Benchmarking Apache Samza: 1.2 million messages per second on a single node
August 24, 2015
Apache Samza has been run in production and is used by many LinkedIn services to solve a variety of stream processing scenarios. For example, we use it for application and system monitoring, or to track user behavior for improving feed relevance. The objective of this study was to measure Samza's performance in terms of the message-processing rate for a single machine. This benchmark will help engineers to understand and to optimize performance and provide a basis for establishing a capacity model to run Samza platform as a service.
Note: the performance numbers given here are only for reference and by no means a comprehensive performance evaluation of Samza; performance numbers can vary depending on different configurations or different use cases.
Apache Samza Overview

LinkedIn’s Samza engineering team has previously posted about Apache Samza. Samza is a distributed streaming computation processing framework that was originally created at LinkedIn to serve developers near-real time computations. Samza, by default, consumes and produces to Apache Kafka, which LinkedIn uses extensively to drive real-time updates of services.
Samza ships with two types of key-value stores (in-memory and RocksDB) to support stateful processing to buffer message streams. The in-memory store is an internally created Java TreeMap. RocksDB is a persistent key-value store designed and maintained by Facebook for flash storage. To support fault tolerance of local key-value stores, Samza can also use a durable Kafka changelog topic to capture the changes in each key-value store. Replaying the complete Kafka changelog topic allows Samza to restore the key-value store in any other nodes in the cluster. A high-level Samza architecture looks like the following example:

Samza uses a single thread to handle reading and writing messages, flushing metrics, checkpointing, windowing, and so on. The Samza container creates an associated task to process the messages of each input stream topic partition. The Samza container chooses a message from input stream partitions in a round-robin way and passes the message to the related task. If the Samza container uses stateful management, each task creates one partition in the store to buffer messages. If the changelog option is enabled, each task sends the changelog stream to Kafka for durability purposes. Each task can emit messages to output stream topics, depending on the use case.
Scenarios For Benchmarking Samza
The following tests were run on the Samza 0.9 release. The benchmark Samza jobs cover four typical Samza scenarios:
- Message Passing: A Samza job which consumes messages from a source topic and those messages are immediately written to a destination topic.
- Key Counting with In-Memory State Store: A Samza job which processes incoming messages and stores the results in the built in In-memory store.
- Key Counting with RocksDB State Store: A Samza job which processes incoming messages and stores the results in a RocksDB (local disk based) store.
- Key Counting with RocksDB State Store and Persistent Changelog: A Samza job which processes incoming messages and stores the results in a RocksDB store which is backed up with a Kafka based Changelog Topic.
The Setup
For these tests, we used a single dedicated machine that has the following attributes:
- Intel Xeon 2.67 GHz processor with 24 cores
- 48GB of RAM
- 1Gbps Ethernet
- 1.65TB Fusion-IO SSD
Samza’s job performance depends on the average message size of an input stream topic. To create a repeatable test scenario, we created a Kafka topic with synthetic data to ensure that all the tests process the same set of messages. We used the Kafka console producer to produce 10 million small records (around 100 bytes) to the topic.
How We Measured Key Metrics
By default, Samza framework collects various performance metrics for the running Samza job, including metrics for Samza container, metrics for System consumer and System producer, metrics for key-value store operations, and more.
In our tests, we use process-envelopes as the key metric to measure Samza job throughput. Process-envelopes metric is used to measure message-processing rate that indicates how fast Samza processes the input stream messages.
At LinkedIn, we use a monitoring tool called inGraph to monitor these performance metrics. When the job starts, these performance metrics are emitted to Kafka and later consumed by inGraph. The services within LinkedIn could easily monitor Samza job performance through inGraphs.
Test Results
Message Passing Throughput
The job we benchmarked consumes messages from an input stream topic and immediately redirects the messages to a different output stream (Kafka) topic. The goal was to test the system consumer and system producer as a transducer without buffering any state. Samza 0.9 uses the new Kafka asynchronous producer which is expected to produce messages faster. The incoming messages have been serialized with Samza’s string serializer through wire. For details on the configs for this test, please refer here.
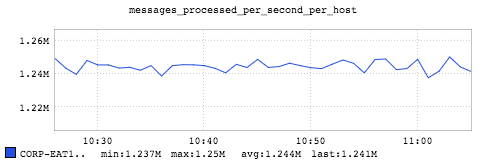
The above figure shows that the maximum throughput out of a single machine for this job is about 1.2 million messages per second with 15 containers. To clarify, first, we run multiple containers in the test because we want to make a fair comparison with the other multithreaded streaming system at machine level since Samza is single-threaded. Second, we found that a parallelism factor of 15 containers is what it takes to generate a maximum throughput out of a single machine for this scenario.
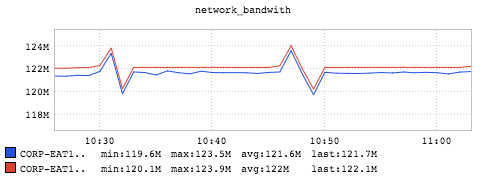
The above figure shows the network bandwidth for incoming traffic (red) and outgoing traffic (blue) for the machine during the timespan. As we have identical messages, the average network bandwidth usage of the machine is similar for incoming traffic and outgoing traffic, which is about 122 megabytes per second (976 megabits per second). The machine only has a 1 gigabit NIC, and we won't be able to use the full bandwidth of the NIC because the packet transmission has overhead. If we do the simple math, we get: ~1.2million * 100 bytes * 8 = ~ 1 gigabit. We saturate the 1 gigabit NIC with incoming messages. The benchmark here is solely focused on testing the single-machine throughput of Samza. But nothing prevents us from scaling up the throughput of a Samza job in a distributed cluster by adding more machines to run more containers.
Key Counting with In-Memory State Store Throughput
This Samza job extracts keys from the incoming messages, performs a word count on the keys, and stores it in Samza’s in-memory store. It also performs periodic cleanups in the window task to avoid the memory from completely filling up with messages. To use an in-memory store, we need to specify “stores.store-name.factory” in Samza configuration as “org.apache.samza.storage.kv.inmemory.InMemoryKeyValueStorageEngineFactory". The code and config of this Samza job could be found here.
Samza’s in-memory store is provided for users who have a small amount of state for the streaming requirements and can fit well in in-memory. Otherwise, the Samza container’s JVM performs full GC frequently when data fills the heap. This significantly degrades the query latency. Users can monitor JVM performance metrics, such as total time spent in GC, reported by Samza for performance diagnosis.
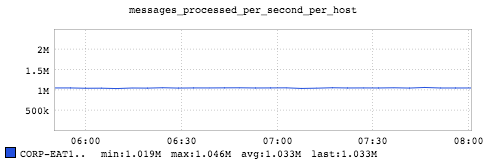
The maximum throughput out of a single machine for this test is about 1.0 million messages per second. Here we almost max out the available memory of the machine to store messages.
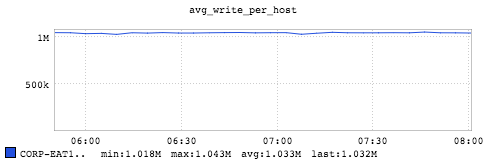
Samza also provides key-value store metrics that keep track of the number of reads to the store and number of writes to the store. The above graph is generated by aggregating all the writes to the store from each Samza container. There is a strong correlation that shows the message-processing rate per second (1.03 million) of the machine depends on how fast we write to the store (1.03 million).
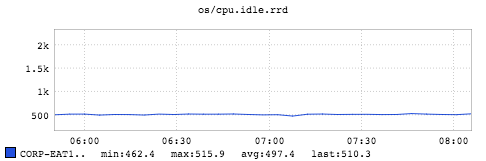
The above figure is captured through sar (a tool to report system overall activity information) to show CPU time spent in idle phase during the timespan when the test was running. Thus, the overall CPU utilization during that timespan is (100 - 497/24) = 80%. Here we almost saturate the overall CPU resources. Serialization and deserialization are the hotspots that consume CPU resources the most. There are two serialization/deserialization routines involved here. First, the messages from Kafka or upcoming stream are sent through the wire in byte array format. Once the Samza job picks up the messages, it deserializes them according to the deserializer format user specified. After the job processes the messages, the job serializes the results into the byte array again and inserts them into the in-memory store.
Although the Samza container is single-threaded, the JVM of the container is multi-threaded and contains compiler threads, garbage collection threads, and so on. All of these threads consume CPU resources in addition to the Samza container thread which is why, with 15 containers, we can saturate more than 80% of all the CPU resources (24 cores).
Key Counting with RocksDB State Store Throughput
This test is similar to the second test except we store the key in the Samza RocksDB store and we don’t do periodic clean up. The Samza RocksDB store is recommended for those Samza jobs whose buffered state is much larger than the available memory. To use the RocksDB store, we simply change “stores.store-name.factory” in Samza configuration from “org.apache.samza.storage.kv.inmemory.InMemoryKeyValueStorageEngineFactory" to “org.apache.samza.storage.kv.RocksDbKeyValueStorageEngineFactory". And, for better performance, we specify the RocksDB location in the SSD by overriding the “user.dir” system property.
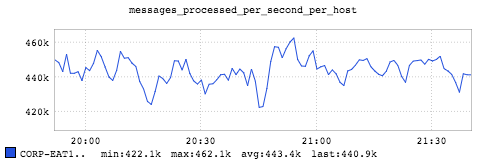
This graph shows approximately 443k messages per second when we use RocksDB as store for state. Although the total messages per second is smaller compared to using in-memory store, using RocksDB allows applications to have much larger state than what fits in memory.
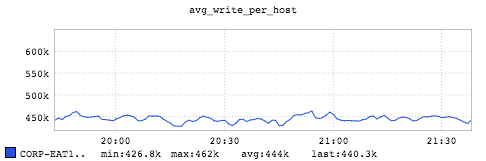
The graph shows that the Samza job issues about 444k write operation to the RocksDB store.
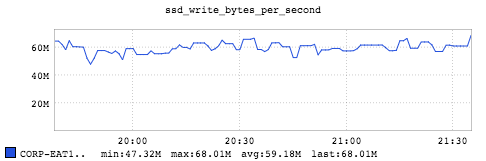
The above graph shows that the SSD is doing around 59MB/s, which is far from the SSD limitation. While this is far from ideal, the performance has proven good enough for use in production. We are in the process of investigating where the bottleneck is.
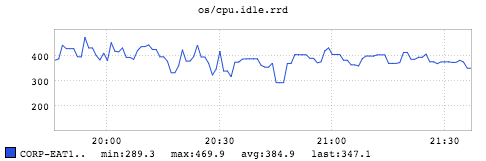
The overall CPU utilization during that timespan is (100 - 385/24) = 84%. Here we saturate the overall CPU resources which is the main bottleneck to limit single host throughput for the job.
Key Counting with RocksDB State Store and Persistent Changelog Throughput
This test is similar to the third test except we enable a Kafka based changelog. Changelog is like the redo log in RDBMS, that provides additional durability for the Samza job. All the writes to the store are periodically replicated to a Kafka topic hosted. The Kafka broker for the Changelog topic is on a separate Kafka cluster (not on the same machine). When the host machine running the Samza job fails, the Samza job gets restarted on another machine in the YARN cluster and it automatically consumes the changelog topic, reconstructs the state store where it left off, and continues running. To enable changelog, we specify stores.store-name.changelog to a Kafka topic. To improve performance, we specify linger.ms, a Kafka producer tunable, to 1ms. This tunable adds a small delay to Kafka producer, so that it waits for the delay. This allows other records to be sent during the delay so that the sends can be batched together.
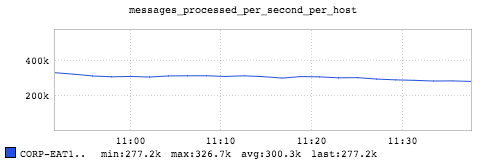
This graph shows the aggregation throughput is about 300k messages per second.
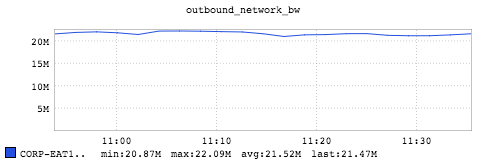
This graph shows the output network bandwidth is about 21.5 megabytes per second (172 megabits per second) which the output NIC is far from getting saturated.
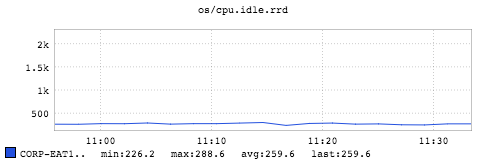
The overall CPU utilization during that timespan is (100 - 260/24) = 89%. Here we saturate overall CPU resources which is the main bottleneck to limit single host throughput for the job. The reason we have a higher CPU utilization compared third case is because by enabling changelog, a sender thread created by Kafka producer of each container also occupies a fair amount of CPU resources to send back changelog event.
Summary and conclusion
| Message Passing | 1.2 million |
| Key counting with in-memory store | 1 million |
| Key counting with RocksDB store | 443k |
| Key counting with RocksDB store and persistent changelog | 300k |
- We performed 1.2 million messages per second for a simple Samza job per single host, which is pretty cool.
- As you would expect, key counting with in-memory store gives larger message processed per second per host than the case with RocksDB store due to much faster latencies in accessing in memory state.
- RocksDB store with persistent change log provides additional durability guarantees to ensure that the state is not lost even if there is a machine failure. As a result key counting with RocksDB store and persistent changelog gives smaller message processed per second per host than the case only with RocksDB store. It is because enabling changelog introduces additional cpu overhead.
- If you have a small state that fits in memory, we suggest you use the Samza in-memory store. If you have a much larger state than your node’s memory capacity, we suggest you use Samza RocksDB store.
- We suggest enabling changelog for Samza if it needs durability.
Future Work
We will perform additional analysis to profile the overall Samza system on resource usage, latency, and CPU cost with different profiling techniques. For the RocksDB scenario, we have used the default RocksDB settings. We need to further explore these settings to see if tuning them will yield better performance.
Acknowledgements
Many thanks to LinkedIn's Performance and Samza teams for various help on this project. Special thanks to Yi Pan and Kartik Paramasivam for the continuous guidance throughout this project. Also thanks to Badri Sridharan, Haricharan Ramachandra, Cuong Tran, John Nicol, Richard Hsu, Shadi Abdollahian Noghabi, and Ed Yakabosky for their invaluable feedback and suggestions on this article.