User Engagement Powered By Apache Pig and Hadoop
November 2, 2011
Co-authored by Nicholas Swartzendruber
This blog post tells the story of how you can use Apache Pig and Hadoop to turn terabytes of data into user engagement. It starts with a question: who viewed my profile? The answer, as It turns out, can drive a lot of users to the site.
Engaging emails
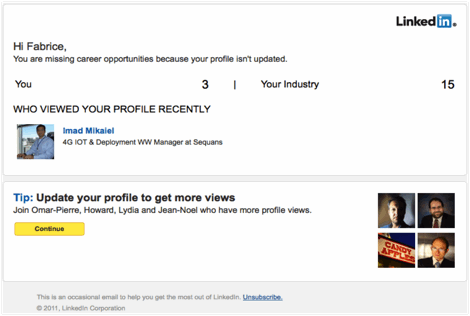
LinkedIn members love knowing that someone is paying attention to their profile; the only thing they love more is knowing that their profile is getting more attention than that of their peers. To leverage this, we decided to send some of our members a data rich email that showed how many profile views they were getting and how that compared to their industry and their connections. To build these emails, we'd have to comb through terabytes of data on our Hadoop File System (HDFS), including:
- Member information
- Member connections
- Search appearances
- Profile view statistics
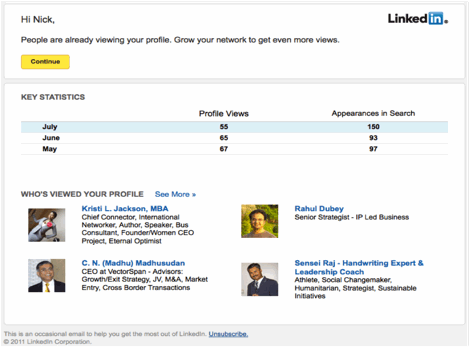
The deliverable for the project was several flavors of email, including the one above, for members with very few profile views, and the one below, for members with many profile views.
When Pigs Fly
The standard approach for bulk data processing is to write custom MapReduce programs to run on a Hadoop cluster. Unfortunately, writing MapReduce jobs in standard programming languages, such as Java, can be tedious and verbose. Therefore, to make writing MapReduce jobs easier, we used Apache Pig. Pig consists of two main components: a high-level data flow language, Pig Latin, and the infrastructure to evaluate Pig Latin programs and execute them as MapReduce jobs.
You can think of Pig Latin as a SQL-like query language for HDFS. It makes ad hoc queries possible and saves a lot of time when writing MapReduce jobs. The language is easy to learn, consisting of a couple dozen high level operators, such as group and filter, and a flexible data model that supports primitive and nested data. The majority of the operators are designed to transform the data one step at a time. The typical data transformation steps include projection, filtering, and joining two or more data sets. A typical Pig Latin script has three parts: data loading, data transformation, and storing or dumping the result to HDFS or a console, respectively. Here's an example Pig snippet that comes from "Building High-Level Dataflow System on top of Map-Reduce: The Pig Experience":
Of course, two dozen operators are not enough to handle all possible data transformations, so Pig Latin was designed for extensibility through user-defined functions (UDF). A UDF lets you switch back to using Java or other JVM-based languages for complicated tasks.
Pig's data model
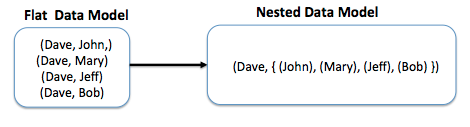
There are a few simple principles we can follow when developing Pig scripts to significantly improve performance and reduce development time. One of these is to take advantage of Pig's simple but flexible data model. This is one place where Pig differs from SQL: in addition to primitive data types, it has nested structures, including tuples (ordered set of fields), bags (collection of tuples), and maps (key, value pairs). Having the ability to logically group records with various structures keeps the flow clean and simple and can significantly reduce data size.
For example, imagine a case where we'd need to record all the connections of a user. If we used a flat data structure, we'd have one record for each (user, connection) pair. However, if we use a bag, we can use one to record to store all of the connections:
Modularity
Another key concept is modularity. Resist the urge to do all of your processing in a single Pig script. If you're using HDFS, you're probably dealing with huge data sets, which means even a simple Pig script can easily take hours to execute. Iterating is inherently slow, so you want your code to be broken into small, modular units that are (relatively) fast to run independently, easier to maintain, and make it easier to isolate bugs.
We split the work for our project into several Pig scripts, each responsible for a discrete set of transformations, with some of the scripts producing intermediate output to be consumed by the other scripts:
Redundancy
An important consideration when writing our scripts was to limit the amount of redundant work. For example, we frequently needed to know the number of profile views for each user. Each profile view is an entry on HDFS and we can calculate the total profile view count by grouping these entries together on the user's member id. If we did this "on demand" within each script that needed profile view data, we'd be repeating the same calculation - over billions of rows of data - over and over again. Instead, we use a single dedicated script that calculates the views and stores the results where other scripts can access them.
Azkaban
So now that you have a bunch of Pig scripts with lots of dependencies on each other, how do you control the order of execution? Send them to Azkaban! Azkaban is a project we've open sourced at LinkedIn that plays the role of workflow scheduler. In our project, we configured each Pig Latin script as a job and chained them together in the desired order using the job dependency mechanism.
Data processing walk-through
Now that we've laid out some basic Pig principles, let's take a step-by-step look at how we transform our raw data into the data we need to send emails.
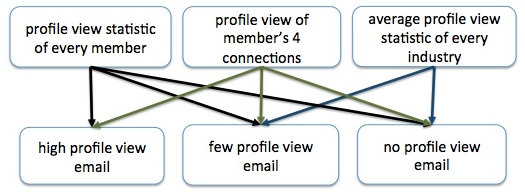
Step 1: we start with two primary data sources.
Step 2: to determine how many profile views each member has, we group the Profile_View data by viewee_member_id and then calculate the profile count for each member.
Step 3: Next, for each member, we want to find four connections that have more profile views than the member himself. To do this, we join the output data from the previous step with Member_Connections data and then just retain the member's connections that have more profile views.
Step 4: to find the average profile view statistic of each industry, we group Profile_View data by viewee_industry_id and leverage the AVG function in Pig to calculate the average.
Step 5: finally, we join all the previous outputs into a single output that contains all the data needed for the few profile view email.
Testing
As the Pig scripts execute, they produce lots of output files on HDFS. Although a manual inspection will help identify some bugs, we developed a suite of unit tests to catch bugs automatically. Since we're dealing with live data, it's hard to know exactly what output you'll get, but we knew of attributes in advance that would signal red flags.
For example, checking the data size is within some reasonable threshold is a quick sanity check. Another common check when sending out emails was to ensure that no user was in the result set multiple times. Similarly, we'd sanity check other attributes, such as checking for null values, profile views, and privacy settings.
Efficiency
With Pig, the goal of performance tuning isn't necessarily to make the scripts run faster: after all, these are offline/asynchronous jobs, so users won't notice if you save a few seconds or minutes. Instead, the focus is to make the jobs be as efficient as possible, consuming the minimum amount of resources while still completing within a reasonable SLA. This is because Pig Latin scripts are translated to MapReduce jobs that run on a Hadoop cluster shared by the whole company.
To avoid jobs that will hog the cluster for too long, we track several metrics to gauge the efficiency of a MapReduce job:
- The number of map and reduce slots a the job generates
- Execution time of each of the map or reduce tasks
- The number of HDFS files in the output
Performance tuning
At a minimum, your Pig Latin script should follow the recommended performance tips from the Apache Pig documentation: projection and filtering should be done as much as possible and as early as possible to reduce the amount of data that needs to be transfered over the network.
At LinkedIn, our Hadoop administrators additionally recommend the following rules of thumb for our cluster:
- A map or a reduce slot should take between 5 to 15 minutes to complete
- There should not be too many output files and the bigger their size the better
- When one of the input data sets is large, increase the number of mappers by lowering the value of Hadoop property mapred.min.split.size
- When an input data set contains many small files, reduce the number of mappers by increasing the value of Pig property pig.maxCombineSplitSize
- We want to increase the number of reducers for large output data sets and reduce it for small ones. Starting with Pig version 0.8, there is a safeguard for determining the number of appropriate reducers by taking MIN(max_reducers, total_input_size / bytes per reducer). The default value for max_reducers is 999, so by increasing or decreasing the bytes_per_reducer, we can control the desired number of reducers based on the size of the output data set.
Who viewed my profile?
We hope this has been a useful glimpse into how we use Apache Pig and Hadoop to build data-powered applications at LinkedIn. You can check out some of the others, such as People You May Know, Skills, LinkedIn Today and, of course, Who Viewed My Profile?