Ad-Hoc Task Management with Apache Helix
August 19, 2014
Apache Helix is a generic cluster management framework used for the automatic management of partitioned and replicated distributed systems hosted on a cluster of nodes. Helix automates reassignment of tasks in the face of node failure and recovery, cluster expansion, and reconfiguration.
Helix separates cluster management from application logic by representing an application’s lifecycle by a declarative state machine. The Apache Helix website describes in detail the architecture of the system and how it can be used to manage distributed systems. This blog post walks through Helix’s internals.
Helix was initially developed at LinkedIn and manages critical infrastructure, such as Espresso (NoSQL data store), Databus (change data capture system), a search-as-a-service system, and analytics infrastructure. Here are previous posts about Helix:
Auto-Scaling with Apache Helix and Apache YARN
Announcing Helix, an open source cluster management system
Task Paradigm: Helix's Basic Abstraction
Rather than being concerned with properties of actual running nodes, the unit of work that Helix operates on is a task (or partition), and how that task should be assigned to nodes. A grouping of these tasks is a resource. As it turns out, this abstraction is quite powerful. Helix defines a task in a broad sense, where a task is just a logical partitioning of a distributed system. Here are some examples of tasks and resources:
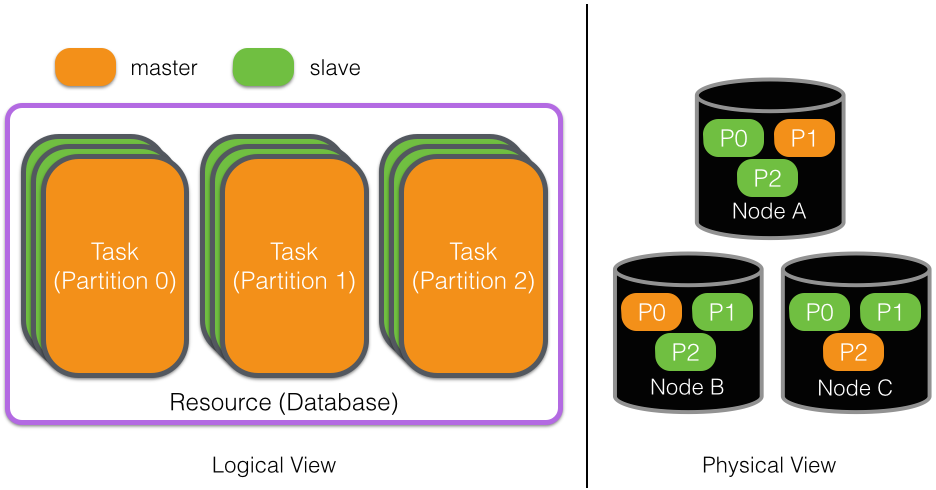
- Resource: a database; Task: a database partition
- Resource: a distributed queue to consume; Task: a single shard of that queue
- Resource: a search index; Task: a shard of that index
- Resource: a MapReduce job; Task: a mapper or a reducer
- Resource: a set of distributed locks; Task: a single distributed lock
- Resource: any logical entity that can be partitioned; Task: a single partition
With this definition of task, virtually any distributed system can be partitioned in order to map to tasks that Helix can manage. Combined with user-definable declarative state machines, Helix can send state transitions for these tasks whenever there is a need to change the placement or the state of a given task. Thus, if developers model their systems as a collection of tasks with a state machine, the only requirement to work with Helix is to plug in callbacks for each state transition.
Furthermore, by working at task granularity, tasks are not necessarily tied to any given node. If the constraints provided to Helix dictate that a task should be moved, Helix can take the task offline on the node currently serving it, and bring it online on the new node.
The figure below shows how these concepts apply to a distributed database. The logical view of a database consists of its shards, which we define as tasks, and we further assume that each task is replicated such that one replica of each is a master. These are then assigned to nodes, as shown by the physical view of the system.
What is Missing?
Traditionally, the types of tasks that Helix has managed have a well-defined target state in which they remain until reconfiguration or failure; if a database partition replica is marked as a master, it is unlikely that we will want to demote the master unless there is an explicit configuration or node state change. However, there is another class of tasks, like mappers in MapReduce, that simply are told to run, and eventually complete some time in the future. These tasks can be thought of short-lived, however they can be more precisely classified as tasks that actually define a notion of being complete.
Furthermore, these tasks may actually require some high-level strategy for placement on a cluster, much like the tasks of a distributed service. For instance, they may need to be reshuffled in response to overutilization of physical resources in a container, or they may, in the case of a database backup, need to run alongside only slave replicas of the database partitions. Because Helix specializes in solving placement problems like these, it seems like a logical progression to provide an easier-to-use API for defining these completable tasks to be managed by Helix. This is where the task framework comes in.
Some Definitions
Similar to other Helix-managed systems, the basic unit of work is still a task. Helix defines the state of something to run at task granularity, and based on the assignment policy, Helix will assign the appropriate set of tasks to each node. As before, a collection of tasks is a Helix resource, but for greater precision, we define the term job to be this special resource consisting of ad-hoc tasks. At job granularity, we can define the placement scheme of each of the tasks that compose the job. Furthermore, we can define the failure semantics of tasks in the job, and how many tasks can fail before the entire job should be canceled.
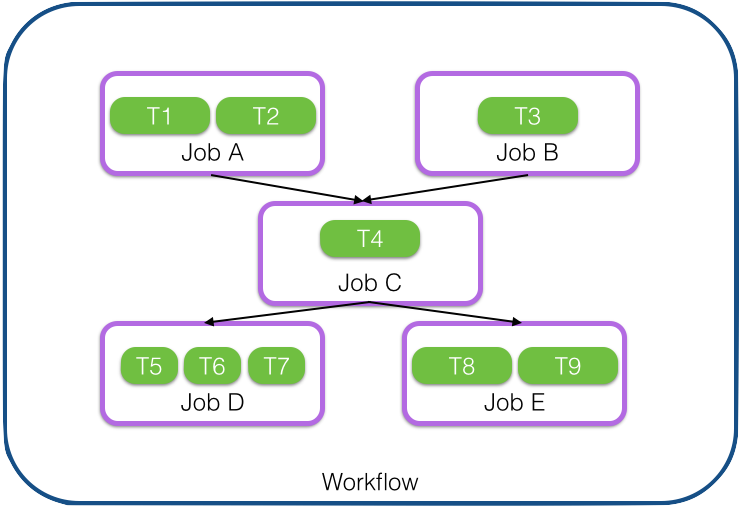
As it is a pretty common usage pattern to conditionally start jobs, we introduce the highest level abstraction, the workflow, which is essentially a DAG representation of jobs, so that we can more precisely define under which conditions a given job should start. Below is an example DAG, where job C waits for jobs A and B to complete, and jobs D and E wait for job C to complete. Notice that the tasks within the jobs are independent and varying in size and number.
Getting Started
Using the task framework requires three steps: define the callbacks containing the code that will actually run for a task, register those callbacks, and then submit the workflow.
Definition
Helix supports defining and submitting workflows in both code and a YAML configuration file. For simplicity, we will focus on a complete, annotated YAML configuration file for a single workflow. Below is a very simple example of a workflow that contains two jobs for which the second job depends on the successful completion of the first. The first job issues three tasks to data collection nodes to transform bulk load requests to a database into partition-sized chunks. Each of three tasks will operate on a third of the partitions. The second job, upon completion of the first job, will then load those chunks on a per-partition basis.
As this configuration demonstrates, tasks on Helix can be defined with as much precision as necessary. By default, DataCollectionJob’s tasks will simply be evenly assigned across all live nodes that are also assigned to the DataLoaders resource. In contrast, the placement of tasks in DataLoadJob is constrained to the extent that its tasks will only be scheduled alongside master replicas of the database MyDB, and it will not start until its parent in the DAG, DataCollectionJob, is complete. In the case of DataLoadJob and any other fully targeted job, a possible reason for making this decision is data locality; a task will be scheduled on the same instance that serves the data it needs to work with.
Recall that a Helix resource is a purely logical concept corresponding to an entity that can be partitioned; thus, defining a placement in terms of a target resource is quite powerful. For example, one may define a dummy resource with stateless partitions, and can effectively move a task by assigning the partition it targets to a different instance. Helix already has facilities to change the assignment strategy of a resource, so reassignment of tasks in a job follows naturally.
Within this configuration file, it is also possible to set a starting time and an interval of recurrence, thus Helix supports scheduling one-time and repeated workflows.
Task Callback
In order to be able to perform a task, the system developer must implement the Task interface. Here is an annotated version of this interface:
As the interface suggests, there are only two methods: run, which will return upon either completion or error, and cancel, whose implementation should force the started task to abort itself and clean up. Since Helix takes care of deciding when and whether to invoke these methods, a system developer only needs to implement the logic that should execute when they are invoked. Here is a high-level implementation of a Task that loads data (with the actual implementation of loading data left to the reader):
In this case, the constructor takes an object called a TaskCallbackContext that contains, among other fields, the full configuration of the task and job that this task is responsible for running. This need not be passed to the constructor, for example in cases where it makes sense to reuse an instance, it could instead be passed to an initialization method.
Here is a full sample implementation of the Task interface, where the task simply sleeps for an amount of time, and then returns.
Callback Registration
In order for Helix to know when to invoke the Task implementation, the task must be associated with a command. Here is an example of such a registration:
Once the task callbacks are registered, Helix will automatically invoke them when the task is assigned to the current node.
Fine-Grained Scheduling
Because Helix works at task granularity rather than node granularity, it can effectively move tasks across nodes according to any policy that may be appropriate for a system. For example, one could implement a monitoring system to track the resource utilization of tasks and move tasks to and from nodes to ensure that all running nodes have the capacity to support tasks according to any required service-level agreement (SLA). When nodes are under-utilized, it is ideal to consolidate the tasks into fewer nodes and shut down the excess ones. In contrast, if the number of nodes currently live cannot support all running tasks, more nodes can be brought up to spread out the work.
We found that this pattern of scaling up and down is generic enough that we have extended Helix to support plugging in provisioning frameworks and algorithms that can instruct those frameworks to add or remove available containers or VMs. We are building an initial implementation with YARN, and have discussed the work at ApacheCon and Hadoop Summit.
Architecture
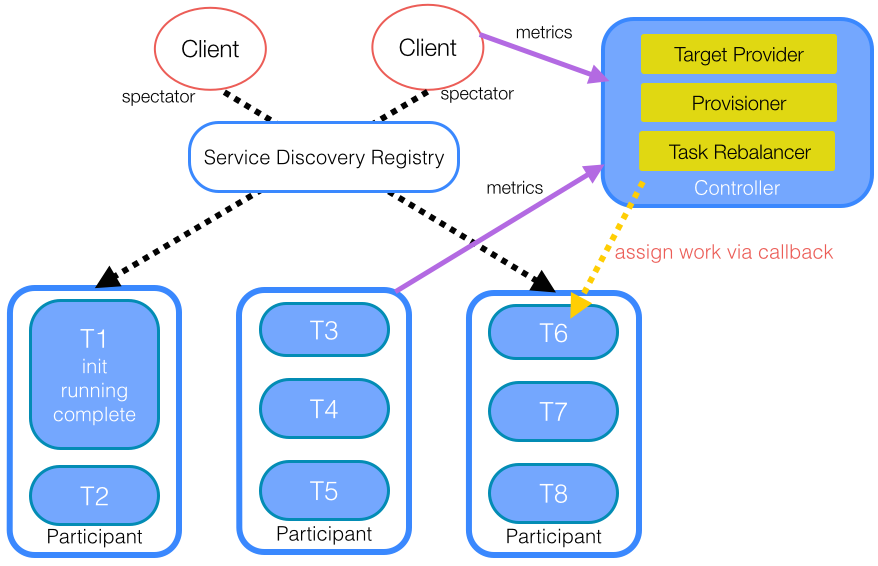
The diagram above shows the key pieces of a distributed deployment of nodes that can run tasks managed by the Helix task framework. The Helix controller is responsible for assigning tasks to nodes through the task rebalancer, which simply looks at the live nodes in the cluster, in addition to any configured constraints and perhaps even cluster metrics, and informs participants (nodes) of newly assigned or unassigned tasks.
In the case of provisioner-aware deployments, two additional components in the controller are activated. The target provider is an algorithm to decide how many containers are necessary to support the workload; this may be a fixed number, or the result of metrics that can suggest what is needed to achieve the desired SLA. Then, the provisioner is a component that calls into systems like YARN and Mesos to actually acquire or release the application’s containers.
Helix also supports simple lookups of task assignments through the configuration store backing it. Right now, Helix uses ZooKeeper as that configuration store, and abstracts ZooKeeper watches in a spectator class, so that clients can easily look up where tasks are currently assigned, without setting watches for changes or querying ZooKeeper directly. Thus, Helix essentially provides a service discovery registry for free.
Example
To demonstrate the power of this integration, we have written a recipe that demonstrates running a sample job on YARN containers with the Helix controller and task framework serving as the managers of the containers and the tasks that are assigned to them. To simplify understanding, we will show this example in the context of the DataCollectionJob from before. The general idea is that there is a job running service that is deployed on YARN, and this service includes a YARN-aware Helix controller running in the YARN application master. One can then submit jobs to this task service, and can either manually or algorithmically change containers to move the tasks around.
In order to launch the service, Helix requires a specification:
Essentially the specification needs to provide packages and pointers so that Helix can tell YARN what code to invoke to start containers running the job running service. This only needs to be specified once, and subsequently new workflows can be created and submitted to the service.
To submit the service, do the following:
After the containers come up, Helix will display information about their containers, as well as their YARN-assigned container IDs:
This tool will submit a job to the service, though it is also possible to do this through Java code or the Helix REST API:
After the workflow is submitted, Helix will take care of the assignment. Below is a snapshot of the tasks in progress given the current configuration:
Helix has by default assigned the tasks evenly such that each container is processing one of the three tasks.
Now imagine at some point the running data collection tasks are barely consuming any physical resources, or it is likely that fewer jobs will be submitted to the service in the near future. It may make sense to shut down some containers to preserve those resources. Helix allows plugging in an algorithm to do this dynamically, but it can also be done explicitly using the following tool:
Now the job runner has a pool of two containers instead of its original three. If the container that was shut down had in-progress data collection tasks running, Helix will automatically and silently reassign those tasks to one of the remaining containers. Now the snapshot will change so that the task at the container that was shut down is assigned elsewhere.
Here, Helix assigned the third task to one of the remaining containers and incremented the attempt count.
To see more of this example, please take a look at the full recipe here.
Next Play
We will soon make an official release of Helix with the task framework fully available. If you are interested in playing with it right now, check out the source code. In addition, we will continue to further couple the task framework with the YARN integration to make fine-grained scheduling easier to achieve.
We will also continue to help teams within LinkedIn leverage the task framework. Espresso, LinkedIn’s NoSQL document store, for example, will soon use the task framework to automate backups, as well as bulk loading and deleting of data. We are also exploring ways that the task framework and provisioner integration can simplify making systems at LinkedIn YARN-aware.
Interested?
Please feel free to reach out to us with any questions or comments you have. We can be reached at user@helix.apache.org, @apachehelix on Twitter, and #apachehelix on Freenode IRC.
Acknowledgements
I want to call out the other active Helix committers at LinkedIn: Zhen Zhang and Kishore Gopalakrishna, the original designers of the task framework: Abraham Sebastian and Chris Beavers, the entire Espresso team for adopting the framework and providing feedback on what to build next, and all internal and external contributors that have helped inform our design of the task framework and provisioner-awareness in Helix.