Auto-Scaling with Apache Helix and Apache YARN
September 24, 2013
At LinkedIn, many individual services integrate together to deliver a reliable and consistent end-user experience. Although each service handles a specialized set of responsibilities, they all share a common set of required features such as load-balancing, dynamic reconfiguration, health monitoring, and fault-detection. Last year we introduced Apache Helix, an open-source generic cluster management framework to address these challenges. Today, Helix controls critical LinkedIn infrastructure, including Espresso, Databus, Search-as-a-Service, and others.
 Check out Apache Helix code now!
Check out Apache Helix code now!
During this time, another high-profile project has been maturing in the space of distributed systems: Apache Hadoop YARN, a generic resource manager and controller for large-scale distributed applications. Arriving from MapReduce, YARN leverages HDFS and introduces container-based resource allocation to achieve scalable application deployment, management, and monitoring. Today, there is a very active community applying the framework to big-data challenges and large-scale service deployments.
 Figure 1: Auto-Scaling process with Apache YARN and Apache Helix
Figure 1: Auto-Scaling process with Apache YARN and Apache Helix
Each framework addresses complementary aspects of the life-cycle of distributed systems:
- YARN automates service deployment, resource allocation, and code distribution. However, it leaves state management and fault-handling mostly to the application developer.
- Helix focuses on service operation, state management, reconfiguration and fault-handling. However, it relies on manual hardware provisioning and service deployment.
Integrating the abilities of Helix and YARN has great potential: we could support the whole life-cycle of a distributed application, from bootstrapping, fault-recovery, and evolution until the very final de-provisioning. As an intern on LinkedIn's Data Infrastructure Team this summer, I got the chance to develop a proof-of-concept prototype of such a system, which I will describe in this post.
Introducing Auto-Scaling with Helix and YARN
Our system automates the life-cycle of a distributed system and adds automated Service-Level-Objective-based (SLO-based) capacity planning on top. Similar to Amazon Auto Scaling, the size of a cluster will be adjusted up and down automatically based on objectives defined by the operator without violating constraints. In addition to saving cost and scaling rapidly when demand increases, the system automatically recovers from partial failures by replacing failed instances. These auto-scaling capabilities are independent from a specific cloud service provider, so you can deploy them on-site or use them in private and hybrid enterprise clouds.
The solution relies on the tested and unmodified distributions of Helix and YARN, combined using a layered architecture. There are two types of clusters present in a deployment:
- Managed cluster: this resembles the usual deployment of Helix with any number of controller and participant nodes.
- Meta cluster: collects health metrics, performs capacity planning, and injects application containers (participants) into the managed cluster on-demand.
An example: an auto-scaling redis cluster
As a demonstration, we will show how to implement an auto-scaling distributed in-memory cache using our solution and the Redis key-value store:
- We use a YARN cluster deployed on several physical nodes to spawn Helix participants
- The Helix participants, in turn, launch and control a local redis-server instance.
- To simulate traffic towards our cache, we continuously run instances of redis-benchmark and aggregate the throughput in transactions per second (Tps), just as if the distributed cache was accessed from various frontend servers.
- We feed the throughput measurements to our system, which then decides to scale up or down based on a Tps target and takes care of process failures.
Note that we use this simple Tps-based model for demonstration purposes; other metrics, such as request latency or the number of cache misses, could be utilized to build a more sophisticated model.
The whole application can be bootstrapped using tools provided by our Helix extension. However, before we are able to do so, two components need to be created:
- A Helix participant for redis-server. We created one that implements the simple Online-Offline state machine.
- A model that relies on redis-benchmark results to dynamically compute number of containers required. We created a model that uses linear interpolation based on a moving average of the aggregated Tps.
Both components can easily be implemented in under 100 lines of Java code, or less using existing templates. When both components are ready, we can bootstrap the application using a single configuration file (see Appendix).
Architecture In-Depth
The meta cluster performs three major tasks:
- Cluster monitoring and capacity planning: this is addressed by the performance target model.
- Container deployment and monitoring: participants of the managed cluster are created and destroyed by the container instance providers. The high-level status of each container is available to the meta cluster through the container status provider.
- Dynamic configuration and fault-handling: this is addressed by existing Helix functionality by implementing container instance providers as participants (of the meta cluster) themselves.
The auto-scaling deployment of an existing Helix service only requires a thin start/stop wrapper and an application-specific performance target model. Container providers are implemented to automatically distribute the application code and monitor bootstrapping until the managed cluster takes control over the instance.
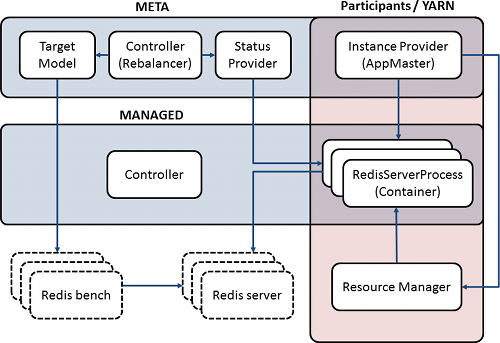 Figure 2: Architecture of the system running Redis
Figure 2: Architecture of the system running Redis
The performance target model supports a pluggable implementation. It may collect any number of utilization metrics and statistics, run a model and return the target number of containers. This target value is then combined with health data from the container status provider to obtain the number of instances to inject in the managed cluster. The actual task of container injection (or removal) is performed asynchronously by the container instance providers.
YARN comes into the picture as the implementation of the container instance provider and container status provider. Our system implements a generic YARN Application Master (AM) to perform container allocation and monitoring. Although a specific implementation exists for YARN, the container providers are pluggable. Currently, alternate implementations exist for JVM-local services and generic UNIX processes. Further integration with VM-hypervisors and cloud service providers like EC2 are being planned.
Auto-Scaling in Action
Let's test our new distributed cache. We will start with some stretching exercises, moving the target between 0 and 1,000,000 Tps. The blue line describes the target, the red line the measured Tps. In yellow, you'll find the number of actual Redis instances in the cluster for a 2-hour test run.
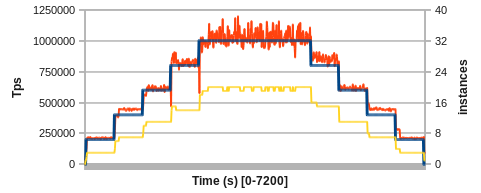 Figure 3: Non-linear scaling from 0 Tps to 1M Tps and back
Figure 3: Non-linear scaling from 0 Tps to 1M Tps and back
Even a simple model based on averages and linear interpolation already works well and maintains Tps close to the target. However, we can quickly identify several areas for improvement.
First, immediately after increasing the Tps target, we can observe a down spike in measured Tps. Since we're running many processes in parallel on each physical node, the activity caused by YARN spawning containers impacts the steady-state operation of existing server instances. A throttled placement of containers could alleviate this issue.
Second, after scaling up or down, there is a short period of time where the model overcompensates with the number of instances. Here, the non-linear performance scaling of co-located processes becomes visible and the averages used for prediction take some time to adapt.
Third, with the target Tps around 1M the variance of measurements goes up and creates some jitter in the number of instances. This could be addressed with a red-line / green-line approach or by assuming a less reactive distribution.
Autonomous Fault-Recovery
So far, we have been dealing with a perfect world without failures. To showcase the fault-recovery mechanism employed by the Helix extension, we provide two demonstrations. In the first demo, we inject random process failures into our testbed while running the system at a constant 1M Tps target. For a 2 hour run, we start with 5% process failures per minute, after 40 minutes move to 10% per minute, and after 80 minutes move to a substantial 20% failure rate per minute.
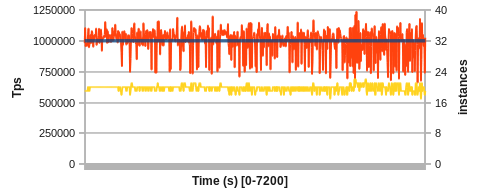 Figure 4: Recovering frequent faults at 1M Tps (5%, 10% and 20% process failures/min)
Figure 4: Recovering frequent faults at 1M Tps (5%, 10% and 20% process failures/min)
Even under the most extreme failure condition, the system is able to recover constantly and returns to the Tps target. A positive side-effect of the average-based model is the tendency to automatically compensate for the overhead caused by failing server instances and YARN starting new ones. This can be seen by the trend to go to over 22 instances total in the latter third of the experiment although in perfect isolation only 19-20 are required to achieve the target.
In the second demo, we look at increasingly larger faults and finally a catastrophic system failure. The following 2 hour run is set to a 1M Tps target again. After running in steady state for 15 minutes, we inject physical node failures, bringing down a large portion of server processes and losing substantial amounts of resources at once. The nodes are brought back online a minute later, and they are necessarily required to achieve the target tps, i.e. the cluster is over-provisioned with a 25% margin.
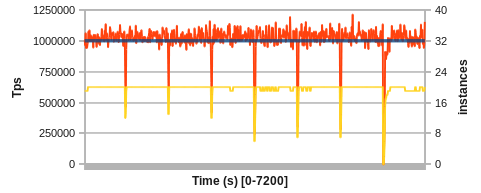 Figure 5: Fault spikes at 1M Tps (3 x 33%, 3 x 66% and 1 x 100% failure)
Figure 5: Fault spikes at 1M Tps (3 x 33%, 3 x 66% and 1 x 100% failure)
This showcases the ability of the system to dynamically let go of resources and (re-)incorporate new ones on the fly. The first three spikes crash roughly 33% of instances at once, the second three crash 66% of instances, and the last spike is a complete (100%) system failure and requires complete bootstrapping of the distributed cache.
The initial 33% failure spikes do not have a long term impact. After a minute, the system is back to almost normal operation, only adding on one or two more instances after the failed resources come back online. The 66% failures take slightly longer to recover, about 2 minutes, but still no long-term impact. However, a side-effect on the target model can be observed, taking some time to adjust to slightly different process characteristics and causing some jitter. The final complete system failure is handled on a best-effort basis. Returning to 1M Tps takes about 5 minutes: the non-availability of resources for the first minute and the bootstrapping activity caused by YARN after resources come back take its toll. Also, the target model takes some time to adjust. Nevertheless, the system is recovered fully and automatically.
Of course, auto-scaling and recovery times depend heavily on the amount of work required to bootstrap an individual process. In our case, we use Redis server and load a predefined data image, which completes within seconds. A heavyweight process such as an Espresso database instance hosting multiple partitions may have a much higher startup cost due to data migration and self-test requirements. Hence, our solution is as agile as the participants it manages.
The Future
We are currently working on the cleaning up the code base and we plan to release it to the open-source community in the near future.
Acknowledgments
Apache Helix and Apache Hadoop YARN are open-source projects and are developed by a large and active community. The Helix auto-scaling prototype was developed as an engineering intern project at LinkedIn during summer 2013 by Alexander Pucher under the supervision of Swaroop Jagadish and Kishore Gopalakrishna. Many people here at LinkedIn contributed to the successful project with their ideas and knowledge. We especially would like to thank Bob Schulman and Chris Riccomini for their help.
Appendix
Distributed Redis Cache bootstrap configuration