Announcing the Voldemort 1.6.0 Open Source Release
January 31, 2014
We are happy to announce the general availability of the Voldemort 1.6.0 Open Source release. Voldemort is a distributed key-value storage system developed at LinkedIn, where data is automatically replicated and partitioned over multiple servers. The system employs a quorum-style replication that offers high availability and no central point of failure or coordination.
The Voldemort team has made significant improvements since the last release and reached the biggest milestone yet at LinkedIn, by serving 1 million operations per second summed over multiple zones across 300+ nodes.
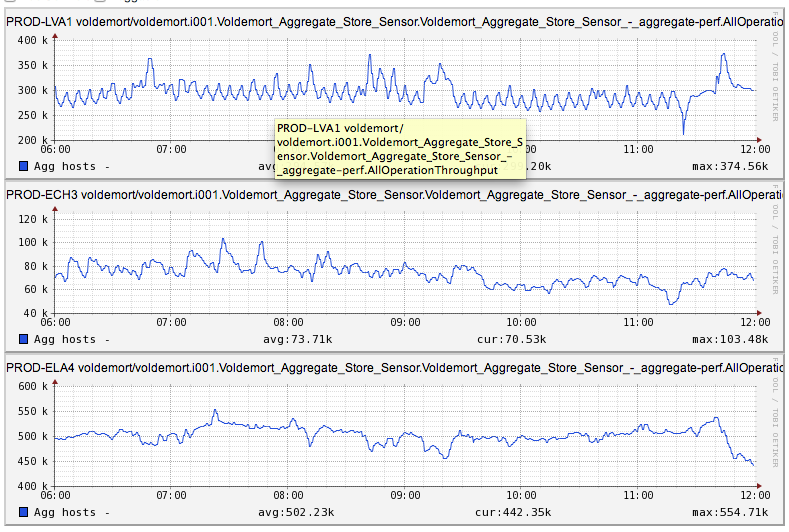 Figure 1: Operations/second across zones
Figure 1: Operations/second across zones
In this post, I'll discuss new features and enhancements:
- New features: zone-expansion capability with abortable rebalance, new tools for zone-expansion, addition of coordinator and thin client.
- Major changes: removed donor-based rebalancing, upgraded to BDB-JE 5 (Please note that you would need to follow upgrade procedure described here, before switching the servers over) , and ZenStoreClient is enabled by default.
New features
Zone-expansion capability with abortable rebalance
Voldemort supports topology aware replication that is built on the idea of "zones". A zone is a group of nodes very close to each other in a network. For example, all the nodes in a rack or even all nodes in a datacenter could be a single zone. A scalable system should allow for new zones to be added (zone-expansion). In this release, we have added that capability to Voldemort.
The highlight of the zone-expansion feature is a new concept called Proxy-Put that allows you to abort a rebalance safely. The basic idea is that puts issued during the rebalancing operation will be cloned to the donor node (the node that is giving away the partition) by the stealer node (the node that is receiving the partition). If the operation is aborted, no data loss occurs because the donor node has a copy of the data. The data sent to the stealer node, before the rebalance operation was aborted, can be deleted later by running a repair job.
New tools for zone-expansion
We also made improvements to cluster-expansion and rebalancing and introduced an array of rebalance tools:
- PartitionAnalysis: Analyzes the partition layout of a cluster, based on storage definitions, to determine its balance. The balance is measured in terms of "utility value", which needs to be minimized. The utility function has multipliers for balancing capacity versus IOPS. Currently, we bias towards balancing capacity, but this behavior can be modified with minor code change.
- Repartitioner: Shuffles partitions around to achieve a better balanced cluster either by using a greedy or a random swap. In both strategies, the repartitioner makes progress by swapping a primary partition with another node's primary partition and checking if the swap improves balance: if it doesn't, the swap is rejected. The tool performs a certain number of attempts (controlled by
max-attemptsparameter) and then outputs a more balanced cluster topology. The cluster can then be rebalanced. - RebalancePlanner: Generates a plan to achieve a target cluster topology from an initial cluster topology. It also prints operational insights into the storage overhead and the probability of a client picking up the new cluster metadata. This information helps in advanced planning and to confirm there is adequate storage capacity for the rebalance.
- Consistency checker: An administrative tool to fix data inconsistency due to partial writes or the read-repair mechanism not being able to consolidate versions. The tool checks for one or more partitions corresponding to a store in a cluster, and should be run occasionally to make sure that all data is consistent. Bad keys are saved in a file and can be fixed by running the consistency repair tool.
Coordinator and Thin Client
We are releasing two new components — the Coordinator service and a thin client that will allow a leaner way of communicating with Voldemort. Together, they provide a better alternative to the fat client mechanism ZenStoreClient, which has numerous issues.
- Coordinator service: Acts as a REST end-point for the thin client. It handles the routing, replication, hinted-handoff and read-repair on behalf of the thin client. In addition, it automatically tracks changes in the cluster topology, making the applications transparent to these modifications. The Coordinator service is built on top of Netty and is very easy to scale due to its stateless nature.
- Thin client: We replaced the existing client with a Java-based thin client which can be embedded in any application that wants to use Voldemort. It has a similar interface as the existing client for continuity. Users will only need to replace
SocketStoreClientFactorywithRESTClientFactoryin the application. In addition to managing compression and serialization, it translates the Voldemort requests made by the application into REST requests for the Coordinator.
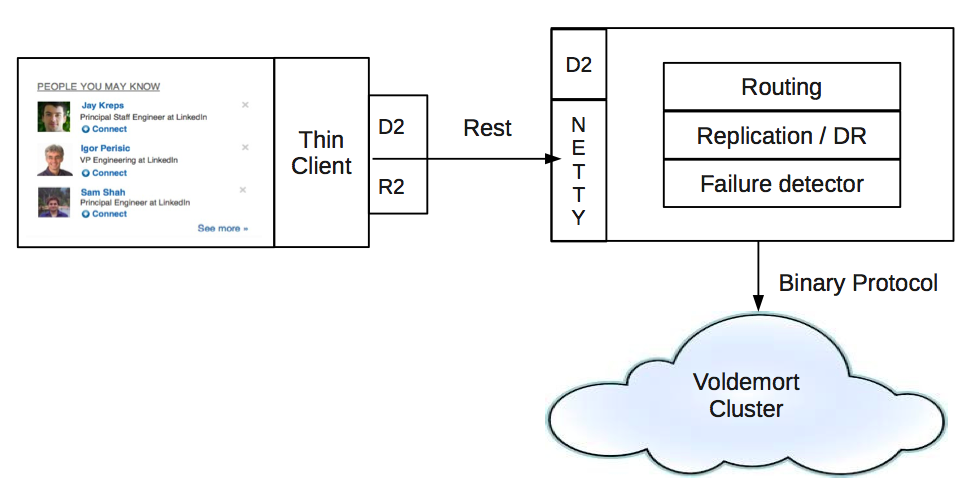 Figure 2: Thin Client and Coordinator Architecture
Figure 2: Thin Client and Coordinator Architecture
R2 and D2 components in the diagram refer to the request/response (R2) API and dynamic discovery (D2) system that are part of rest.li. Request/Response (R2) API includes abstractions for REST and RPC requests and responses, filter chains for customized processing, and transport abstraction. Dynamic Discovery (D2) is a publish-subscribe mechanism that rest.li uses to make rest.li clients “know” what servers can serve a particular resource.
Major Changes
Donor-based rebalancing
Voldemort no longer supports donor-based rebalancing, based on the google group discussion with the Voldemort community. With the addition of storage engines that support partition scans, stealer-based rebalancing had become more efficient than donor-based rebalancing and had clearer progress metering.
BDB-JE Upgrade
Voldemort now uses BDB 5.0.88. The upgrade offers better performance for large databases where index does not fit in memory. Being on a recent version also makes it easier for us to keep working closely with the SleepyCat team at Oracle.
ZenStoreClient enabled by default
ZenStoreClient is now enabled by default for users who want to continue using the fat client mechanism instead of the Coordinator service and thin client. In the Voldemort 1.3.0 release, we had implemented the ZenStoreClient wrapper around DefaultStoreClient, to auto sync client metadata with the server. An AsyncMetadataVersionManager thread on the client constantly checks the metadata version that is persisted in the Voldemort system store on the server, and updates the local state as needed. Given the benefits, we recommended that our product teams switch to ZenStoreClient, . ZenStoreClient is now set as the default, but note that it is more resource intensive and should be used judiciously.
Other improvements
Robust Slop Registration: This release features a robust and rewritten hinted handoff strategy. Hinted handoff is a fairly well-known technique for dealing with node failures in an eventually consistent system. The basic idea is that in case of a node failure, neighboring nodes temporarily take over storage operations for the failed node. When the failed node returns to the cluster, the neighboring nodes hand off the collected updates. Before this release, Voldemort's hinted handoff strategy was prone to write loss due to a race condition in the client when processing server responses. In this release, we eliminated the race condition by synchronizing response processing logic in the client.
Prune Job: Voldemort supports a "versioned" put interface, where the user can include a vector clock, generated outside of Voldemort, by adding a vector clock with entries for all current replicas of a key with the timestamp as the value. For example, if a key replicates to A,B servers, then the put issued at time t1, will be [A:t1, B:t1]. The problem with this approach is that after rebalancing, the replicas might change and subsequent "versioned" puts will conflict with old versions, leading to disk bloat. For example, if the key now replicates to C,D servers, then the put issued at time t2, will be [C:t2, D:t2]. This conflicts with [A:t1, B:t1] and the space occupied by the old version is never reclaimed. This new tool sifts through all data for a store and fixes multiple versions, by pruning vector clocks to contain entries only for current replicas.
Zone Affinity: Voldemort clients can now specify that the get, put, and getall operation should only be blocked while waiting for responses from nodes that are in the zone local to the client. This new feature is called "Zone Affinity" and is exposed as part of the clientConfig object. It makes fail-fast possible by disallowing blocking on cross-data-center operations.
New Metrics : System metrics are crucial for monitoring system health and improving server performance. This release presents a new set of server-side and client-side metrics. On the client-side, we now have metrics on sync and async operation times, connection establishment time, number of connection exceptions and bootstrap stats. This granularity allows greater visibility into client and operational latency and can be extremely helpful in debugging.
On the server side, we added monitoring for Get Versions and BDB environment stats on caching, IO, cleaning and checkpointing, latching and locking, exception, etc.
Client Shell support for Avro data: With Avro popular both at LinkedIn and elsewhere, we added Avro support to the client shell.
Improved Failure Detector: This release features a new threshold-based failure detector, that builds upon the AsyncRecoveryFailureDetector and provides a more lenient method for marking nodes as unavailable. Fundamentally, for each node, the ThresholdFailureDetector keeps track of a "success ratio", which is the ratio of successful operations to total operations and requires that ratio to meet or exceed a threshold. As the success ratio threshold continues to exceed the threshold, the node will be considered available. Once the success ratio dips below the threshold, the node is marked as unavailable.
A minimum number of requests must occur before the success ratio is checked against the threshold, to account for situations where 1 failure out of 1 attempt yields a success ratio of 0%. The success ratio for a given node is reset after the threshold interval to prevent scenarios where 10 million successful requests overshadow a subsequent stream of 10K failures.
Bug Fixes: This release includes important bug fixes in read-repair code to make read-repairs more efficient. It also includes a bug fix in vector clock comparison.
Call for contributions
Operating a large-scale distributed system guarantees many interesting challenges. About one fifth of LinkedIn services directly call Voldemort and that number is continually growing. Voldemort's footprint outside of LinkedIn has been equally strong with a number of organizations using Voldemort to power their critical applications. If you would like to join us to work on the questions that need to be answered — or if you can't join us full time, but would like to help with one or more projects, check out the Project Voldemort Forum.
Many hands contributed to this release: Abhinay Nagpal, Amy Tang, Bhavani Sudha Saktheeswaran, Brendan Harris, Chinmay Soman, Jay Wylie, Lei Gao, Mammad Zadeh, Siddharth Singh, Tofig Suleymanov, Vinoth Chandar, Zhongjie Wu.
We encourage you to upgrade to this new version and post your feedback on the forum or file a bug report on github.