Don’t Let Linux Control Groups Run Uncontrolled
Addressing Memory-Related Performance Pitfalls of Cgroups
August 18, 2016
Coauthors: Cuong Tran and Jerry Weng
Summary
The Linux kernel feature of cgroups (Control Groups) is being increasingly adopted for running applications in multi-tenanted environments. Many projects (e.g., Docker and CoreOS) rely on cgroups to limit resources such as CPU and memory. Ensuring the high performance of the applications running in cgroups is very important for business-critical computing environments.
At LinkedIn, we have been using cgroups to build our own containerization product called LPS (LinkedIn Platform as a Service) and investigating the impact of resource-limiting policies on application performance. This post presents our findings on how memory pressure affects the performance of applications in cgroups. We have found that cgroups do not totally isolate resources, but rather limit resource usage so that applications running in memory-limited cgroups do not starve other cgroups.
When there is memory pressure in the system, various issues can significantly affect the performance of the applications running in cgroups. Specifically: (1) Memory is not reserved for cgroups (as with virtual machines); (2) Page cache used by apps is counted towards a cgroup’s memory limit (therefore anonymous memory usage can steal page cache usage for the same cgroup); and (3) The OS can steal memory (both anonymous memory and page cache) from cgroups if necessary (because the root cgroup is unbounded). In this post, we’ll also provide a set of recommendations for addressing these issues.
Introduction
Cgroups (Control Groups) provide kernel mechanisms to limit the resource usage of different applications. These resources include memory, CPU, and disk IO. Among these, memory usage is one of the most important resource types that impact application performance.
On Linux, there is a root cgroup that serves as the base of the cgroup hierarchy. Multiple non-root cgroups (i.e., regular cgroups) can be deployed, each with a fixed memory limit. A process can be explicitly assigned to regular cgroups, which are bounded by certain memory limits. Any processes (e.g., sshd) that are not assigned to regular cgroups are managed by the root cgroup.
Though cgroups do a decent job of limiting the memory usage of each regular cgroup, based on our experiences using cgroups V1 (V1 starts in Linux kernel 2.6.24, and the new version of V2 appears in Linux kernel 4.5), applications running in cgroups fail to perform well in certain memory-pressured scenarios.
We studied cgroups’ performance under various types of memory pressure and found several potential performance pitfalls. If not controlled carefully, these performance problems can significantly affect applications running in cgroups. We also propose recommendations to address these pitfalls.
Background
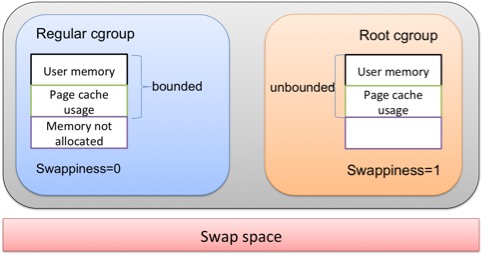
Before moving on to the performance issues, we’ll use the following diagram to present some background information. A regular cgroup’s memory usage includes anonymous (i.e., user space) memory (such as malloc() requested) and page cache. A cgroup’s total memory usage is capped by the memory limit configured for it. The root cgroup’s memory, however, is unbounded with no limit.
Each cgroup can have its own swappiness (value of 0 disables swapping, while 1 enables) setting, but all cgroups use the same swap space configured by OS. Similarly, though each cgroup can use page cache, all page caches belong to a single kernel space and are maintained by OS.
Performance pitfalls
Memory pressure in either the root cgroup or the regular cgroups may affect the performance of other cgroups. One of the impacts of these issues is degraded application performance. For instance, application startup can be much slower if the OS has to free up memory in order to satisfy an application memory request.
Experiment setup
For each of the pitfalls listed below, we conducted experiments to determine the size of the performance impact. The experiment setup is as follows. The machine runs RHEL 7 with a Linux kernel of 3.10.0-327.10.1.el7.x86_64 and 64GB of physical RAM. The hardware is dual-socket with a total of 24 virtual cores (hyper-threading enabled). OS-level swapping is enabled (swappiness=1) and there are 16GB of total swap space. Swapping in all cgroups is disabled by setting swappiness=0.
The workload used to request anonymous memory is a JVM application, which keeps allocating and deallocating objects. Other performance metrics we consider include: the cgroup’s statistics (such as page cache, swap, and RSS size), and OS “free”-utility reported statistics (such as swap and page cache size).
1. Memory is not reserved for cgroups (as with virtual machines)
A cgroup only imposes an upper limit on memory usage by applications in the cgroup. It does not reserve memory for these applications and as such, memory is allocated on demand, and applications deployed in cgroups still compete for free memory from the OS.
One implication of this feature is that, when the cgroup later requests more memory (still within its memory limit), the requested memory needs to be allocated by OS at that time. If the OS does not have enough free memory, it has to reclaim memory from the page cache or anonymous memory, depending on the swapping setup on the OS (i.e., swappiness value and swap space).
Because of this, memory reclamation by the OS could be a performance killer, affecting the performance of other cgroups.
Experiments
We started by ensuring that a regular cgroup’s memory usage had not reached its limit, and that the process running in the cgroups is requesting more memory. If the OS does not have enough free memory, it must reclaim page cache to satisfy the cgroup’s request. If the reclaimed page cache is dirty, then the OS needs to write back the dirty page cache to disk before providing the memory to the cgroup, which is a slow process when the swap files are on HDD. The cgroup process requesting memory therefore needs to wait for the memory request, and so experiences degraded performance.
Under these conditions, the application requesting 16GB anonymous memory takes about 20 seconds to obtain its anonymous memory. During this startup period, the application performance is close to zero. For normal running time, the amount of performance degradation varies based on the writeback amount of the dirty page cache and the requested memory amount.
2. Page cache usage by apps is counted towards a cgroup’s memory limit, and anonymous memory usage can steal page cache for the same cgroup
A cgroup’s memory limit (e.g., 10GB) includes all memory usage of the processes running in it—both the anonymous memory and page cache of the cgroup are counted towards the memory limit. In particular, when the application running in a cgroup reads or writes files, the corresponding page cache allocated by OS is counted as part of the cgroup’s memory limit.
For some applications, the starvation of page cache (and corresponding low page cache hit rate) has two effects: it degrades the performance of the application and increases workload on the root disk drive, and it could also severely degrade the performance of all applications on the machine that perform disk IO.
Experiments
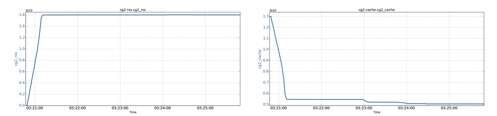
A cgroup has a set 21GB memory limit. The process inside the cgroup has already used some of the memory quota with its page cache, and then the process starts requesting anonymous memory.
The cgroup’s RSS (Resident Set Size, as reported by the cgroup’s memory.stat file) slowly increases to 16GB due to its anonymous memory requests. The cgroup’s page cache size drops by 8GB (from 13GB to 5GB). The reason for the drop is the anonymous memory request. Since the memory limit (both anonymous memory and page cache) is capped at 21GB, some page cache has to be evicted to make room for the anonymous memory. Insufficient page cache can result in lowered application performance, as more disk IO is expected.
3. OS can steal page cache from cgroups if necessary
Though page cache is part of a cgroup’s memory limit, the OS manages the the entire page cache space and does not respect ownership when page cache must be reclaimed. During this process, pages from all cgroups may be reclaimed, regardless of the ownership of the cgroup’s memory limit and memory usage.
Experiments
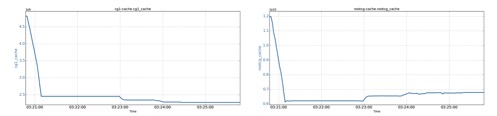
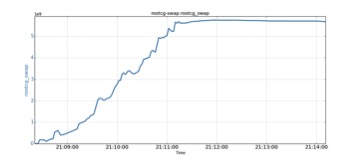
A cgroup (i.e., cg1) has used 4.8GB of page cache size. Then another regular cgroup runs a process requesting more page cache than the OS’s free memory can supply.
cg1’s allocated page cache drops by 2.6GB (from 4.8G to 2.2G), and at the same time, the root cgroup’s (rootcg in the figure) allocated page cache drops by 5.5GB (from 12GB to 6.5GB).
Since any cgroup’s page cache can be dropped, the applications running cgroups with dropped page cache can experience degraded performance due to insufficient page cache. Moreover, since there is no control over which cgroup’s page cache can be dropped, it is very difficult for applications to deliver consistent performance.
4. The OS can swap anonymous memory from cgroups if necessary
Like page cache, anonymous memory is similarly controlled by the OS. The swapping control policy (swappiness) of system (i.e., root cgroup) takes precedence over any policy set in a user cgroup. When there is no memory pressure outside a regular cgroup, setting a cgroup’s swappiness to zero prevents swapping of processes inside the cgroup. However, if the root cgroup allows swapping, the OS can swap out processes in user cgroups when under memory pressure, even if the victim cgroup’s swappiness is set to zero and its memory limit has not yet been reached.
Experiments
Two cgroups (cg1 and cg2, each has 30GB memory limit) are created. The root cgroup has used 10GB of anonymous memory, and cg1 has used 28GB of anonymous memory. Now cg2 requests an additional anonymous memory.
cg1’s swap size increases by 3.8GB (from 0GB to 3.8GB), due to the anonymous memory request from cg2. cg1’s RSS drops by 3.8GB (from 29.3GB to 25.5GB) due to its memory being swapped out.
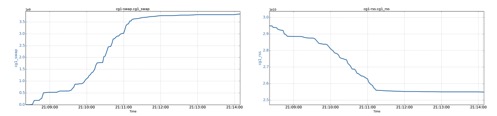
Interestingly, cg2 also experiences swapping of 1.2GB (from 0GB to 1.2GB) caused by its own anonymous memory request. Despite the swapping, cg2’s memory request is fulfilled, and it gains 15GB more RSS.
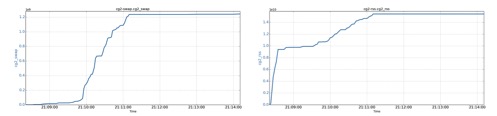
The OS swap size is reported by Linux’s “free” utility, and we found the root cgroup’s swap size increased by 5.8GB (from 0GB to 5.8GB). Note that the reported raw swap value needs to subtract cg1 and cg2’s swap values. The swap size increase is caused by cg2’s memory request.
Summary of issues
We have seen that there can be severe performance issues if there is memory pressure on the system. First, the memory limit set for each cgroup is not reserved. If memory requested by applications running in cgroups is not readily available, application performance can be impacted.
Second, since page cache used by an application is part of the cgroups’ memory limit, when sizing the memory of the hosting cgroup, the application’s page cache footprint needs to be appropriately estimated.
Third, the memory reclamation (i.e., page cache and swapping) process is completely controlled by the OS. If memory needs to be reclaimed, the OS can steal page cache or swap out pages associated with any cgroups, even if settings in the cgroup suggest this should not be possible.
Strategies to avoid the pitfalls
Overview
For all the memory-related issues we demonstrated, the key to solving the problems is to ensure that the memory usage of all cgroups (both the root cgroup and regular cgroups) is tightly controlled. Since the cgroups feature does a decent a job of limiting the memory usage of each regular cgroup, the ultimate solution is to also tightly control the memory usage of the root cgroup. By default, the root cgroup’s memory usage is not bounded, so unless all processes in the root cgroup are tightly memory-controlled, the root cgroup may use too much memory and starve regular cgroups.
However, tightly controlling each root cgroup process for now with cgroups V1 is a tough task, if not impossible. Considering this difficulty, we recommend the following approaches to mitigate performance issues. Each of these approaches targets a particular issue and belongs to a particular category, but they work in tandem to ensure the applications deployed in cgroups run with expected performance.
Strategies
1. Pre-touching the needed memory in regular cgroups
Since the memory limit of cgroups is not allocated beforehand, it helps to “pre-touch” the needed anonymous memory and avoid use-as-you-go requests.
The exact methods of pre-touching memory vary across languages. For a Java application that uses heap, we can use the “-XX:+AlwaysPreTouch” flag and set identical values of “Xms/Xmx” flags to pre-touch the heap memory. For off-heap memory, it also helps to ask the application to pre-allocate needed memory when possible.
2. Properly sizing the memory footprint of an application
When onboarding an application to cgroups, the memory footprint of the application needs to be sized. Since a cgroup’s memory limit counts both anonymous memory and page cache used by the cgroup, sizing memory footprint should consider both memory types.
Estimating the anonymous memory footprint needed is relatively easy, but the page cache footprint estimation in a non-cgroup environment is very difficult. First of all, there is no direct Linux metric on page cache usage by processes. Other factors contributing to the difficulty include: different use characteristics during application startup (i.e., some applications read files once then discard the cache pages), file system prefetching, and application logging (logs may only be written once, then many pages are discarded).
Fortunately, there are performance metrics available from the cgroup subsystem (i.e., the memory.stat file in cgroups). The metrics show the current usage of all memory resources by the cgroup (adding RSS and active_file). Based on these metrics, we can apply heuristics to assess the memory needed (both anonymous memory and page cache).
Specifically, a cgroup’s memory footprint consists of two parts: an anonymous memory footprint and a page cache footprint. The anonymous memory footprint can come from RSS metric reported, which is quite accurate. The page cache footprint comes from the active_file metric reported, but this is only an approximate value, as the application may need more page cache than the active_file value as it does IO. Because of this, we add a headroom value of 1GB at LinkedIn to account for the extra that may be required.
When determining memory footprint, we also need to deal with a few corner cases. First, we avoid taking measurements during the application’s startup state. The RSS and active_file values should be obtained during application’s stable running time. In particular, when the application starts, it may temporarily need more than the normal page cache size (e.g., read-once files). The stable running time should be long enough (at least 1 week) to include busy business hours.
Second, we discard anomalous data. As an application may temporarily use more files, hence creating anomaly in the reported active_file metric, we should discard the anomalous data by considering only values that last for a sufficiently long time (e.g., 10 minutes).
In addition, it is also necessary to evaluate and dynamically resize a cgroup’s memory limit regularly, since the memory footprint of an application might change over time (e.g., as the user base grows or features are added).
3. Limiting memory usage of system utilities and housekeeping processes
If processes in the root cgroup occupy too much anonymous memory and/or produce too much dirty page cache, they may cause performance problems in user cgroups, as the root cgroup may steal system-wide page caches and cause swapping in other cgroups. To mitigate this, you should keep minimal housekeeping processes (e.g., sshd) in the root cgroup, and move as many processes as possible to properly-sized user cgroups., since user cgroups respect memory restriction policies (unlike the root cgroup). Note that some Linux vendors create special cgroups to limit the resource usages of system processes. For example, RHEL 7 has system slice, which can be separately memory limited.
In particular, cron can run both OS utilities as well as application jobs. To avoid the pitfalls of cron jobs using too much anonymous memory and page cache, you can put cron in a tightly-controlled user cgroup.
Conclusion
While cgroups provide a decent mechanism to limit the memory usage of applications, they can cause application performance degradation during memory pressure scenarios. This post discusses several of these scenarios and presents solutions to address the problems.
Cgroups V2 (just released a few months ago, in March 2016, and which we have not yet tested) has some new features and performance improvements compared with V1. We will test it as part of future work.
The authors will give a technical talk regarding this topic at APMCon 2016.