

Making Your Feed More Relevant – Part I

The LinkedIn feed is the sorted list of updates displayed to our members when they log in to Linkedin.com or use the mobile app. Feed relevance is the task of evaluating the appropriateness of updates to different members, and more generally, ranking the updates in a personalized feed format. The goals of the feed are to help our members stay connected to their professional world, stay informed, and establish their brands.
The task of evaluating relevance and ranking updates is similar to classic recommendation systems such as movie recommendations, with a few twists:
The LinkedIn feed has a heterogenous inventory of updates: articles shared by connected members, job recommendations, news recommendations, suggestions to connect to members (“People You May Know”), news stories mentioning companies that the member is following, etc...
Many members interact heavily with the feed, scrolling down several times. It is very important to display a feed that allows the member to have engaging interactive sessions, rather than focusing only on finding the most relevant updates and including them at the top.
The feedback that we collect is based on members’ implicit actions, rather than explicit actions, such as assigning 1-5 stars for a movie recommendation. Implicit actions that we track include clicks, likes, comments, shares, and time viewed.
LinkedIn’s social graph is an important component of the relevance modeling. Members often find updates shared (or liked, or commented on) by their connections to be more relevant than otherwise.
LinkedIn’s members have an incentive to complete their profiles on the site as it represents their professional identity. As a result, LinkedIn has access to high quality data representing members’ interests, skills, and background.
The LinkedIn feed relevance system includes multiple sources called First Pass Rankers (FPRs) that create a preliminary ranking of their inventories based on predicted relevance to the feed viewer. Examples of FPRs are job recommendations, news article recommendations, updates or shares from your connections, recommendations for new connections (PYMK), and sponsored updates (SUs). The FPRs score their respective inventory of updates with respect to the viewer, and output the top-k updates to the Second Pass Ranker (SPR) that combines the output of all FPRs and creates a single personalized ranked list. After the second pass ranking, the ranked list is passed to the re-ranker stage that modifies the output of the SPR and creates the final feed that is sent to the appropriate front-end.
The heart of the SPR is a logistic regression model that takes as input features representing the feed viewer, the update candidate, and the FPR score, and outputs a score aimed to capture the probability that the viewer will interact with the update (as measured for example by click, like, share, and comment). The SPR then ranks the updates from the different sources based on these scores and the re-ranker modifies the ranked list to ensure diversity and other properties that are important to promote an engaging feed browsing session for the member.
The figure below presents the feed architecture and is followed by three enlarged figures that focus on the FPRs (left part), the feed mixer (middle), and the front end (right).
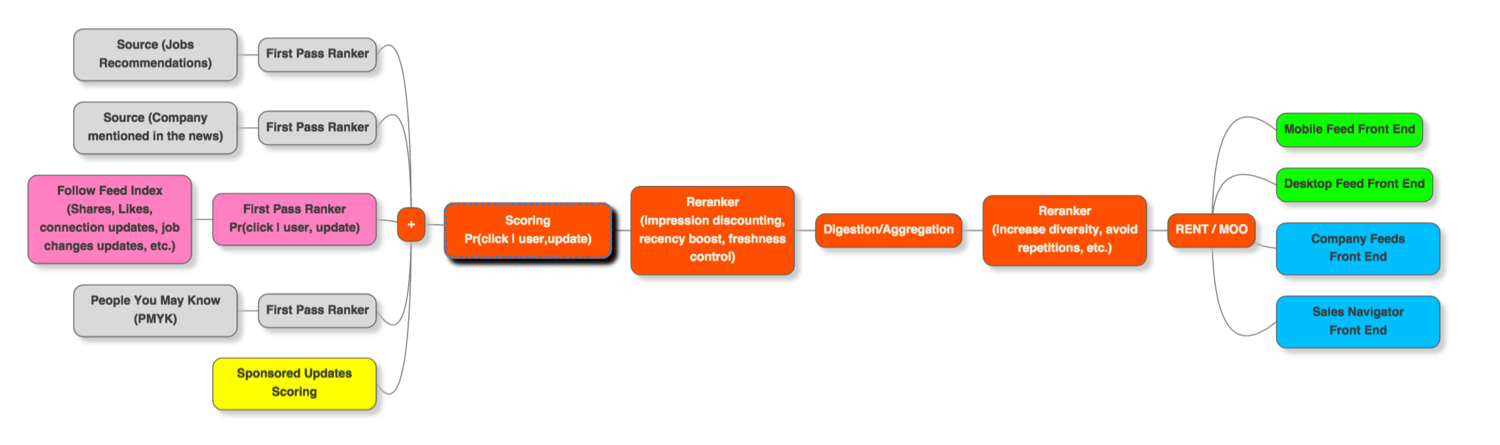
The single most important FPR is “activities from your network,” which includes shares from people or companies the viewer is connected to, and updates on profile changes. That source contains over 50% of the updates in the LinkedIn feed.
There are three motivations for having a multistage process rather than a single monolithic model. The first reason is scalability. Some of the sources have to use a sophisticated index to store a large number of updates for fast retrieval. It is important that these sources be able to retrieve the top-k updates very fast, potentially limiting their relevance capabilities. The SPR aggregator can use additional features that are costly to compute and use more complex ranking rules since it only scores a relatively small number of candidates. Since the FPRs only provide the top-k updates, their ranking model is not as crucial as the SPR model that computes the final model.
A second reason is that teams may work on different FPRs using different types of features and domain expertise. For example, predicting ad relevance is a different task from predicting job recommendations. Having different FPRs allows multiple teams to conveniently work in parallel and speed up the pace of innovation. The third motivation for having a multi-stage process is that some aspects associated with creating the final ranked list depend on the entire ranked list (that is unavailable at the time of querying the storage indices), rather than scoring each individual update in isolation. More details on this will be covered in part III of this series of posts.
In part II, we will discuss details of the SPR and the “activities from your network” FPR. Part III will cover details of the reranking stage, and Part IV will cover challenges and future directions.
References