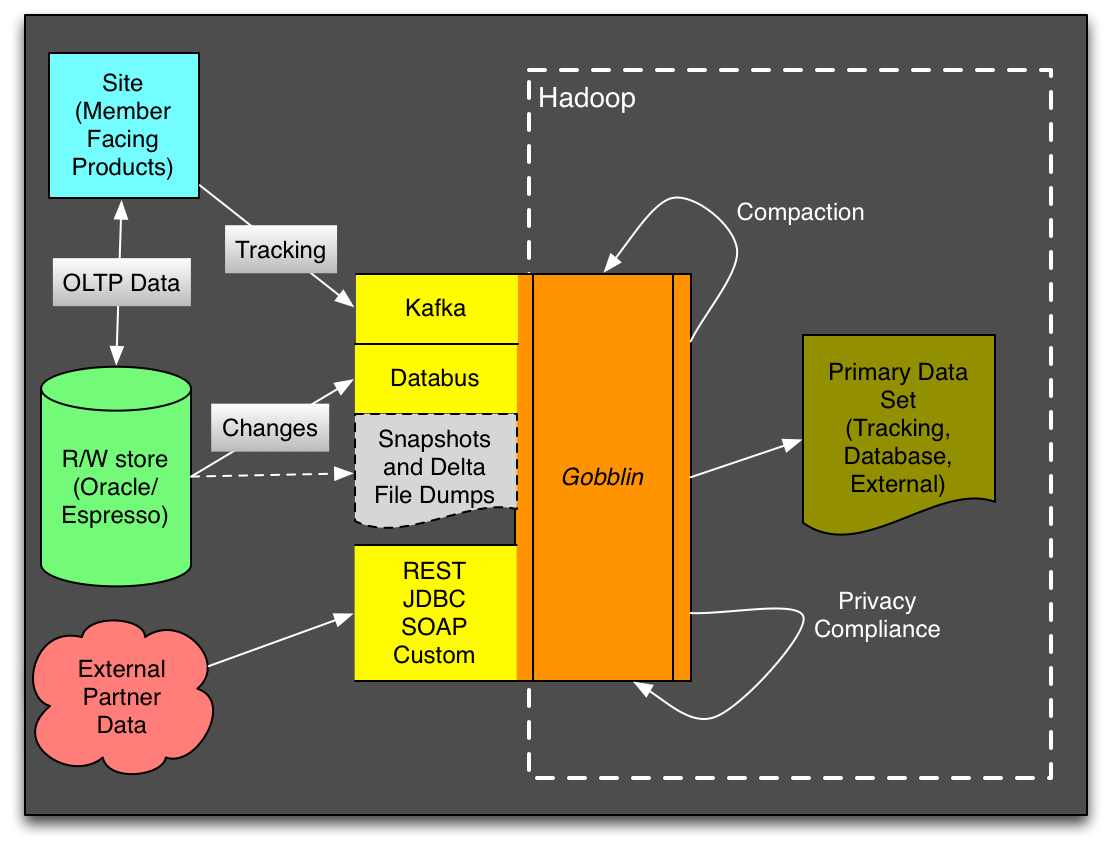
The Road Ahead
We recently presented Gobblin at QConSF 2014 (abstract, slides). We’ve heard a lot of similar pain points around data ingestion into Hadoop, S3 etc when we talk to engineers at different companies, so we’re planning to open source Gobblin in the coming weeks to share an early version with the rest of the community. Gobblin is already processing tens of terabytes of data[1] everyday in production. We’re currently migrating all of our external datasets and small scale internal datasets into Gobblin, helping us harden the internal APIs, the platform and operations. Early next year, we plan to migrate some of our largest internal pipelines into Gobblin as well. Stay tuned for more updates on the engineering blog!
The Gobblin Team
The Gobblin project is under active development by the Data Management team: Chavdar Botev, Henry Cai, Kenneth Goodhope, Lin Qiao, Min Tu, Narasimha Reddy, Sahil Takiar and Yinan Li, with technical guidance from Shirshanka Das. The Data Management team is part of the Data Analytics Infrastructure organization led by Kapil Surlaker and Greg Arnold.
[1] Some of this data is directly ingested from external sources, the remainder is comprised of data brought in by other pipelines and processed regularly by Gobblin for privacy compliance purposes.