

How SlideShare Changed Engines While Flying

Editor's note: This blog has been updated.
70 million professionals trust SlideShare to learn about any topic quickly from subject matter experts. Founded in 2006 with the goal of making knowledge sharing easy, Slideshare joined the LinkedIn family in 2012 and has since grown into a top destination for professional content. With 18+ million uploads in 40 content categories, it is today one of the top 100 most-visited websites in the world.
Getting from there to here has not been simple. After LinkedIn acquired SlideShare, we had several challenges, including the integration of the separate technology stacks. We viewed integrating these technology stacks as an ideal to strive for because it would allow us to:
Combine functionality between the two products
Leverage existing technical solutions
Lower operational costs
SlideShare was using a managed hosting provider. It had built up numerous systems for slideshows, analytics, and search. It had a world-class image platform, and a small but capable engineering team.
LinkedIn, on the other hand, had its own growing data centers. At its scale, it required its systems to work across multiple data centers. It had a much larger engineering team capable of major investments in tooling and technology. LinkedIn also had built world-class systems for search and analytics, and already had a large team of SREs and DBAs for support and maintenance.
It was clear that to sustain growth and integrate the best parts of both products, SlideShare needed to move to LinkedIn data centers.
Once the decision was made that the SlideShare technology stack needed to move, the first order of business was to come up with a plan. The assessment was based on answering the question “What SlideShare assumptions would be broken if we were to move to a LinkedIn data center?”
A small sample of the problems we identified are below:
LinkedIn has a strict policy that only hosts in the network demilitarized zone (DMZ) have limited access to the Internet, whereas the SlideShare managed hosting provider allowed every host to have outbound connectivity. The SlideShare software development cycle was heavily dependent on having Internet access from any host.
The SlideShare stack had been using floating IP addresses to make certain components such as load balancers highly available. While that approach worked with the hosting provider, it would not have worked inside LinkedIn due to differences in the respective network architectures.
Legacy puppet code at SlideShare used host naming conventions specific to the managed hosting provider to drive the logic of execution. We had to break these assumptions about host names and refactor the code.
To successfully task LinkedIn database administration group with building and supporting all our databases we had to make the changes to legacy practices of operation of the databases. That led to significantly cutting down the puppet codebase -- always a welcome change.
LinkedIn traditionally had been running on a modern Red Hat Linux distribution while SlideShare was a major revision behind. Since SlideShare is built on Ruby on Rails, multiple gems, including ones with native code extensions, had to be recertified on the new operating system.
Evidently, we had some work to do.
As a first step, we decided to rebuild our app stack entirely in the legacy data center based on the knowledge of what it would look like when we start moving things to the LinkedIn data center. The main motivation for rebuilding in the legacy data center was to have a testing ground before the final cutover.
For instance, to test the new operating system version, we would deploy new hosts on the legacy data center with the same operating system revision that LinkedIn normally used. Puppet code refactoring was done as well to eliminate the dependency on particular hostname conventions. In cases where endpoints has to be different between legacy and new data centers, we would invest in refactoring application code.
By doing those steps, we eventually ended up with refactored code and hosts that were closely matching our ultimate target: hosts in the LinkedIn data center. We also certified that switching to the new platform would not cause issues with the SlideShare application stack.
During this step, we took the initial pass at rebuilding our application stack within the LinkedIn data center. Fundamentally, there were two major pieces: a “data provider” layer and “everything else”. Examples of “data providers” are MySQL, Redis, MongoDB, HBase and the like.
For each provider, we determined whether it made sense to replicate the data continuously (where the primary data source was in the legacy data center), or make a one-time copy manually during cutover (more on that later). At this moment, the source of truth for data was still the legacy data center, and only replicas of the data resided in the LinkedIn data center.
In addition to changing our software platform, our hardware platform was changing as well to newer systems with different performance characteristics. To ensure that we wouldn't face any surprises, we used captured logs and performed synthetic load tests against the proposed software stack in the LinkedIn data center.
At this stage of the game, we had all the pieces together: application nodes, caching layers, databases of different kinds, and load balancers. By working with our Traffic team (who manages the termination of edge network traffic for the SlideShare domains), we were able to come up with an easily controllable environment, where with the flip of a software switch, we could divert traffic to the new LinkedIn operated data center.
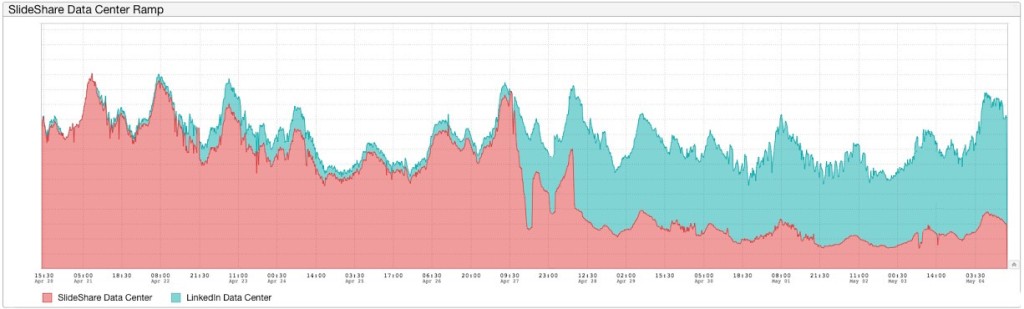
While the LinkedIn data center could handle only read requests to the site, as it turns out a significant percentage of SlideShare’s requests are for non-logged in users, and thus are read-only requests. Thus we were able to use the software control mechanism to provide a functional site to these non-logged in users. As a further precaution against misdirected writes, our database administrators put our data stores into read-only mode, which helped us to identify some edge cases of application code that still tried to perform writes for non-logged in users.
The primary constraints on our migration revolved around the application only accepting writes at a single location. To make write ramp completely uneventful is not a small feat — akin to replacing an engine of an aircraft mid-flight. In an ideal world, one wants to make such a switch completely transparent. Press a magic button: voilà! Traffic is served from a new location.
Keeping the objective “database writes should only happen in one place” in mind, we tackled the “write ramp” problem using a few techniques. For every interaction that would perform writes, we created “a feature flag” — a software switch we could easily turn on or off. We also had background jobs that wrote to databases, so we came up with a plan for how to terminate and resurrect them on demand.
To document the steps for transitioning writes to the new data center, we wrote an elaborate runbook with all of the required steps, their ownership, and duration.
We also had to decide when to perform the cutover. The ideal timing would be when SlideShare had the least usage to minimize impact on users. After considering the pros and cons, we decided to perform the cutover after peak traffic to SlideShare, but at a time when the majority of engineers would be available, so unforeseen problems could be resolved quickly. During practice runs of the cutover, we agreed on what potential problems would trigger a rollback to the prior, pre cutover state. Preparation is the key!
The day had come. Everyone in the office felt an energy in the air: “we have been working on this for more than a year and now we are doing it!” For the cutover we appointed a contact person who would always know the latest status and would orchestrate the execution of the work.
As planned, our first objective was to prepare ourselves to move “write” traffic from the legacy to the new data center. We did it by disabling product features that write to the database, then putting “read-only” rules on the legacy data center. Using the same software-based switching done during the read-only ramp, we moved write traffic from the legacy data center to the LinkedIn one. While we did route write traffic to Linkedin, we intentionally disabled any write traffic on the load balancer level below our internet edge.
Next, we ensured that we had a perfect sync of our data in the new data center, and then removed read-only status, effectively declaring the LinkedIn data center as the new source of truth.
Up to this point we had blocked external users from writing to the LinkedIn data center (by enforcing not to serve any traffic that might cause writes to DBs) and performed internal testing. Once we confirmed write-paths were functional, we re-enabled all product features. Once everything was working as expected ... celebration time! (Now the big engineering and operations team which tirelessly worked on this project for more than a year could have a break.)

A few months after the completion of the cutover, we decommissioned the infrastructure at our former managed hosting provider since there was no longer a need for it. We had already begun to leverage key LinkedIn technical assets and platforms; this was far easier because SlideShare was in a LinkedIn data center. Historically, the SlideShare application was monolithic; we are currently working to breaking it down into microservices. While doing so, certain legacy components are being retired and replaced by LinkedIn equivalents. As LinkedIn keeps investing in content creation/knowledge sharing products and services, SlideShare will continue to play an important role in fulfilling our mission of helping professionals across the world learn about any topic from subject matter experts.
This project would not have been successful without the support from an amazing team. We would like to thank our core members (Bubby Rayber, Omar Alaouf, Lionel Moore, Casey Abernathy,Toby Hsieh, Neha Jain, Hari Prasanna, Nikhil Prabhakar, Matthew Chun-Lum, Jasmeet Singh), the rest of the SlideShare team and our partners on the Linkedin production operations teams.