Ranking live streams of data
October 17, 2011
There are over 1 million groups on LinkedIn and 1.5 million members join these groups every week. When working with this volume of data, we ran into an interesting problem: how can we rank group discussions so that the most "interesting" ones appear at the top? What algorithm could handle the huge stream of activity - new discussions, comments, likes, views, follows and shares - to produce a sort order that would work for active and inactive groups as well as active and inactive members?
Exponential moving averages
We knew discussions with more recent activity should rank higher, so we wanted velocity in the formula. Our first attempt was to use exponential moving averages. Take a look at the chart below: the blue and red lines represent two separate discussions. Each spike represents an "action" in the discussion, such as a comment or a like:
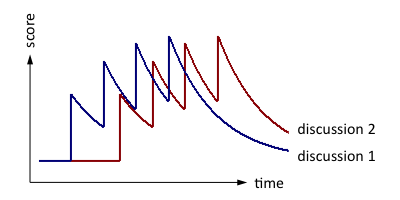
Using exponential moving averages to rank discussions
As time goes on, the score of each discussion decays. However, more recent actions get a higher score than actions in the past, so the red discussion gets a higher final score. It's something like velocity, and it also remembers old activity.
Unfortunately, this approach doesn't scale. Since scores should decay over time, you'd need to update the scores on every single discussion either (a) on a periodic basis, such as every 5 minutes or (b) every time an action is taken on any discussion, you update all other discussions in that group. Option (a) results in a sub-optimal user experience, as stale discussions stay near the top while the updating code runs. Option (b) requires lots of (costly) synchronization as simultaneous actions compete with each other to update the same discussions. Either way, you'd need to constantly update a huge amount of data, which places a large, unnecessary, and, worst of all, ever-growing write load on our systems.
A more scalable approach
Instead of decaying the scores of past actions, we decided to give more weight to current actions. For the same two discussions and four actions discussed above, the scores become:
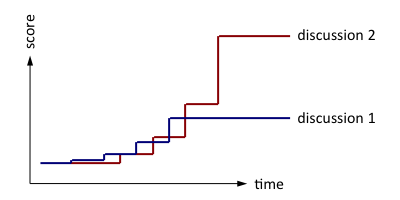
Give more weight to recent actions
A discussion's score doesn't decay with time; it remains constant when there's no activity. When an action occurs, you update the score of just one discussion, and then rank it compared to the old, unchanged scores of its competitors. The ranking comes out the same as with moving averages, and since far fewer writes are required, the algorithm is more scalable.
Unfortunately, now we have a different problem: the numbers get really big. As time goes by, the weight of a new action increases exponentially. For example, if the weight doubles daily, an event that scores 1 today would score 128 a week from now, 16,384 two weeks from now, about 1,000,000,000 a month from now and about 7.5 x 10109 a year from now.
Floating point arithmetic helps, but it runs out of gas eventually. We figured scores would overflow a Java double in about nine months, and overflow a number in our Oracle database about three months later. Although we could code our way around the Java limitation, the database limitation looked harder. If in ~12 months we were forced to change the storage system, we'd have to convert all existing scores while simultaneously processing new ones, and all without downtime (we don't shut down for maintenance, as a rule). We needed to get this one right from the start.
Working with big numbers
We thought about storing the printable form of numbers as strings in the database. Using scientific notation, we'd have plenty of room to grow. But we couldn't use the database to find, say, the top ten scores in a group. The database would sort the strings alphabetically, not numerically, so we'd get wrong answers like 10 < 2 (because the string "10" comes before "2" alphabetically). Was there a string format that would sort like the numbers, the same way UTF-8 byte strings sort the same as the characters they represent?
It was time to get help. We used our LinkedIn connections to get introductions to mathematicians and posted our question in LinkedIn groups devoted to mathematics. This sparked some creative thinking and lively discussions. In no time, somebody casually mentioned that some universal codes are lexically ordered. We could store a number in binary floating point, with the Levenshtein coding of the exponent followed by the fractional part of the significand. For example, here is how we would encode the number 14.25:
| 14.25 | 1110.01 | e.4 |
| In floating point: | 1.11001 x 23 | 1.c8 x 23 |
| Exponent: | 11 | 3 |
| Levenshtein coded exponent: | 1101 | d |
| Fractional part of significand: | 11001000 | c8 |
| String format: | dc8 |
You can see the gritty details and the code here.
The architecture
Our web servers send a stream of actions to a "scoring service" that updates scores and rankings in the database. Scores are stored as encoded strings, which are sorted to get the rankings. When a web server needs to show a summary, it calls the "groups service", which uses the cached ranking to put together the list of discussions. If the ranking isn't in the cache, the group service queries it from the database and caches it.
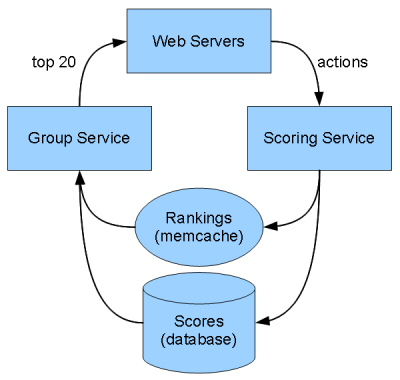
Ranking architecture
We launched this system using Java double for calculating scores. Six months later, we went back and replaced Java double with Apfloat, an awesome implementation of big numbers.
Today, the scoring service runs on a small cluster of 4 servers: at peak, we process 500 actions per second while utilizing less than 30% of the CPU.
Data storage
Here's some sample data from the database:
| 1 | 40a99db36b0f0336473 | 2 | bf563e5cbcbf6ae14028 | 0 | 0 |
| 2 | 40a9a7bd22e1d9037266 | 2 | bf5632a72f1833c17b98 | 3 | bf52fa22ae671d4484a8 |
| 3 | 40a9ada6f06efc7ac4e | 3 | bf56264be43599890cac | 1 | bf562ee03bdd3f85446c |
In decimal notation, those values are approximately:
| 1 | -1.02058819x10554 | 2 | 8.164705524x10548 | 0 | 0 |
| 2 | -3.096145439x10552 | 2 | 1.548072719x10547 | 3 | 1.005358555x10423 |
| 3 | -4.13625899x10551 | 3 | 1.897047639x10545 | 1 | 4.391925137x10546 |
A few tweaks
We changed the scoring formula a few times:
- We reduced the doubling time of velocity weights, to make 'flash in the pan' discussions drop down through the ranking faster. The transition took a little math: we changed the epoch and the doubling time simultaneously, so velocity weights accelerated smoothly, without an abrupt jump at transition time.
- The original formula included actions like viewing a discussion and sharing a discussion into another group. Members were puzzled and annoyed by the resulting rankings, since they couldn't see the activity that went into them. So we dropped the invisible actions out of the formula and recomputed all the scores in the database, which took a few days. Thank goodness we store counts and velocity for each type of action, so we had the data we needed. The rankings were a little off during this transition, but they all came out right in the end.
The ranking works pretty well. We know the system encourages members to visit their groups more frequently. As usual, we'll run with it until we think of something better - if you've got some ideas, let us know!