I'm excited to announce that we have released version 1.0.0 of SenseiDB to the open-source community. Sensei is a distributed, elastic, realtime, and semi-structured database.
Read on to learn more about what Sensei does, the architecture behind it, and the project's future direction.
What is Sensei?

Sensei is a distributed data system that was built to support many product initiatives at LinkedIn, including the real-time faceted search in Signal and the news feed and tabs on the Homepage. It is the foundation of LinkedIn's search and data infrastructure.
Sensei is both a search engine and a database. It is designed to query and navigate through documents that consist of (a) unstructured text and (b) well-formed and structured metadata.
Features
Some features and differentiators of Sensei:
- Ability to consume high insert/updates while maintaining high query performance.
- Support for complex queries via a query language (BQL) and a REST/JSON api.
- Streaming updates from different Gateways such as JDBC, JMS, and Kafka.
- Bootstrapping from Hadoop, e.g. Map-Reduce job to batch build index and push to Sensei clusters.
- Ability plug-in custom and complex faceting logic such as the social graph.
Architecture
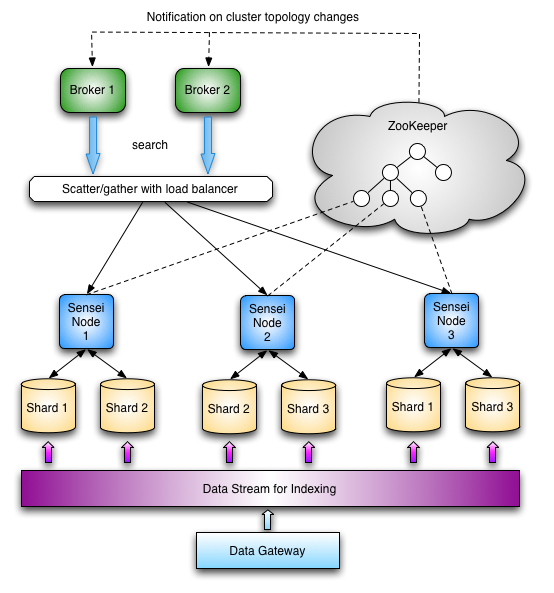
Inserts
Unlike many other data-systems, Sensei consumes data from an ordered and versioned data stream that we call a gateway. Within LinkedIn, some of the data streams consumed by Sensei include Kafka and Databus (a technology we use to stream data from a database).
Sensei relies on the external data stream for atomicity and isolation guarantees; in a way, the commit log is externalized. This design allows us to optimize for update rate while providing eventual consistency across replications without needing a quorum.
For more details, see the architecture overview page and the clustering page.
Queries
Sensei's execution engine is optimized for performance on very large datasets and supports a rich query feature set:
- get/getAll, e.g. a key-value retrieval
- full-text search
- structured, sql-like selects
- aggregation, e.g. facet counting and group-by
Along with a REST/JSON API, Sensei supports a SQL-like query language called BQL. Here's an example BQL query you can run against Sensei:
What Sensei is NOT
Some features Sensei does not support in comparison to other data-systems:
- Sensei is not relational. Like many other NoSQL systems, data is de-normalized and JOIN operations are not supported.
- Sensei is not transactional. We provide durability and eventual consistency guarantees but we do not support a full transactional insert model (e.g. roll-back)
Next play
Some future work we have in mind for Sensei:
- Relevance toolkit
- Support for aggregation and field collapsing
- Support for nested document structures
- Dynamic Schema
- Online data-rebalancing
- Data import/export
- Inter-cluster Map-Reduce support
Get involved!
To learn more and help drive Sensei forward, check-out the following:
- SenseiDB project page
- Source code
- LinkedIn group
- Mailing list
- IRC: irc.webchat.org, channel #senseidb