Announcing the Voldemort 1.9.0 Open Source Release
September 30, 2014
I am really excited to announce the general availability of the Voldemort 1.9.0 open source release. Voldemort has been a cornerstone of LinkedIn's infrastructure and continues to power a vast portion of LinkedIn's services. As our footprint has grown bigger, one of the key areas of our focus has been around adding features that improve the operability of Voldemort clusters. This post details some of the new features & enhancements that we have made since our last release.
- New Features: Zone clipping, Quotas support, New admin tool
- Enhancements: Auto purging slops, Tehuti metrics, Gradle support, Split store definitions, Client performance/stability improvements.
New Features
Zone Clipping
Voldemort supports topology aware replication that is built on the idea of "zones". A zone is a group of nodes very close to each other in a network. For example, all the nodes in a rack or even all nodes in a data center could be a single zone. As part of the last release we had added zone expansion capability to Voldemort. In this release, I am pleased to announce zone clipping capability to Voldemort which enables removing nodes and data of one entire zone from a zoned Voldemort cluster.
Zone clipping is a metadata operation that generates new metadata so that the replication set of all data stays unchanged in non-clipped zones. It is done by shifting the partition of nodes in the clipped zone to the next server in the replication set of that zone that is not in the clipped zone. This ensures that while partitions are reassigned no real data movement occurs. We coded this algorithm into a tool named ZoneClipperCLI which takes in a source, cluster.xml and stores.xml, and generates a final-cluster.xml and final-stores.xml after dropping the desired zone.
Here is a diagram explaining zone clipping in a simplified use case where replication factor is 1 per zone. A Consistent hash ring represents the layout of partitions, servers and zones in a Voldemort Cluster. Routing in Voldemort is based off this single consistent hash ring. In the diagram below, the left consistent hash ring depicts the state of the cluster before Zone Clipping and the right ring represents the cluster after clipping zone Zone-1. The partitions (here P1..P6) are contiguous. These partitions are assigned to servers S1..S6. The servers are divided into zones - Zone-0, Zone-1 and Zone-2. Notice that partition P2 is associated with server S3 and partition P5 with Server S6 after applying the zone clipping algorithm. Though there seems to be some imbalance in partitions assignment in this simplified use case, in a more real use case, where there are enough partitions, the zone clipping algorithm ensures a uniform assignment of partitions to the servers.
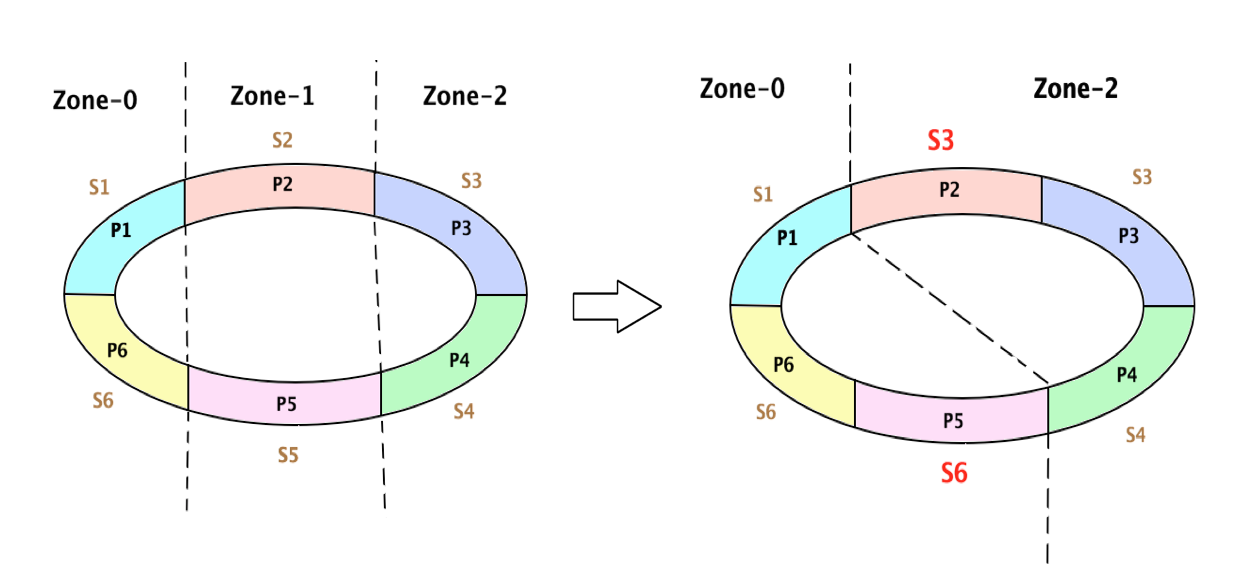 Figure 1: Simplified Zone Clipping with Replication Factor 1 per Zone
Figure 1: Simplified Zone Clipping with Replication Factor 1 per Zone
Quotas Support
A Voldemort cluster currently supports multiple apps with varied workload characteristics. In a multi-tenant scenario, misbehaving or high-demand tenants (also referred to as Voldemort stores) can overload the shared service and disrupt other well-behaved tenants, leading to unpredictable performance and violating SLAs. To tackle such scenarios, we had to enforce quota limits on the read and write operations, derived from policies set by Voldemort admins, on an underlying Voldemort store in production. Towards that end, we added support for quotas at the Voldemort server level in this release.
While PUT and DELETE operations constitute the write quota, GET and GetALL make up for the read quota (each key in GetALL is counted as a single read). The GetVersion operation isn't counted against any quota. The admin tool has been extended to support commands to set/unset quota on a specific Voldemort store.
In future releases we also plan to add support for quotas at the coordinator layer and support quotas for other resources like connections.
New Admin Tool
Voldemort Admin Tool, as the name implies, is a command-line interface for issuing admin commands to the cluster. The admin tool has been growing organically with all the commands organized in a flat structure making it difficult to use and extend. With this release we introduced a completely rewritten admin tool, named VAdminTool, that organizes the commands in a group and subgroup pattern leading to shorter and more intuitive command and option names. Among other things, the new admin tool also has features to: check for conflicting options, display command summaries and atomically update cluster.xml and stores.xml in one command.
The older admin tool continues to exist and will be phased out in a future release.
Enhancements
Auto Purging Dead Slops
Voldemort uses hinted hand-off mechanism for data reconciliation when a server is recovering from failure. During the time a server is down, one of the alive servers in the cluster holds the data for the failed server in a special slop store. The alive server periodically checks if the failed server has recovered and attempts to stream the slops to the recovering server.
In a multi-hours failure scenario, slops can build up and can lead to a node run out of disk space. Further, in circumstances where a zone is being decommissioned, slops can accumulate on surviving nodes for nodes that are being decommissioned. Since the decommissioned nodes are never going to come back, holding slops for them is inefficient. To handle such scenarios, in this release we implemented the capability to auto purge dead slops. When an alive server finds out that the slop that it is holding is for a node that doesn't belong to the current cluster it purges that slop. This feature has also been exposed as an admin operation.
Tehuti Metrics
Accurate metrics are an essential part of operating a system at production scale. Over the last couple of years, Voldemort’s core parts have been well instrumented and the overall operational visibility has been continuously improving. Even then, our implementations of Histograms and Counters have had a lot of room for improvement.
For example, the old histogram implementation returns information from a single sample window, which periodically gets cleared. It is possible to see erratic spikes when reading a histogram measurement shortly after the sample window is cleared. While we implemented support for quotas, we repeatedly ran into false alarms due to this. The new histogram implementation takes a sliding window approach, thus eliminating the risk for disproportionately small samples that can lead to false alarms.
Secondly, we also realized the need for a finer granularity of the metrics. The old histogram implementation rounds down to the lower 100 microseconds granularity when under 1 second, and to the lower second when under 10 seconds. The new histogram implementation uses a linearly-scaled granularity to provide more fine-grained results in the lower scale of the histogram, and gradually coarser-grained results in the higher scale, while still using the same amount of memory (around 40K per histogram). Here is a diagram showing data measured from a host running the new histogram code versus one running the old code. The scale is in microseconds.
 Figure 2: Data measured from a host running new Histogram implementation (in blue) vs one running old one (in red). We can see that the red one is rounded down and less precise.
Figure 2: Data measured from a host running new Histogram implementation (in blue) vs one running old one (in red). We can see that the red one is rounded down and less precise.
Finally, the old implementation uses lock-less code which drops data after three failed attempts to record a data point. The new implementation uses synchronization and never drops data points. We tested this using synthetic traffic and then in production and found the performance to be similar, suggesting the lock-less code was an unnecessary optimization at the expense of correctness.
Tehuti is the name of the new metrics library which better handles all of the above issues. The Voldemort RequestCounter class has been rewritten to leverage the Tehuti metrics library. Tehuti itself has been pulled out from Apache Kafka into a stand alone project, and improvements have been contributed to it since. In the future, we plan to distribute Tehuti through a Maven repository so that other projects can make use of it more easily.
Build system migration to Gradle
Gradle support and Voldemort jars in Maven Central are the two most requested features from the open source community. With this release, we have officially moved to Gradle from the Ant build system. Ant has been deprecated and its support may be removed in future releases. As part of this migration we have ensured that jars built with Gradle have binary compatibility with those built with Ant.
Voldemort, up until the last release, had its own copy of all dependent jars. In this release, except for certain private lib dependencies, we are relying on Maven Central to pull in the jars. Support has also been added to Gradle to regenerate the Eclipse/IDEA project files to work seamlessly with Maven Central and private dependencies. We have been collaborating with the open source community to remove the rest of the private dependencies and we plan to eventually make all the Voldemort jars available in the Maven Central repository.
Split Store Definitions
One of the three configuration files that control server operation is stores.xml (the other two being cluster.xml and server.properties). The stores.xml holds information about the stores (i.e Tables) like name, key schema, value schema, required and preferred reads, required and preferred writes and so on.
Historically, stores.xml has been a single file. As we scaled Voldemort at LinkedIn, we realized that managing a huge monolithic metadata structure isn't scalable. With a single big xml file, for example, two competing admin operations could clobber each other.
With this release we have changed that behavior. The new server on start up will split each store definition in its own individual xml file under a 'STORES' directory. New clients can bootstrap using the store name instead of specifying the 'stores.xml' key in the metadata store. To preserve backwards compatibility, for older clients, the server will stitch together the individual store definitions to form a single big stores.xml.
Note that once the server has split the store definitions, all operations work against the STORES directory and the original stores.xml will never be used. The recommended steps for rollout are:
- Roll out the new server release and observe the health of the server.
- If things look healthy, manually delete the old stores.xml from each of the servers to avoid any confusion.
Client and Coordinator Fixes
As part of our ongoing effort to improve client and coordinator layer we have rolled out a slew of fixes and improvements as part of this release.
- DELETE operations now register slops more faithfully and use GetVersion instead of GET, potentially avoiding costly network fetch.
- Coordinator service now boasts much faster vector clock serialization code.
- Parallel request exceptions are registered more faithfully to the failure detector.
- Fixed race conditions associated with incorrect metrics mbeans registration.
- Fixed race conditions inside FailureDetector to keep correct count of Metrics and incorrectly marking a node up when it is down.
- Fixed connection cleanup when the first request on a connection fails.
Contributors
Many hands contributed to this release: Arunachalam Thirupathi, Bhavani Sudha Saktheeswaran, Chinmay Soman, Felix GV, Lei Gao, Mammad Zadeh, Siddharth Singh, Vinoth Chandar, Xu Ha, Zhongjie Wu
And special thanks to our SREs who work tirelessly to keep the lights on: Amit Balode, Brendan Harris, Greg Banks, Tofig Suleymanov
Call for contribution
As always, we are actively looking for people from the open source community to contribute to Voldemort. If you are interested in helping us out or want to share your ideas or have questions, please check out the Project Voldemort forum.