Building LinkedIn University Pages
August 26, 2013
Last week, LinkedIn launched a new product that will drastically change the way alumni and students will interact with the site: LinkedIn University Pages.
This product was only possible due to LinkedIn's unique data and architecture. Over the past few years, we’ve been standardizing data for tens of thousands of schools worldwide. We combined this educational data with the career data and network graph of 238+ million members to build a powerful and compelling experience.
In this post, I’ll survey the engineering that goes into a modern LinkedIn product like University Pages, including the storage systems, data processing pipeline, RESTful APIs, and UI and search technologies.
Architecture

Overview
Here's an outline of the technologies behind University Pages:
- Data: we built data standardization, auto-follows, similar schools, and notable alumni calculations using Hadoop, Azkaban, and Pig scripts.
- Storage: we modeled school data as a graph and stored it within Espresso DB.
- Search: we built search indices and search services on top of this data using Bobo and Zoie.
- REST: we exposed this data through RESTful APIs built on top of Rest.li.
- Feed: the school status updates feed is powered by our content serving platform (USCP).
- UI: we send this data to the browser as JSON and render it client side with dust.js.
Data Layer
When describing our education data model, we should first talk about our work standardizing LinkedIn’s school data. For a few years now, the data scientists on the Higher Education team have waded through 238+ million member profiles to create a standardized list of more than 23,000 institutions worldwide. Our search service indexes this data using Bobo and Zoie, and we send continual real-time updates using Databus.
To surface this standardized school information to our University Pages (and across LinkedIn), we decided to model the data as a graph. We have schools as the main entity with edges to members who follow them, members who are admins, associated fields of study, or edges to other schools as children or parents. This way, we can assemble complex documents and display as a simple query. For example, to fetch all related schools we can use one single graph query.

School relationships modeled as a graph
We also use Hadoop clusters to create some of our unique data insights like Similar schools and Notable Alumni. These offline jobs crunch frequently and populate Voldemort stores.
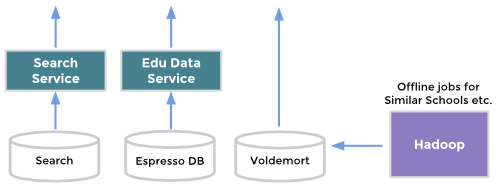
University Pages are powered by many different data sources
Middle Tier
For the middle layer, we built services that expose RESTful APIs. Not only are our endpoints used by University Pages, but they are also used across LinkedIn by a number of heavy hitters like Search, Typeahead, Profile, and Home Page. Therefore, we needed to scale to thousands of queries per second. Fortunately, we were able to leverage our Rest.li framework to get this discoverability and scalability out of the box.

Fetching school data using Rest.li’s builder pattern
Presentation Tier
Just like the New Profile, University Pages are built using dust.js client side templates, our Fizzy UI aggregation layer, and frontend JSON endpoints.
We structure our University Page with multiple UI “embeds” and corresponding JSON endpoints for each one.

We then let our Fizzy UI aggregation layer make parallel calls to JSON endpoints in our School web app to stitch the page together.
Structuring our page this way provides many benefits. First, we can easily re-use our JSON endpoints and any UI embed. Take a look at our LinkedIn for Education home page to see this reuse in action with the career outcomes module.
Another benefit is improved performance. We can leverage our Fizzy aggregation layer to fetch different parts of the page in parallel. Letting Fizzy fetch in parallel also provides progressive rendering on the client and the option for us to defer fetching/rendering if the embed is below the fold.
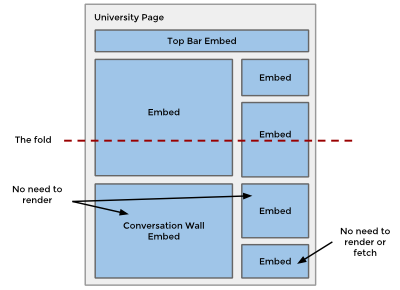
Fizzy provides flexibility in how the page is constructed on the client
Conversation Wall
For the University Page conversation wall, our team worked with LinkedIn’s USCP team to build out a brand new and reusable activity feed infrastructure. USCP is the framework responsible for serving all the status content, feeds, likes, and comments across LinkedIn.
On the front-end, we created reusable Dust client templates and Javascript to enable social gestures like sharing, commenting, and liking. We then created a new set of common sharing endpoints to handle these social actions.

SEO
We wanted University Pages to be indexed by search engines, so we had to have a way to render the page without relying on JavaScript. To solve this, we use Fizzy to render our Dust templates on our servers. Fizzy is an in-house Apache Traffic Server plugin that uses the V8 JavaScript engine to render dust.js server-side and return HTML.
Ramping and Dark Launching
LinkedIn’s new products are released to production in a hidden state for many weeks or months before the general public can see them. We use a system called LiX (LinkedIn experiments) to guard new features, guard new infrastructure, and run A/B tests. LiX has the capability to target access across many different factors like member ID, location, language, groups you are in, or connection counts.
University Pages utilized this dark-launch approach to turn on the product early to a subset of users, namely LinkedIn employees and select school administrators. This early access allowed us to iterate and improve the product, while exercising all the new architectural components listed above - setting the stage for a smooth launch.
Key Features
Let's take a look at how we created a few of the key features in University Pages: Career Outcomes, Targeted Status Updates, Notable Alumni, and the Gallery.
Career Outcomes

Building on top of the flexible Alumni finder, the University Pages feature career outcome data. LinkedIn is unique in that we have millions of members' career outcomes and we can link that information with where they went to school. Since it’s powered by our search technologies like Bobo, you can drill down by many facets like location, skills, and degree. Look for us to build out more powerful tools on top of this data in the future.
Targeted status updates
To provide a powerful tool for schools, we built a way for school administrators to target their status updates to a specific group of followers. To build a system like this, we needed a number of components like:
- Auto-follow members who have a school on their profile
- Index members across numerous education and other facets
- Filter status updates in users’ feeds
- A powerful UI for admins to select their targeting criteria
For auto-following, we used Hadoop to crawl our member base to extract education information. We then later loaded that follow information as an edge off our school entity. With hundreds of millions of users on LinkedIn, this was not a quick task. Our DB was under a very heavy load for multiple days.
For member indexing, we worked with LinkedIn’s search and member recommendation teams to load all education information in their index. In addition, we worked within Lucene to create a custom overlap query, so that we could target members of a particular graduation year, field of study, or degree.
Notable Alumni
One of the more engaging features on the University page, Notable Alumni, surfaces alumni on LinkedIn that went on to do great things. The algorithm powering the list heavily uses our career outcomes data (plus other LinkedIn secret sauce). We run this Hadoop job every few weeks to keep the data fresh, while directly loading it into our final school data graph.
The best part of this module is that the original idea came from one of LinkedIn’s hackdays; the team liked the idea so much that we added it to the final product.
Gallery
Lastly, University Pages feature a gallery of photos or videos. The Higher Education team worked with the Profile team to integrate the same system that powers Profile’s rich media repository. We store all the media within SlideShare data stores, while providing tools to extract content, titles, descriptions, or keywords from video, photos or links.
Powerful Data, Powerful Frameworks
And there you have it. LinkedIn is one of the only companies in the world that could have built University Pages due to its unique data set, analytics abilities, user base, and front to back stack.