Real-time Analytics at Massive Scale with Pinot
September 29, 2014
Two years ago we hit a wall. The scale of LinkedIn’s data was growing beyond what we could analyze. At the same time, our members needed their analytics and insights in real-time. We needed a solid solution that would grow with LinkedIn and serve as the platform to power all of our analytics needs across the company at web-scale. In this post, we will share how and why we built a distributed real-time analytics Infrastructure for interactive analytics applications.
While generic storage systems can be used to support single point use-cases, to do this at scale demanded specialized distributed infrastructure. We looked at open source options and there was nothing out there that would work given the scale and richness of the data sets we were dealing with, so we embarked on a multi-year project, codenamed Pinot.
Pinot was born as an answer to our problems, a web-scale real-time analytics engine designed and built at LinkedIn. Pinot enables us to slice, dice and scan through massively large quantities of data in real-time across a wide variety of products.
Today, we are announcing that Pinot is now the de facto distributed real-time analytics infrastructure at LinkedIn.
Online Analytics Products
Pinot is the infrastructure that powers 18 member facing analytics products and more than 15 internal analytics products.
Who’s Viewed Your Profile‘Who’s Viewed Your Profile’ (as the name suggests) is LinkedIn’s flagship analytics product for our members. It allows members to see who has viewed their profile in real-time. In early 2014, we launched a completely redesigned version of this product to give users more power. This product needed to run complex queries on large volumes of profile view data to identify interesting insights dynamically. Pinot is the infrastructure that started powering this new redesigned product.

‘Company Follow Analytics’ is one of our premium Analytics products within Marketing Solutions. Company Pages on LinkedIn is a great way to allow members to follow relevant companies and help build their brand. The Company Page Analytics product enables company admins to understand the demographics of the people who follow their page and also helps them to understand follower trends. Pinot is the infrastructure that supports this product.
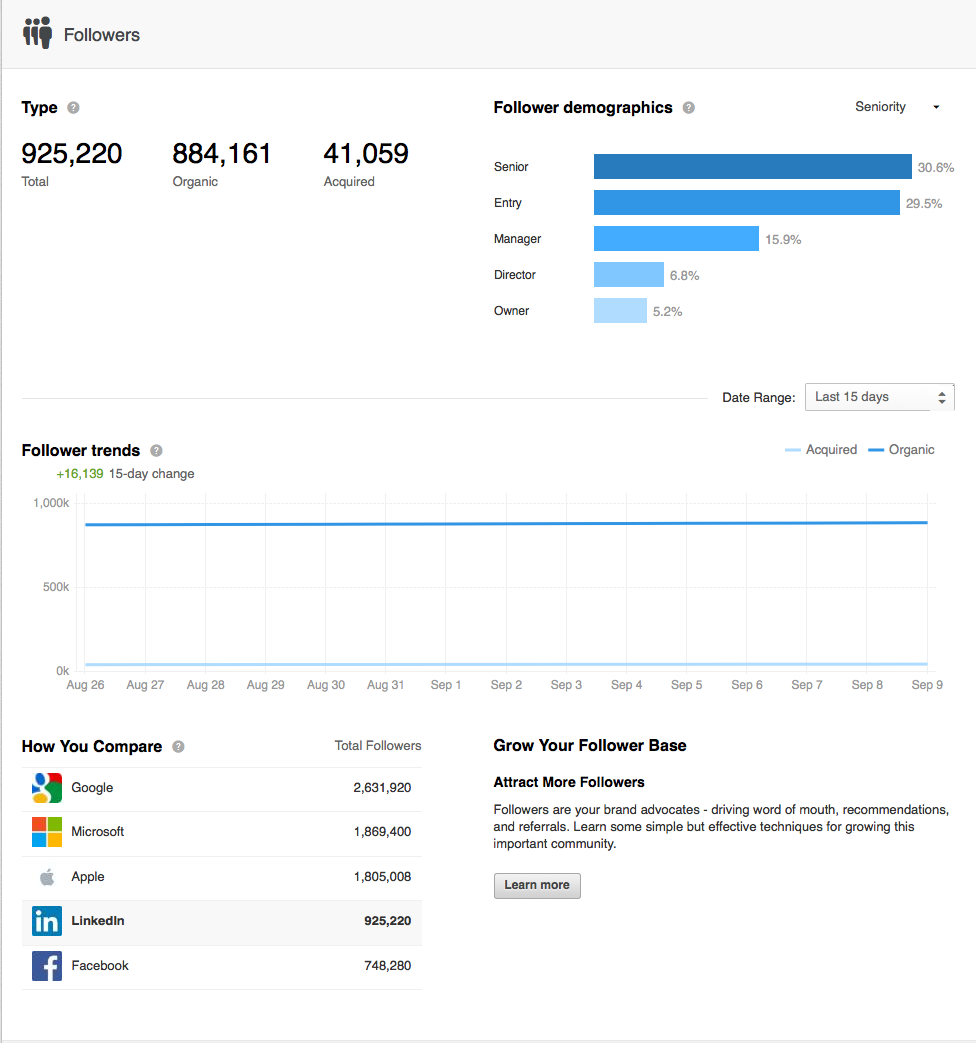
The above mentioned products are just a few examples and there are many more online products, such as 'Ads Reporting’, ‘Jobs Analytics’ etc., all powered by Pinot.
Internal Analytics Products
LinkedIn is a data driven company and product usage data is critical to the product management teams and they make decisions based on those insights. They require a powerful tool to analyze the data and Pinot is the infrastructure that supports it.
A/B Testing AnalyticsLinkedIn has built its own ‘A/B Testing framework’, and an important aspect of it is analytics. The framework uses Pinot to empower product managers to interact and understand how tests perform.
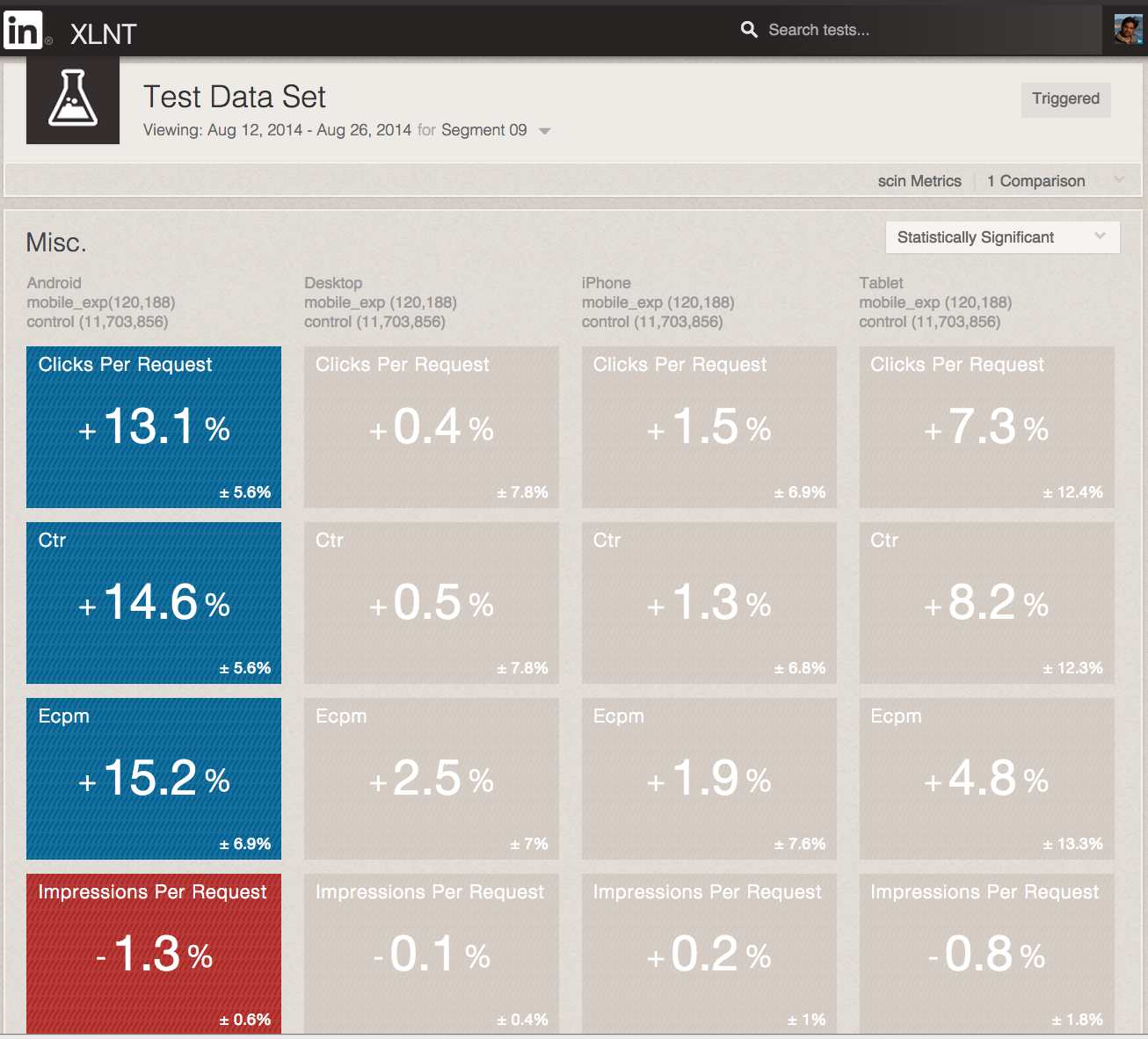
The Wall
Before Pinot, the analytics products at LinkedIn were built using generic storage systems like Oracle (RDBMS) and Voldemort (Key Value Storage), but these systems are not specialized for OLAP needs and the data volume at LinkedIn was growing exponentially in both breadth and depth. These, combined with widening needs across the company, required a single leverage-able system, which was the impetus for building Pinot.
We developed core Pinot features in an iterative fashion for about eight months before we could start using it for products. There were many challenges to deal with, some of which are highlighted here.
Low Latency and High QPS OLAP Queries with real-time ingestionBuilding analytics products for general users requires the infrastructure to support high read QPS with low latencies. This is very difficult to achieve if the data volume is huge and is one of the primary reasons we needed to build Pinot. For “Who’s Viewed Your Profile,” Pinot is able to serve thousands of requests while maintaining SLA in the order of 10’s of milliseconds.
Support Complex DimensionsWe needed to future proof Pinot to allow us to use any new dimensions without worrying about scale. Our systems need to scale to account for any new data that the product managers needed and be able to query on them in any way possible. In other words, we needed Pinot to scale to an arbitrary number of dimensions.
Operational SimplicityDealing with large volumes of data requires a distributed system and operating them at the scale of Linkedin’s data is not easy. But we wanted to keep the operational aspects of the infrastructure as simple as possible like cluster rebalancing, add/remove nodes, re-bootstrapping and so forth.
How Does Pinot Solve It?
At a high level, Pinot is a distributed system that supports columnar indexes with the ability to add new types of indexes.
Data IndexesLinkedIn data has a lot of depth and each dimension requires special treatment. We needed to build custom compression techniques to fit every dimension, in order to get optimal scan speed tradeoff vs. memory consumed. For example, each one of our members can have hundreds of skills and representing them per event is difficult. Similarly, groups that members belong to and companies they follow are some of the dimensions difficult to represent per event. We built Pinot with this difficult to index data in mind, but will save the details of the compression techniques for future posts.
Distributed SystemTo deal with such a large volume of data, we obviously needed a distributed system to parallelize the query processing. We decided to use Apache Helix, which was developed at LinkedIn for cluster management.
Data PipelinePinot needed to support real-time data indexing from Kafka and Hadoop to support the real-time needs of our products. We support the Hadoop pipeline for bootstrapping and reconciliation needs.
Below is a very high level architecture diagram.
How is Pinot used?
Just to compare the before and after Pinot world, ‘Jobs Analytics’ is a product built several years ago using Oracle, and the whole architecture was complex with many limitations. The below picture depicts the contrast and the ease that Pinot enables LinkedIn employees to build analytics products on top of the infrastructure without having to worry about complicated details.

| Near Real-time | We couldn’t support near real-time as the data has to be processed and compressed in Hadoop and then re-pushed to Oracle. | Pinot supports ingestion from Kafka for the near real-time needs and also Hadoop Pipeline for reconciliation and bootstrapping needs. |
| OLAP Queries | RDBMS is not the best choice for any OLAP style queries so features we could support were limited. The schema was complex and modeling this on RDBMS was fundamentally not right and we had to cut down on dimensions to scale. | Data modeling is primarily for OLAP style needs and can support complex dimensions for large datasets. |
| Data Retention | For OLAP products we need a way to expire data that is older than X days. So everyday we had to run a cron job to delete records. We knew this was not right. | Data is stored as data segments and segments are grouped by time period so data expiration was very seamless. |
We believe in building a developer community around Pinot to help take it to the next level and are evaluating turning it into an open source project.