Intra-cluster Replication in Apache Kafka
February 3, 2013
Kafka is a distributed publish-subscribe messaging system. It was originally developed at LinkedIn and became an Apache project in July, 2011. Today, Kafka is used by LinkedIn, Twitter, and Square for applications including log aggregation, queuing, and real time monitoring and event processing.
In the upcoming version 0.8 release, Kafka will support intra-cluster replication, which increases both the availability and the durability of the system. In the following post, I will give an overview of Kafka's replication design.
Kafka Introduction
Kafka provides a publish-subscribe solution that can handle all activity stream data and processing on a consumer-scale web site. This kind of activity (page views, searches, and other user actions) are a key ingredient in many of the social feature on the modern web. Kafka differs from traditional messaging systems in that:
- It's designed as a distributed system that's easy to scale out.
- It persists messages on disk and thus can be used for batched consumption such as ETL, in addition to real time applications.
- It offers high throughput for both publishing and subscribing.
- It supports multi-subscribers and automatically balances the consumers during failure.
Check out the Kafka Design Wiki for more details.
Replication
With replication, Kafka clients will get the following benefits:
- A producer can continue to publish messages during failure and it can choose between latency and durability, depending on the application.
- A consumer continues to receive the correct messages in real time, even when there is failure.
All distributed systems must make trade-offs between guaranteeing consistency, availability, and partition tolerance (CAP Theorem). Our goal was to support replication in a Kafka cluster within a single datacenter, where network partitioning is rare, so our design focuses on maintaining highly available and strongly consistent replicas. Strong consistency means that all replicas are byte-to-byte identical, which simplifies the job of an application developer.
Strongly consistent replicas
In the literature, there are two typical approaches of maintaining strongly consistent replicas. Both require one of the replicas to be designated as the leader, to which all writes are issued. The leader is responsible for ordering all incoming writes, and for propagating those writes to other replicas (followers), in the same order.
The first approach is quorum-based. The leader waits until a majority of replicas have received the data before it is considered safe (i.e., committed). On leader failure, a new leader is elected through the coordination of a majority of the followers. This approach is used in Apache Zookeeper and Google's Spanner.
The second approach is for the leader to wait for "all" (to be clarified later) replicas to receive the data. When the leader fails, any other replica can then take over as the new leader.
We selected the second approach for Kafka replication for two primary reasons:
- The second approach can tolerate more failures with the same number of replicas. That is, it can tolerate f failures with f+1 replicas, while the first approach often only tolerates f failures with 2f +1 replicas. For example, if there are only 2 replicas, the first approach can't tolerate any failures.
- While the first approach generally has better latency, as it hides the delay from a slow replica, our replication is designed for a cluster within the same datacenter, so variance due to network delay is small.
Terminology
To understand how replication is implemented in Kafka, we need to first introduce some basic concepts. In Kafka, a message stream is defined by a topic, divided into one or more partitions. Replication happens at the partition level and each partition has one or more replicas.
The replicas are assigned evenly to different servers (called brokers) in a Kafka cluster. Each replica maintains a log on disk. Published messages are appended sequentially in the log and each message is identified by a monotonically increasing offset within the log.
The offset is logical concept within a partition. Given an offset, the same message can be identified in each replica of the partition. When a consumer subscribes to a topic, it keeps track of an offset in each partition for consumption and uses it to issue fetch requests to the broker.
Implementation
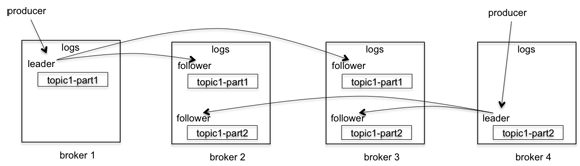
Figure 1. A Kafka cluster with 4 brokers, 1 topic and 2 partitions, each with 3 replicas
When a producer publishes a message to a partition in a topic, the message is first forwarded to the leader replica of the partition and is appended to its log. The follower replicas keep pulling new messages from the leader. Once enough replicas have received the message, the leader commits it.
One subtle issue is how the leader decides what's enough. The leader can't always wait for writes to complete on all replicas. This is because any follower replica can fail and the leader can't wait indefinitely.
To address this problem, for each partition of a topic, we maintain an in-sync replica set (ISR). This is the set of replicas that are alive and have fully caught up with the leader (note that the leader is always in ISR). When a partition is created initially, every replica is in the ISR. When a new message is published, the leader waits until it reaches all replicas in the ISR before committing the message. If a follower replica fails, it will be dropped out of the ISR and the leader then continues to commit new messages with fewer replicas in the ISR. Notice that now, the system is running in an under replicated mode.
The leader also maintains a high watermark (HW), which is the offset of the last committed message in a partition. The HW is continuously propagated to the followers and is checkpointed to disk in each broker periodically for recovery.
When a failed replica is restarted, it first recovers the latest HW from disk and truncates its log to the HW. This is necessary since messages after the HW are not guaranteed to be committed and may need to be thrown away. Then, the replica becomes a follower and starts fetching messages after the HW from the leader. Once it has fully caught up, the replica is added back to the ISR and the system is back to the fully replicated mode.
Handling Failures
We rely on Zookeeper for detecting broker failures. Similar to Helix, we use a controller (embedded in one of the brokers) to receive all Zookeeper notifications about the failure and to elect new leaders. If a leader fails, the controller selects one of the replicas in the ISR as the new leader and informs the followers about the new leader.
By design, committed messages are always preserved during leadership change whereas some uncommitted data could be lost. The leader and the ISR for each partition are also stored in Zookeeper and are used during the failover of the controller. Both the leader and the ISR are expected to change infrequently since failures are rare.
For clients, a broker only exposes committed messages to the consumers. Since committed data is always preserved during broker failures, a consumer can automatically fetch messages from another replica, using the same offset.
A producer can choose when to receive the acknowledgement from the broker after publishing a message. For example, it can wait until the message is committed by the leader (i.e, it's received by all replicas in the ISR). Alternatively, it may choose to receive an acknowledgement as soon as the message is appended to the log in the leader replica, but may not be committed yet. In the former case, the producer has to wait a bit longer, but all acknowledged messages are guaranteed to be kept by the brokers. In the latter case, the producer has lower latency, but a smaller number of acknowledged messages could be lost when a broker fails.
More info
For more details of the design and the implementation, check out the Kafka Replication Wiki and drop by my Kafka Replication Talk at ApacheCon 2013 in late February.