Serving Large-scale Batch Computed Data with Project Voldemort
February 25, 2012
LinkedIn has a number of data-driven features, including People You May Know, Jobs you may be interested in, and LinkedIn Skills. Building these features typically involves two phases: (a) offline computation and (b) online serving. As an early adopter of Hadoop, we've been able to scale the offline computation phase successfully. The difficult part has been bulk loading the output of this computation phase into the online serving system without causing performance degradation.
To make all this offline data available to the live site, we've developed a multi-terabyte scale data pipeline from Hadoop to our online serving layer, Project Voldemort. We recently had the opportunity to present the details of this pipeline and extensions to our serving system at FAST 2012:
Serving Large-scale Batch Computed Data with Project Voldemort (PDF)
At a high level, the pipeline has 3 major goals: fast lookup for massive data-sets, quick rollback during errors, and easy expansion.
Fast lookup for massive data-sets
The output generated by Hadoop can run into the terabytes. The figure below shows a high level overview of the full pipeline. This is executed concurrently by multiple features, pulling around 4 TBs of data every day to our live-serving Voldemort cluster. We use Azkaban, an open-source scheduler from LinkedIn, to coordinate the pipeline:
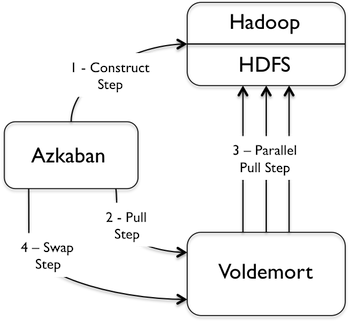
The pipeline consists of 3 phases:
- Construct step: we run an extra MapReduce job to transform the output of a Hadoop job into a highly-optimized custom data and index format, saving the results onto HDFS.
- Pull step: Voldemort pulls the data and indexes from HDFS.
- Swap step: the indexes are memory mapped for serving, leveraging the operating system's page cache to provide quick lookups.
Quick rollback during errors
Iterating on our data features is a crucial part of our product ecosystem. This can result in a situation wherein errant data is loaded due to a bug. We do not want to rely on the long pull process to come out of this error state. To minimize the time in error, our storage engine has the ability to do instantaneous rollback to a previous good state.
Easy expansion
As the member base and traffic grows, the data to memory ratio will change, resulting in performance degradation over time. With this in mind, we wrote a new storage engine for Voldemort that makes it easy to add capacity without any downtime.
Learn more
We've been running this system successfully for the past 2 years. To learn more about the implementation details, check out the following resources:
- Paper (PDF)
- Slides (PDF)
- Video
- Source code